
When users ask Fin some question, they expect Fin to respond in the same language in which they ask the question. Detecting the language a user is speaking is a key step in the Fin pipeline. If we detect the wrong language, Fin might respond in a language the user doesn’t understand – leading to a poor (and often frustrating) experience. In this blog, we look at why language detection is tricky, why it needs to be better, and how we’re solving it.
Why do we need language detection?
On the surface, the problem looks simple: Fin needs to reply in the same language the user is using. Can’t we just do prompt engineering, like below?
You are customer support agent. You need to answer customer's question. Reply in the language they asked the question.
History:
Fin: Hey There, How can I help you?
Customer: Hey, im need help.
...
Reply:
(Fin generates a reply in the user’s language)But here’s the catch: while large language models can reply in virtually any language, most Fin customers have human agents who speak only a few. That means Fin can only support a few languages per customer. Basically, customers want control over the languages that Fin responds in (they want the ability to constrain it to only languages that they give it permission to).
Consider a hypothetical setup of Fin by AlpNet Communications, a telecom operator based in Switzerland. They’ve set English as the default language for their Fin workspace and enabled support for German, French, and Italian (the country’s official languages). So far, so good: if a customer writes in French, Fin replies in French; if they use Italian, Fin responds in Italian.
But what happens when someone messages in Dutch? Technically, Fin can reply in Dutch, but it shouldn’t, as the customer has “prevented” it from happening. AlpNet doesn’t support that language, and chances are, their agents can’t either. This is where fallback logic comes.
First, Fin checks whether the user’s language is supported. If it’s not, it looks at the user’s browser locale. If the locale is also unsupported, say it’s Dutch, Fin falls back to English, the workspace’s default.
You could try to encode all that logic directly into a single prompt, but that quickly gets messy. A better approach is to handle the decision-making upstream and keep the prompt simple. This upstream logic itself can be handled by a separate LLM call, like below
Determine the language the user is writing in this message:
User: Hey, im need help.
AI: <detected_language>That helps, but extra LLM calls slows things down, and we want Fin to be fast. What if we use lighter models, trained for just one job: detecting language?
How do we do language detection?
We used FastText in production to detect the language. FastText…
- …is commercially available and is Open Source (CC-BY-SA licensed)
- …trained on a large corpus of 176 languages (data from Wikipedia, Tatoeba and SETimes)
- …is FAST (takes 10s of microseconds on CPU)
- …and is more accurate compared to the other models like Google’s CLD3 and langdetect
FastText predicts the chances that a piece of text belongs to one of the 176 languages. For example, given the text Comment ça va?, FastText says there’s a 95% chance it’s French. The remaining 5% is spread across the other 175 languages.
However, we’ve encountered issues with FastText in real-world use. The model was trained on clean, well-structured text, but Fin users often type in a more casual, imperfect way. Spelling errors and missing accents are common. Unfortunately, even minor deviations can significantly impact FastText’s predictions. For example, removing the cedilla in Comment ca va? drops the French confidence from 95% to 68%.
FastText also struggles with short inputs or when the script doesn’t match the language. Here are a few examples where it misclassifies the language:
| Input Text | Correct Language | FastText Detection | FastText Confidence |
|---|---|---|---|
| im need help | English | German | 92% |
| im julia | English | German | 99% |
| buenas dias | Spanish | Portuguese | 70% |
| How to compute csat? | English | Hungarian | 77% |
| App store? | English | Italian | 88% |
| aap kaise ho? | Hindi | Finnish | 68% |
To stay on the side of caution, we predict the language only if the confidence crosses a certain threshold. Unfortunately, we have observed that this too leads to many cases like below where we don’t predict the language, and often a different language gets used in fallback than the one that the user messaged.
| Input Text | Detected Language | Confidence |
|---|---|---|
| combien coute le pass eleve | French | 47% |
| how can i write a query? | English | 69% |
| kontingentregel zuweisen | German | 51% |
Why is language detection hard?
There are many challenges a real-life language detector has to solve. Here are some of them:
- Spelling mistakes – The model has to handle typos and bad grammar
- Short context – Many messages are short (like ok, si, da, or greetings)
- Ambiguous messages – Many messages are just email addresses or identifiers
- Mutual intelligibility – Some languages are very similar, like Hindi and Urdu, or Spanish and Portuguese
- Script mismatch – Some users type in Latin script instead of their native script (like Bangla, Armenian, or Hindi)
- Code switch – It is not uncommon to have multiple languages in a single message (e.g., 如何配置help center? )
- Long tail – Most languages don’t have enough training data to teach the model fine details
Our solution
A key limitation of FastText lies in its simplicity. It represents a text input by averaging the vectors of its subwords and then applies a linear classifier to make predictions. While efficient and effective for many tasks, this approach lacks the capacity to capture complex contextual relationships. In contrast, transformer-based models like BERT have been shown to consistently outperform simpler models like FastText across a wide range of benchmarks. We believe that we can do better than FastText by training a BERT-like language model on carefully curated data. Towards that, we’ve curated both general and Fin-specific data for the 45 languages1 we support, and trained our in-house language detection model. We use the general data to pre-train the language detection model for better generalization, and then fine-tune the model on Fin-specific data.
General Data: this is a subset of FineWeb2 – an 18TB dataset with content from about 1800 language-script combinations. We curated around 800K labeled text examples. Since FineWeb2 includes multiple scripts per language, it helps solve the script mismatch problem.
Fin-Specific Data: we collected this from random user conversations with Fin2. We used an LLM to identify the true language for each chat. If a message was too ambiguous, the LLM was told not to guess the language. We collected about 100K labeled conversations.
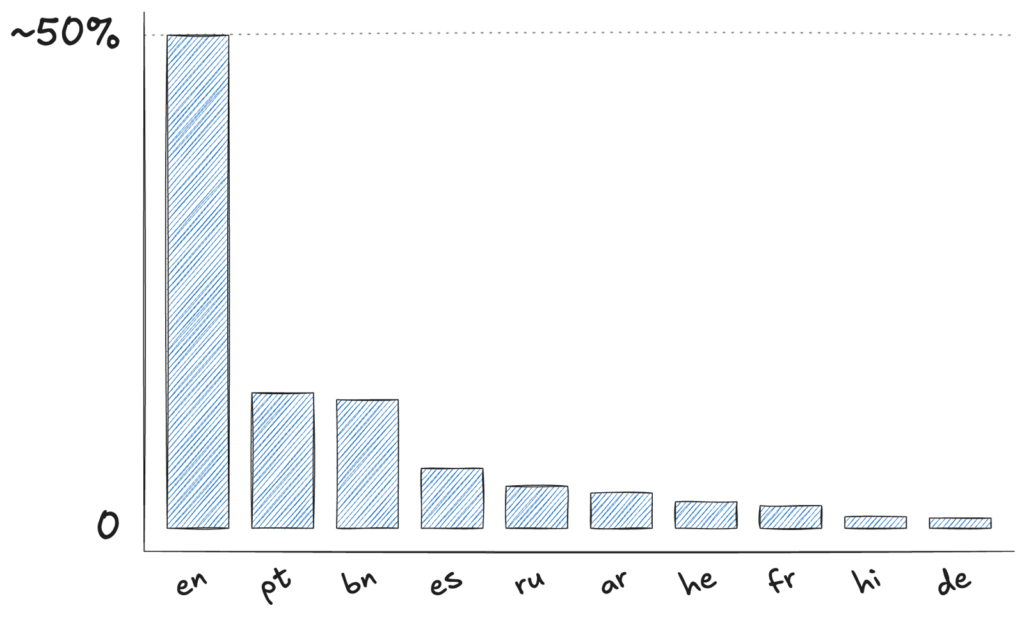
A problem with randomly sampling Fin chats is that around 50% samples are in English, and the top few languages make up 90% of the data (see figure below). That means many tail languages only had 100-200 examples. To fix this, we randomly translated some English messages into each tail language to increase their volume. After this, every language has at least 2K examples3.
We experimented with two models from the BERT family:
- DistilBERT Multilingual (135M parameters, Apache-2 licensed)
- XLM RoBERTa (280M parameters, MIT licensed)
We chose them as our base models because they are pre-trained on around 100 languages for general language modelling. So they already have some understanding of multilingual content.. First, we added a classification head to each base model and trained the model end-to-end on 800K examples from FineWeb2 for three epochs. Then we fine-tuned these models on Intercom’s data using lower temperature.
Evaluation
Offline Evaluation
We have a held-out test set of about 6K LLM labelled examples4. This data was collected similar to the Fin-specific training data described above. We measure the goodness of the model on the following metrics:
- Precision: when the model says it’s (e.g.) English, how often is it really English?
- Recall: of all actual (e.g.) English texts, how many did the model find?
- F1 Score: single metric that combines precision and recall
For all the metrics we report Macro Average (all languages are treated equally), and weighted average (weighted by number of samples in each language):
| Corpus | Macro Precision | Macro Recall | Macro F1 | Weighted Precision | Weighted Recall | Weighted F1 |
|---|---|---|---|---|---|---|
| Lingua | 81.83 | 81.82 | 80.14 | 85.31 | 84.94 | 83.27 |
| FastText | 85.60 | 79.93 | 80.15 | 86.65 | 83.36 | 82.44 |
| DistilBERT | 92.17 | 87.16 | 88.45 | 92.77 | 91.63 | 91.36 |
| XLM RoBERTa | 93.12 | 88.59 | 89.81 | 94.14 | 93.28 | 93.09 |
Along with FastText(our current model), we also tested Lingua, because of its claimed good performance on short texts. We see that the BERT family is doing much better than Lingua and FastText across all the metrics. F1 scores (both macro and weighted) are approximately 10 percentage points higher than FastText. Between DistilBERT and XLM-RoBERTa, the XLM-RoBERTa’s F1 is about 1.5pp higher than the DistilBERT.
In Production
We ran the RoBERTa-based language detection model in an A/B test, with FastText as the control. The new model made 6pp more predictions than FastText5. Just to make sure that we don’t use wrong language on these “extra” conversations, we checked a random sample of these extra predictions using an LLM as a judge, and found that the new model was >99% accurate on these predictions.
To further validate performance in production, we used an LLM to assess a random selection of conversations where both models would have made some prediction6. Both models achieved over 99% accuracy overall7. For each conversation, we simulated the output of the alternative model to identify disagreements. These occurred in fewer than 1% of cases. Notably, in those disagreements, RoBERTa outperformed FastText by a margin of 20pp in accuracy. As a final validation to the new model, since the full rollout of the RoBERTa model, we haven’t seen any issues reported by our customers related to wrong language detection.
Conclusion
Language detection is a deceptively complex problem, especially in a real-world product like Fin, where the language detector must balance accuracy, and recall across a diverse and noisy input space. FastText gave us a good starting point, but to go further, we needed better data and a model tailored to the kinds of messages Fin actually sees.
By developing our own in-house language detection model, we’ve unlocked a couple of key advantages: we can now support new languages more easily, and control precision and recall by training on additional data where needed. The gains in recall and coverage are already improving user experiences, and we’re set up to keep improving as Fin continues to grow.
- https://www.intercom.com/help/en/articles/8322387-use-fin-ai-agent-in-multiple-languages
↩︎ - We only use data from the apps that allow their data to be used for training ↩︎
- We verified the quality of these labels by computing accuracy on random 100 conversations per language using a separate LLM as a judge. The goal here is to just make sure that we don’t have noisy examples for any particular language. We did identify some bugs in our earlier prompts using this approach. ↩︎
- The dataset is mostly balanced (all but 8 languages have 200 examples, remaining languages have >= 40 examples) ↩︎
- Technically FastText made predictions, but with lower confidence ↩︎
- That is to say, on control bucket conversations we run RoBERTa, and in treatment bucket we ran FastText model ↩︎
- This apparent disconnect between offline and production could be because the offline dataset is balanced across the languages we support. ↩︎



