
Are smaller fine-tuned LLMs competent for Intercom scale tasks?
Large Language Models (LLMs) are a powerful tech that have turned reasoning in natural language, into a service. They’ve had a huge impact on customer support, powering agents like Fin. Fin is already delivering real value, with many customers routinely experiencing resolution rates in the high 70s, and an overall average resolution rate across all customers of upwards of 60%.
Now that Fin is a mature product, we can start testing more ambitious ideas. One key hypothesis is that for narrow, well-scoped tasks, we might match the performance of much larger models by training smaller, more efficient ones, on enough high-quality data.
Fin primer
A part of Fin’s architecture builds on the RAG foundations to achieve an optimal experience for informational customer support use cases. This is built with components that try to understand the message exchanges with the end user and summarise the user’s problem, retrieve relevant information as passages, rerank them, and then generate an answer. The diagram below is a rough representation of how this flow works.
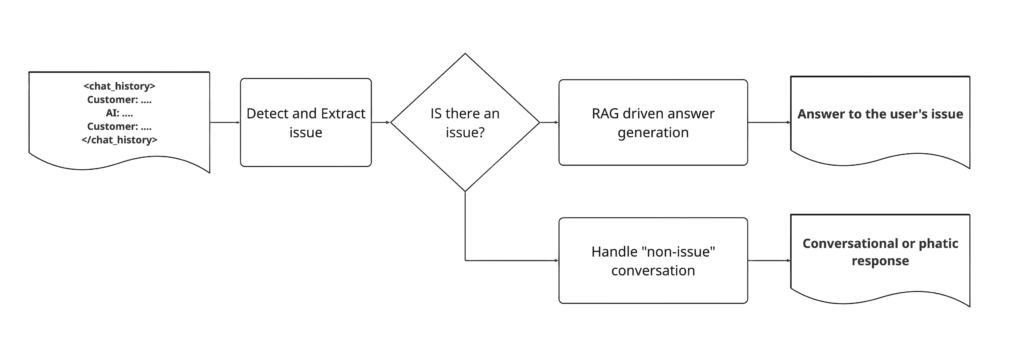
The goal here is to first focus on a well scoped, narrow task, that we could train a smaller LLM for: detect and extract the user’s issue.
Detect and extract issue summary
Issue detection and extraction is an important component of Fin’s RAG pipeline, where a series of messages between the end user and Fin are transformed into a single answerable summary issue, which is then used for the downstream retrieval pipeline.
The problem? Not all conversations have addressable issues. The old baseline setup used just one “issue detection and extraction” prompt: if there was no outstanding issue, it returned None.
But in reality, issue detection has lots of tricky edge cases, like:
- If a user gave negative feedback at the end, we want to catch it as non-informational, even if there’s still an outstanding issue.
- Users often mix feedback, greetings, or random noise with updates to their previous request, making intent hard to spot.
To deal with this, our prompt kept growing in order to cover for the nuances of non-issues – over 80 few-shot examples, >5k tokens of instructions, and 17 defined non-informational categories. A few categories of non-issue examples can be found in Table 1 below.
| Category | Examples |
|---|---|
| Greetings | “Hi”, “Hello”, “Good morning” |
| Goodbyes | “Bye”, “See you”, “Goodbye”, “That’s all” |
| Negative reactions (no new info) | “No”, “Useless”, “Not helpful”, “WTF” |
| Acknowledgments | “Ok”, “Got it”, “Understood”, “Makes sense” |
| Gratitude | “Thank you”, “Thanks”, “Thx”, “You’re the best” |
| Positive reactions | “Perfect”, “Awesome”, “Great”, “Cool” |
| Connection checks | “Are you there?”, “Are you still online?” |
| Pleasantries | “How are you?”, “What’s up?”, “Nice to meet you” |
| Small talk | “Nice weather”, “Merry Christmas!” |
| Meta-commentary | “That’s interesting”, “You’re fast” |
| Bot identity questions | “Who are you?”, “Am I talking to AI?” |
| Fillers & expressions | “hmmm”, “ummm”, “haha”, “lol”, “😂” |
| Testing | “test”, “testing”, “ping”, “hello world” |
| Gibberish | “asldkjfasldkjf”, “oompa loompa”, “123”, “aaa”, “…” |
| Thinking | “Let me think”, “One moment”, “brb” |
| Customer withdraws request | “Never mind”, “Don’t worry about it”, “Ignore that” |
| Indicating a question without stating it | “I have a question”, “Wait, I have something else” |
These nuances of issue detection made this prompt a prime candidate for experimenting with custom modelling. We can split the problem into two independent models, one that classifies an interaction as one with or without an issue, and another that extracts an issue if the first model thinks there is one.
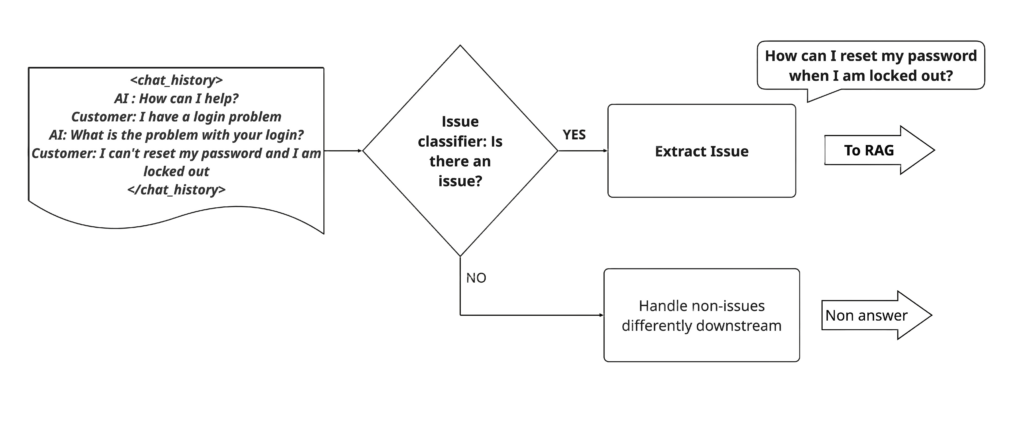
This split strategy now makes the issue extraction task on its own a narrow task, allowing us to experiment with fine-tuned LLMs.
How do we measure success?
Before we talk about the model training effort, we need to have a clear definition of what success looks like. Following metrics are the key indicators of Fin’s health and performance:
- Offline metrics: These metrics are measured by locally replaying a sample of Fin’s production requests via the new feature:
- Answer rates: This rate measures the fraction of times Fin was able to provide an answer for a real production query, when the new models were injected in the RAG process. Any large statistically significant drop in this number is an indicator of performance deterioration. However, a small change might not directly imply an actual degradation in production, which has been observed time and again.
- Semantic alignment: The fine‑tuned model should generate issues whose meaning closely matches the production issues extracted by the large LLMs. We quantify this by computing the distance (e.g., cosine similarity) between the embedding of the production issue and the embedding of the corresponding issue produced by the fine‑tuned model.
- Online Metrics: These metrics are measured via an A/B test in production:
- Resolution rates: This is the foundational metric that directly impacts Fin’s bottom line. No matter how good the model behaves offline, if it significantly deteriorates this metric, it is not a success. This metric can be split into
- Hard resolutions : Resolutions where the end user acknowledges that the answer actually solved the problem
- Soft resolutions: Resolutions where there is no explicit acknowledgement or positive feedback from the user.
- CSAT: Customer satisfaction (CSAT) score indicates the quality of what Fin provides.
- Latency: Latency has been an important metric to track for our product experience. We are constantly trying to bring this metric down, allowing end users to experience a seamless low latency interaction [5]. We want to make sure at the very least, this number remains the same.
- Resolution rates: This is the foundational metric that directly impacts Fin’s bottom line. No matter how good the model behaves offline, if it significantly deteriorates this metric, it is not a success. This metric can be split into
- Cost: Often talked about in terms of amortised cost per token generated, this metric is an important one to track, especially for custom fine-tuned models. A comparable online performance, but at 2x the cost is not a success.
Training an Issue classifier model
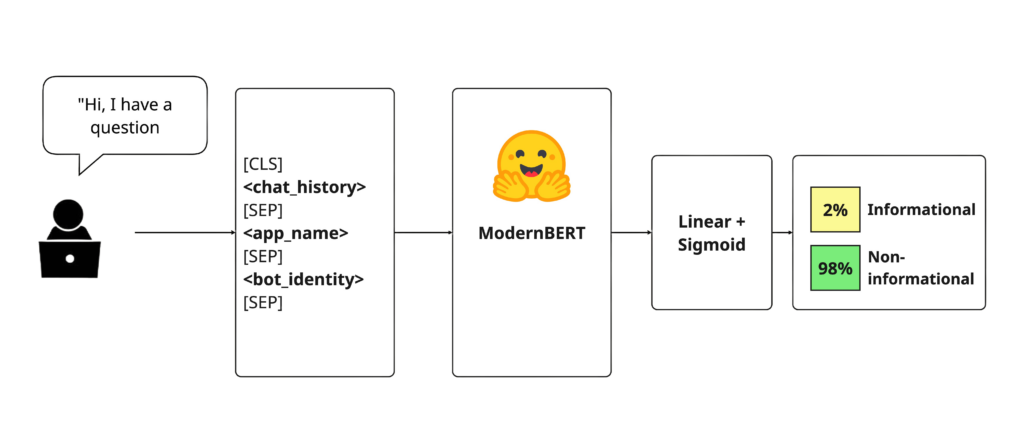
For our issue classifier, we started by curating training data from our original LLM-based system, which was designed to both detect and extract issues in conversations. Here’s what the new setup does:
- We encode an input with ModernBERT
- A simple linear layer with sigmoid predicts the binary label: informational or non-informational
- The model is trained with binary cross-entropy loss
ModernBERT is a newer flavor of encoder-only transformer based models, and it outperforms almost all BERT-like models on retrieval and classification tasks [4]. As you can see in our blogs on retrieval, reranker, parsing feedback and escalation detection. ModernBERT works really well for routing and classification tasks, once you fine tune it on the right data.
For the issue classification task, we trained the model on 1M examples and ModernBERT achieved a remarkable 0.995 AUC score. When ModernBERT’s results didn’t match the ground truth, it was mostly the teacher’s mistakes, not the student model’s.
Fine-tuning the issue extraction model
Finetuning a generative language model, implies taking an open sourced model –which is already trained on trillions of tokens from the internet, achieving a baseline level of performance on a diverse set of tasks – and changing its weights slightly to optimise for a particular task.
We use a specific way of fine tuning called Low-Rank Adapter(LoRA) [1][2] based tuning, which is an extremely parameter efficient way of finetuning language models. LoRA freezes the large model’s original weights and learns only two much smaller, low-rank matrices per targeted layer. This setup slashes trainable parameters by orders of magnitude while preserving quality.
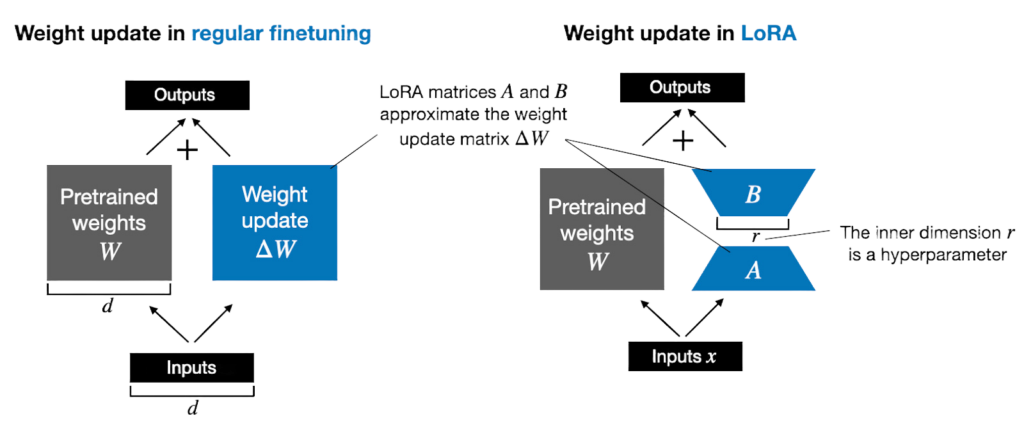
The blue blocks in the figure above visually describe what we actually train instead of the model weights (W). For each layer of the model, we inject two low rank matrices A and B, whose product can be added to the W once the training is complete. At train time, we optimize the weights of these two matrices instead of W itself.
A good introduction to LoRA can be found here. These LoRA adapters are like lego bricks which can be added or augmented to the original un-tuned model, to achieve an optimised performance for a specific task.
Data
We curate data from customers who have agreed with using their data for training.
The data is curated using the following conditions:
- Conversation must have happened within the past 2 months
- Customers with an account in the US, with conversation locale set as “English”1
- The conversation must have had an issue according to the older issue detection and extraction prompt.
The data is cleaned for obvious hygiene issues, and then anonymised by redacting any mention of emails, addresses, account numbers, phone numbers, names, places, organisations etc.
The resulting data contains 60 thousand training samples and 10 thousand validation samples.
Experiments
Before arriving at a final A/B testable model, we tested several variants of open source models, starting from a lightweight Gemma 8b, Qwen3 8b, finally getting a respectable result from Qwen3 14b variant. Some offline testing results are seen below:
| Model Name | Semantic Alignment | Answer Rate |
|---|---|---|
| OpenAI: GPT 4.1 (baseline) | N/A | 63.3% |
| Gemma 8b | 0.850 | 51.0% |
| Qwen 3 8b | 0.900 | 55.0% |
| Qwen 3 14b (only hard resolutions) | 0.930 | 36.4% |
| Qwen 3 14b | 0.938 | 63.4% |
The fine-tuned Qwen3 14b model seemed the most competent candidate out of all, performing at par with our baseline on answer rates. It is worth noting that we trained another variant of Qwen3 14b on just hard resolutions. The results were interesting to say the least, since despite learning to produce highly semantically aligned issues, the end to end answer rate performance was very poor. Upon closer examination, it seemed like the model only learned to produce an issue summary if the issue was extremely clear from the conversation, and refrained from producing any tokens when the conversation was ambiguous. This odd behaviour shows the importance of data curation in such projects.
Results
The A/B tests were done in two phases, since we have two tuned models active in tandem, instead of the incumbent 1 LLM call to the large model provider.
Issue Detector
We ran this A/B test before the Issue extractor model collecting enough data for statistically significant read out.
| Metric Name | Difference in Treatment |
|---|---|
| Answer rate | -0.5 percentage points (pp) |
| P50 latency | -100 ms |
| CSAT | 0 |
| Cost | -5% |
The results of the issue detector model were promising, with a slight decrease in answering rates, but almost no impact on other online metrics. However, since we are not using an LLM to do the more nuanced task of detecting whether there is an addressable issue or not, this also indirectly results in a 5% reduction in cost.
Issue Extractor
Once the issue detector was shipped to production we ran an A/B test with the winning candidate model as per the offline tests, for a week. This was enough to get enough data for statistically significant results.
| Metric Name | Difference in Treatment |
|---|---|
| Answer rate | -0.1pp |
| P50 latency | +100 ms |
| CSAT | 0 |
| Cost | -12.5% |
The overall answer rate dropped by 0.1pp. However, we saw no evidence of negative impact on other online metrics, except a slight 100 ms increase in P50 end-to-end latency. The biggest win here was the relative reduction in cost per transaction of 12.5%.
Discussion and Conclusion
The fine-tuned models delivered substantial reduction in costs, while being competitive with state of the art models for this particular task of issue detection and extraction. We are seeing three distinct qualitative impacts on Fin’s performance
- The Issue summarizer model can now focus only on summarizing issues, making the prompt much shorter. This decoupling of detection from extraction also stabilizes the prompt, as we now don’t need to keep adding examples of non-issues.
- The new issue detection model is much more precise, removing inauthentic soft resolutions. It handles edge cases much better and makes fewer hallucinations in simple cases.
- The issue detector gives a probability for an issue, so we can tune exactly how many informational vs non-informational queries we want, just by tweaking the threshold. You can’t get this kind of control with vendor hosted LLMs, like the ones from OpenAI or Anthropic.
While the newer approach with a smaller fine-tuned 14B LLM is significantly cheaper per transaction, there might be some more gains to be had in terms of impact on resolutions with further iterations. There are currently two running hypotheses to explore.
Impact of anonymisation: Protecting customer trust is paramount for us. Since generative models are generating tokens, training on customer data means taking utmost care to anonymise PII. To that end, in this first attempt we took an extra conservative approach by redacting every PII entity. There is a chance that this approach has negatively impacted the performance of the fine-tuned LLMs in the wild, because we are redacting important contexts at training time. We plan to improve on this approach and build a secure yet performant anonymisation strategy, with contextual replacement of PIIs instead of just redaction.
Impact of model size: The goal here was to find an optimally sized model that is light enough to minimise training/inference cost/infra, but large enough to be able to adapt to the task’s complexity. The 14B model was the first feasible model that we found to be competent in offline tests, and hence progressed towards an A/B test. However, research does suggest that a model’s competency to solve complex tasks scales with model parameter size [6]. Therefore, we think that it is definitely worth exploring larger models for such tasks.
In conclusion, this exercise provides a great evidence for deploying fine-tuned models for Intercom scale tasks.
Citations
[1] https://arxiv.org/pdf/2106.09685
[2] https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
[3] https://en.wikipedia.org/wiki/Rank_(linear_algebra)
[4] https://arxiv.org/pdf/2412.13663
[5] https://fin.ai/research/does-slower-seem-smarter-rethinking-latency-in-ai-agents/
[6] https://arxiv.org/pdf/2001.08361
Appendix: Are fine-tuned models learning a new skill?
While offline and online performance of these tuned language models do suggest that there is a lot of value in going through the fine-tuning process, one might ask: What is an unequivocal sign that the fine-tuning process is improving the model’s performance at a specific task, when compared against the original off-the-shelf base model. After all, the original off-the-shelf base model is also trained on trillions of tokens from the internet, and may contain the intrinsic intelligence to solve the task out of the box.
The most obvious way is to compare the offline metrics before and after fine-tuning:
| Model Name | Semantic Alignment | Answer Rate |
|---|---|---|
| Qwen 3 14B base | 0.780 | 18.0% |
| Qwen 3 14B fine-tuned | 0.938 | 63.4% |
We see that both average semantic alignment and answer rates take a massive hit while using off the shelf base model. Particularly the answer rate drop shows that the off-the-shelf model lacks the competency to extract usable queries for the Fin’s RAG pipeline.
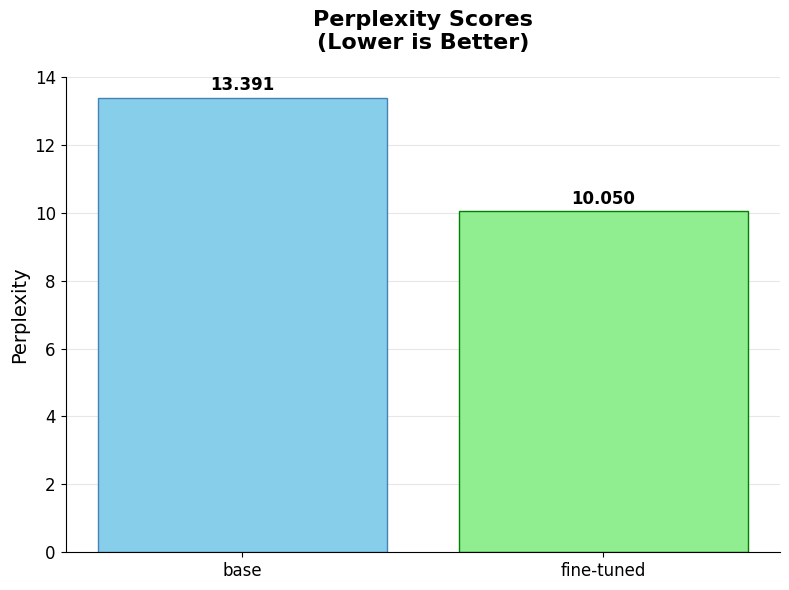
Average Perplexity computed on the generated tokens for the issue extraction task. Lower perplexity implies that the model is more sure of the tokens it generates for the same input context.
Another definitive sign of learning is a metric which is directly linked to the model’s loss that is optimized at training time. This metric is called perplexity.
All LLMs are trying to predict the next token, given all the tokens they have seen till that point in time. The way this is done is by predicting a vector of probabilities over all the tokens in their vocabulary, and then choosing the next token based on those probabilities. The way these models learn is by optimising these probabilities using a specific loss function called the cross entropy loss. Perplexity just averaged exponentiated cross entropy, progressively computed over all the generated tokens, given the model has seen the input context (in this case the anonymised chat history).
$$
\text{Perplexity}(T)=\exp\left(-\frac{1}{N}
\sum_{i=1}^{N}\log p \bigl(t_i \mid t_{<i}\bigr)\right)
$$
The perplexity metric quantifies how much the model is surprised by seeing the next token ti, given it has seen all the previous tokens t<i. When we evaluate this metric on the generated tokens for off-the-shelf Qwen 3 14B base model and for the LoRA fine-tuned models, we see that the fine-tuned model shows substantially lower perplexity on the generated tokens. Both these results indeed confirm that fine-tuning models helps them acquire competency in specific tasks.
- English is the most represented language with Fin, comprising about 80% of our traffic. Limiting to English language further narrows the problem, and controls for performance issues due to imbalanced language representation. We plan to explore multi-lingual in the future ↩︎

