
Good answers start with good context. Our AI agents use retrieval-augmented generation (RAG) to find the right context for a user’s query. RAG retrieves top passages from a knowledge base, then uses them to generate an answer.
A key part of this process is reranking, which reorders the results from vector search so the final answer is grounded on the most relevant passages. Open-source cross encoder models are a popular choice for this because they are fast and easy to use. But in our experience, they don’t hit the quality bar we need.
In this post we share how we deployed an LLM-based reranker and the engineering needed to make it 5x faster while staying reliable on production traffic. We also show how we’ve applied it in our Fin and Copilot Agents and reveal the prompt we used. LLM reranker also guided the training of a custom reranker for Fin, which we describe in a companion post.
The Core Idea
Vector search returns the top-\(K\) passages from the index based on the user’s query. The LLM reranker then scores these passages to decide which are most relevant.
There are three ways to prompt the LLM for reranking [arxiv]:
- Pointwise reranking: ask the LLM to rate how relevant each passage is on a scale from 1 to 10. Example output with passage ids:
[("id0", 6), ("id1", 10), ("id2", 5), ("id3", 10), ("id4", 4)] - Listwise reranking: ask the LLM to order the passages by relevance. Example output:
"id1" > "id3" > "id0" > "id5" > "id2" > "id4" - Pairwise reranking: build a ranking through pairwise comparisons, asking the model which of two passages (\(p_i\) or \(p_j\)) is more relevant to the query. If you implement the LLM as a comparator inside a sort, you typically need \(O(K \log K)\) or \(O(K^2)\) comparisons, making it the most expensive. Studies often find pairwise prompting best on quality, though at higher cost [arxiv].
We went with pointwise reranking since it gives clear scores that are easy to use and allows useful optimizations.

Now, if you’ve got a lot of passages (we use \(K\) = 40), the naive version runs into a few problems we saw in the first iterations:
- The number of output tokens becomes large, which hurts latency
- The LLM sometimes misformats output or mis-scores (duplicate ids, missing ids, etc.)
- The inputs get large: 40 passages × ~200 tokens is ~8k tokens just for the passages (this doesn’t include the prompt!)
- LLMs can also be sensitive to input’s order [arxiv] and show positional bias [arxiv]
We improved this by (a) reducing output tokens and (b) parallelizing the reranker.
Reducing output tokens
When cutting latency, reducing output tokens is a good first step: latency gain is roughly proportional to how much you cut.
We landed on two optimizations:
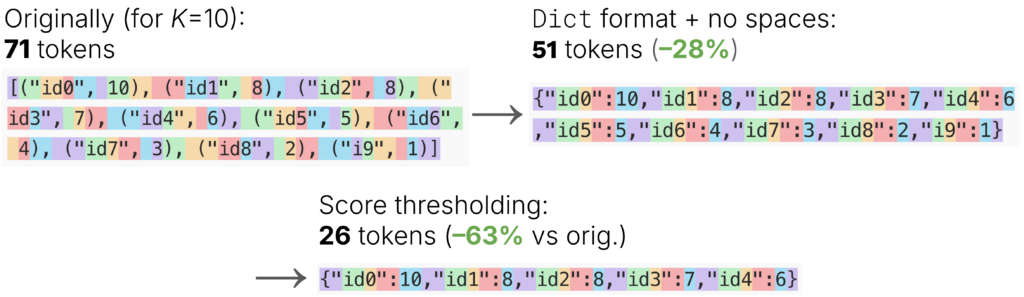
- Removed spaces (surprisingly expensive tokens!) and switched to a
Dictformat instead ofList[Tuple]. - Added thresholding: instructed the LLM to omit passage ids if their score is below 5.
The first change cut output tokens by ~28%, and the second brought another ~50% latency drop.
We also tried dropping the “id” token to save ~20% more latency, but it didn’t work. The LLM started confusing passage indexes with scores (both are integers in a similar range), so quality dropped.
Parallel Reranking
To improve both speed and accuracy, we split the \(K\) candidate passages into \(N\) batches and score them in parallel. For example, with \(K = 40\) and \(N = 4\), each worker gets 10 passages with the same prompt. This keeps inputs and outputs small, which improves speed and quality.
Batching strategy. Vector search already imposes an ordering bias (higher semantic similarity first). If you naively split passages into consecutive chunks, for example the first \(\frac{K}{N}\) for worker 1, the next \(\frac{K}{N}\) for worker 2, etc., you’ll overweight the first shard with the “best” candidates. We instead assign round-robin by index so each batch sees a similar mix of high/medium/low similarity passages: \(B_j = \{\, p_t \mid t \bmod N = j \,\}\). So with \(N=4\), the batches are \(B_0=\{p_0, p_4, \ldots\}\), \(B_1=\{p_1, p_5, \ldots\}\), and so on.
Merge step. We pool all scored items, sort by the LLM score, and use the BGE cross-encoder to break ties or fill missing scores.

Calibration. Parallelism comes with a consistency risk: workers run independently and may drift in how they grade. We address this by adding a clear grading rubric to the instructions and anchoring it with a small few-shot example set. This keeps all workers on the same scale so their scores stay comparable.
Latency & reliability. End-to-end latency is limited by the slowest worker, so we set tight per-call timeouts and skip retries to avoid long tails. If one call times out with probability \(p\), then with \(N\) parallel calls, the chance that at least one times out is roughly \(1 – (1 – p)^N\), which grows as \(N\) gets larger. This estimate is optimistic because it treats calls as independent, and in practice the failure rate increases under concurrent load.
If a shard does time out, we fall back by reranking that slice with the BGE cross-encoder and completing the request. We track timeout rates and tail latency (p95/p99) in dashboards.
Benefits. Parallelizing the LLM reranker improves performance:
- Smaller inputs per call let us run a faster, cheaper LLM without losing reranking accuracy.
- Latency improves because each worker handles a shorter prompt, produces a shorter output, and system prompt caching removes most of the fixed overhead.
- Round-robin batching evens out the positional bias across batches.
RAG in Copilot: Keeping Source Diversity
Unlike Fin, Copilot searches across more entity types, including internal content and past conversation history that aren’t user-facing. If treated as one pool, past conversation excerpts can dominate, making it harder to surface more authoritative content.
To fix this, Copilot retrieves by type, scores within type, then merges using heuristic rules that keep source diversity near the top of the RAG context. We use three parallel streams: internal content, public content that Copilot can cite, and conversation history.
Impact
Fin. Our first working setup of the LLM reranker added ~5 seconds of latency. After tightening the output format, enabling thresholding, adding prompt caching, and parallelizing calls, the added latency dropped to <1s, and costs fell ~8x.
- Latency P50: +0.9s
- In the A/B test against the open source BGE reranker, the LLM reranker showed a clear quality win, with a statistically significant uplift in resolution rate
Copilot. With entity-aware retrieval and the LLM reranker, we observed the following on A/B test against BGE reranker:
- Assistance rate: +3pp
- The answer rate: +2pp
- Cited conversation excerpts: –27%
- Citations of public + internal articles: +63%
Pointwise vs Listwise
We ran an A/B test comparing a listwise LLM reranker with our parallel pointwise setup. The listwise version scores all passages at once, so needs a stronger model.
We gave it a solid try, but it didn’t outperform the pointwise version: resolution rate was the same, but latency increased ~40% and cost ~15%, so there was no clear benefit.
Reflections
LLM-based reranking helped us significantly improve quality compared to open-source cross-encoders. It also gave us a simple way to confirm that reranking quality really does make a difference in practice.
That said, this approach comes with trade-offs. Even after optimizations, the added latency is still noticeable (+0.9s), and coordinating multiple LLM calls in parallel introduces complexity.
These challenges motivated us to train a custom reranker, with the LLM reranker acting as a teacher, so we could keep the quality while reducing latency.
The Prompt
We’re open-sourcing our prompt for the LLM reranker below:
You are a customer support answer service. Your task is to evaluate help center passages and score their relevance to a given customer query for a retrieval augmented generation (RAG) system.
Evaluation Process:
1. Analyze the customer's query to identify both explicit needs and implicit context including underlying user goals
2. Assess each passage's ability to directly resolve the query or provide substantive supporting information with actionable guidance
3. Score based on how effectively the passage addresses the query's core intent while considering potential interpretations
Grading Criteria:
<grading_scale>
10: EXCEPTIONAL match - Contains exact step-by-step instructions that perfectly match the query's specific scenario. Must include all required parameters/context and resolve the issue completely without any ambiguity. Reserved for definitive solutions that exactly mirror the user's described situation and require no interpretation.
9: NEAR-PERFECT solution - Contains all critical steps for resolution but may lack one minor non-essential detail. Addresses the precise query parameters with specialized information. Solution must be directly applicable without requiring adaptation or assumptions.
8: STRONG MATCH - Provides complete technical resolution through specific instructions, but may require simple logical inferences for full application. Covers all essential components but might need minor contextualization.
7: GOOD MATCH - Contains substantial relevant details that address core aspects of the query, but lacks one important element for complete resolution. Provides concrete guidance requiring some user interpretation.
6: PARTIAL match – General guidance on the right topic but lacks the specifics for direct application. May only resolve a subset of the request.
5: LIMITED relevance – Related context or approach, but indirect. Requires substantial effort to adapt to the user's exact need.
4: TANGENTIAL – Mentions related concepts/keywords with little practical connection to the request. Minimal actionable value.
3: VAGUE domain info – Talks about the general area but not the query's specifics. No concrete, actionable steps.
2: TOKEN overlap – Shares isolated terms without context or intent aligned to the request. Similarity is coincidental.
1: IRRELEVANT – Uses query terms in a completely unrelated way. No meaningful link to the user's goal.
0: UNRELATED – No thematic or contextual connection to the query at all.
</grading_scale>
Input Format:
<input_format>
<query>
// The customer's question or request
</query>
<passages>
<passage id='id0'>...</passage>
<passage id='id1'>...</passage>
...
</passages>
</input_format>
Output Format:
<output_format>
Return your response in a valid JSON (skip spaces):
{{"id0":score0,"id1":score1,...}}
Strict guidelines:
- Return ONLY a well-formed valid JSON with passage IDs as keys
- Each key must be a passage id in the format "idN"
- Each score must be an integer between 5 to 10. EXCLUDE passages that score below 5 (i.e. 0, 1, 2, 3 or 4)
- Integer values only, no decimals
- Skip spaces in the JSON
- No additional text or formatting
- Maintain original passage ID order
- Note: If NO passages score 5+, return empty JSON object
</output_format>
<examples>
{few_shot_examples}
</examples>
