
In the past, many of our blog posts have started with “Intercom is a product company, …” It set the context for the reader, explained some of our decisions and defined the layer we bring most value in. I started this piece with it, but a brief pause was enough to realise it’s wrong. Scratch it.
Intercom is an AI company.
In this post we’ll discuss how we built tools to make our scientists productive at training modern AI models. Ones that require bigger, more expensive, harder to get GPUs, often running on the bleeding edge of the software stack. We’ll talk about our next-gen AI infrastructure, a different approach we took, as well as about failed tries in building a good experience, learnings, and some surprises along the way.
Trying out off-the-shelf solutions
When you think about AI infrastructure, the first thing that comes to mind are GPUs, CUDA, big datacenters and power management. Our journey of training our own models has started from a completely different angle. Instead of planning the exact GPU capacity, topology of our clusters, bandwidth between GPUs and nodes, we’ve started from the experience we wanted to give to our engineers and scientists.
Before we started training our models, M-based Macs were a great home for all our development. We have our great monolith, all parts of the codebase are easily accessible, and we heavily lean on interactive ways to develop software (yes, notebooks!). You just run ./script/update and you’re set to start building new exciting parts of Intercom.
Needing a GPU breaks that paradigm straight away. We really like that integrated development environment, but you can’t train (or even run) anything serious on Macs.
We run on AWS so it was cheap to try their product offering. We were early users of Sagemaker Notebooks and we used it to get GPU-powered instances. The experience was lukewarm at start – it was really nothing more than Jupyter Notebooks with GPUs, behind some authenticated proxy.
AWS launched Studio to replace Notebooks, which was a positive change. They even rebuilt it twice from scratch, each iteration being significantly better than ones before. Storage improved, stability improved, but it’s never been quite there. For instance, not being able to “SSH in” meant that scientists were not able to use their favorite IDEs. It was just about acceptable for a while (since AWS provided VSCode in the browser), but the rise of AI IDEs like Cursor showed us that using VSCode in the browser was leaving a lot of productivity on the floor.
Run Less Software runs deep in our culture and it was difficult to shake off the feeling that we should just try a bit harder to make it work for us. And we’ve tried hard to make it work. We’ve used all sorts of tricks to allow some sort of SSH connection, bringing it closer to where we wanted it to be. But we saw engineers jumping back to their Macs as soon as they could, using remote machines only when necessary.
These jumps were painful (data transfer, unexpected capacity issues without ability to change Availability Zone etc.) and it was hard to maintain the remote setup because engineers were spending very little time using it. Feedback was coming sparsely, and was always urgent because many issues were blocking them from working. As the team grew, this half-hacked experience was becoming more expensive for everybody and hindering our ability to move fast. We needed something better.
Our take at it
We’ve set a goal to have a dev environment that’s as seamless as the one on Macs, but with GPUs attached. We want scientists to just develop features and think about datasets and training techniques. We do want to let them know about layers like Kubernetes, Slurm, and NCCL as late as possible (hopefully only when they have to innovate on that layer).
The vision was there, but the deadline was tight – we had around two weeks to give people some infra to start training models.
We knew we couldn’t build some big AI infra from scratch and we had no option but to cheat. It was clear that the team wanted to start with smaller models, whose training runs fit into one node. For these cases, we were sure we could provide a good dev experience and make it feel like it’s running on Mac with more power.
We’ve made several decisions that now seem pivotal:
- Create a CLI tool for managing anything related to AI infra.
- Split the training infra and experience for small and big models.
- Build on top of some more flexible platform so its constraints are not preventing us from providing a good experience.
We started by developing a CLI tool we called ai-infra. To be honest, we didn’t anticipate it would become so central to our AI dev infra. We imagined it only as a central place for basic create/start/stop actions on servers with GPUs, but it ended up integrating deep in scientists’ workflows, offering help across all stages of the model’s lifecycle:
We created a single, easily installable and maintained python package. It enabled us to improve all the small parts of the developer experience that were causing enough friction to be annoying, but none of them annoying enough to automate the fix. Suddenly all the tricks, fixes and code snippets shared around random docs got home and could be run automatically, often without scientists even knowing, just when they’re setting up their user/workspace.
We can now set up their SSH to make sure GitHub keys are forwarded, we can transfer their git config, shell setups, make sure tools like nvitop work out of the box, make sure uv is set-up so they can install GPU packages without compilation. Having this “central” CLI tool enabled us to do all that, but also to cut through a million of AWS clicks and APIs that are hard to use through AWS CLI. You want to create a new instance? No problem, ai-infra create will create one for you, install our big monorepo (with a few example kernels/vens) and make sure your remote machine feels like your Mac. You want to find pricing and purchase some machine for the future? No problem, just use ai-infra find-capacity. How about spinning up an efficient server for the model you just trained so you can run some evals? ai-infra serve <model_path> will do it for you. Need a hosted MLFlow instance? You don’t have to go to AWS Console and click ten times, just run ai-infra mlflow.
Here’s how creating a new instance looks:
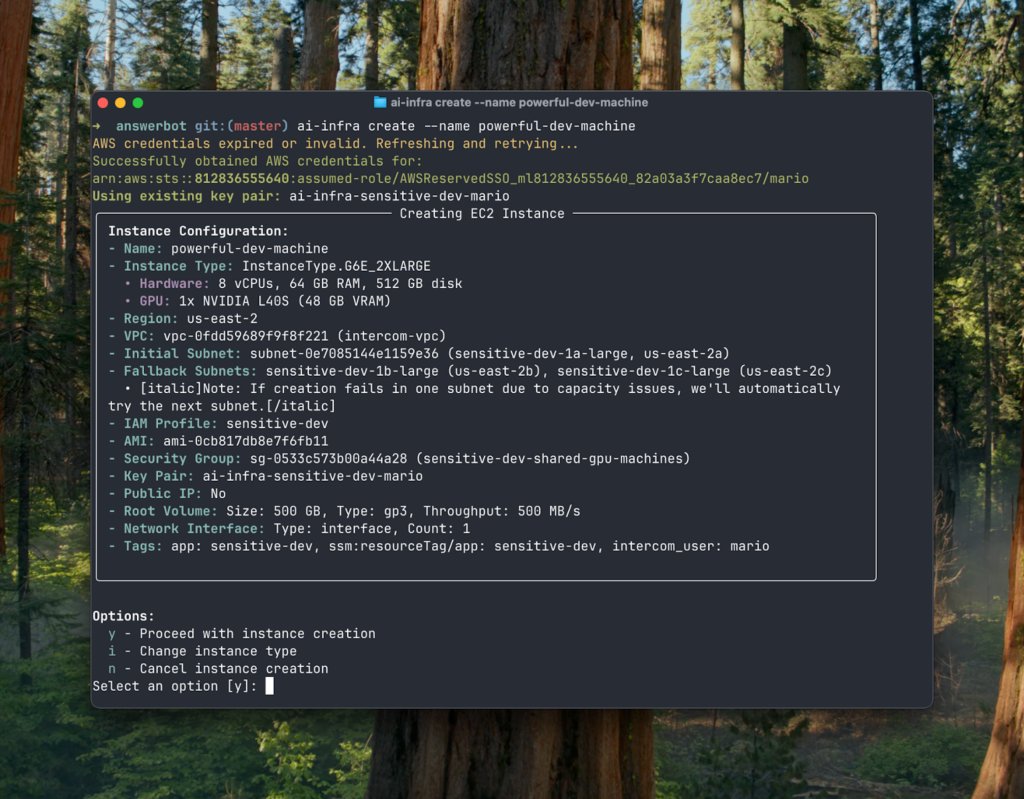
Right now, it takes eight minutes (we want to make it five, then three) from running ai-infra create to being able to run ai-infra cursor and get Cursor to ssh into your new instance, with all the packages installed and having different virtual envs easily bootstrapped from several recipes we give to people.
It takes the same eight minutes from needing a GPU machine to getting one (sort of, more on that later) and working on it. But you probably already have one that’s been running since the day before.
I’m still surprised with the power of hands-off experience we achieved just by gluing things together, removing confirmation prompts, automating clicking through AWS console, skipping authentication screens, recognising best serving software stacks for the just trained model etc.
There’s nothing smart there, just the wish for a very good dev experience and Claude Code that generated 98%+ of the 10k lines the tool currently holds.
Here’s how it came to be
We asked our scientists and engineers about what kind of setup would feel most natural to them for working with GPUs, and what didn’t work well with previous setups. The major piece of feedback we got was that they wanted to use their IDE with their extensions, having access to the real terminal, trying out things quickly, letting files stay there after restarts etc. AWS Sagemaker eventually built out most of it, but it was still inflexible in opaque in terms of infrastructure placement and capacity management.
All these were pointing to something persistent with an SSH access. We knew we wanted a platform more flexible than SageMaker so we can iterate quickly and don’t have to work around constraints all the time. We have a good bit of experience with EC2 so the choice was obvious – plain EC2 with Ubuntu DLAMI. We get all devices set up and we’re ready to start with our layers of software the moment a new instance boots.
ai-infra glue is really necessary to make it all work. Actually, any glue like that will be a great experience for engineers, as now they won’t be forced to stitch many parts themselves and make decisions they don’t actually care about.
Some of the lessons learned
Splitting the training between small and big models
Why did we think it was a good idea? First of all, our hand was forced by a short deadline, but we also weren’t sure that we could provide a great user experience if we make training all types of models unified.
The basic case is pretty simple: as long as your needs fit into one node (which NVIDIA is happily making more powerful), we have an answer for a good dev experience. Once that’s not true, all sorts of tradeoffs and technical questions start to kick in:
- How do you share the data between them?
- How do you iterate on your code?
- How do you install deps remotely?
- Do you use docker?
- Do you build everything into an image or not?
- Do you build ssh-ing into nodes into the core part of the experience?
- Do you offload some of these decisions to the user?
Whatever avenues you take, it’ll be hard to beat the ease of experience of ssh-ing in with Cursor. We have been working on it for some time, using Slurm, experimenting with EKS, but I can’t say we’re providing the experience we’d like. We still need to pair scientists with infra engineers who are very familiar with the setup, to take shortcuts and iterate quickly.
This confirms that the early split we made was a good one, and it enabled us to provide a great experience at least for smaller training runs.
Securing GPU capacity
Intercom is a cloud-native company and we have no prior experience managing assets like servers in the datacenters, planning for the network capacity etc. We are happily used to EC2 API calls booting machines within three minutes and adding compute capacity to our clusters. It was quite a shock to find out that it just doesn’t work like that with servers that have GPUs! Yes, you will still boot these machines with an API call, but only after you buy it upfront for a fixed period of time in the future, or talk to your account manager and sort it out some other way.
Also, the capacity elasticity takes a very different form. GPUs are such a precious resource that you shouldn’t count on cloud providers giving more of them to you when your demand goes up during the day. Not without talking a lot with the seller upfront, at least. It was painful to discover that it’s true even for smaller GPUs like L40/L40S and that all kinds of GPUs are in short supply. Most cloud providers will tell you that there is on-demand capacity, but our observations is that information can be stale the next day and you really need to reserve the capacity that you need to count on.
Instead, treat your GPU capacity as an asset that’s hard to buy and sell. That means that you can change the “inventory” infrequently and the investment is shifting to finding ways to use it as much as you can instead. Unfortunately, this shapes the experience of working with it. Nightly async batch jobs are not as nice as interactive development, but they are useful in the age of GPU shortage.
The future of our AI infrastructure
We know this is only the first version of our AI infrastructure. It’s very early, but it already enabled us to move quickly and improve Fin in only a few weeks.
We took some shortcuts that we want to fix in the long term. There’s a vision of unifying training small and big models, backtesting them and running them in production. It’s blurry, but it’s there, and each training run brings more clarity.



