
One of Fin AI Agent’s most critical tasks is deciding when to escalate customer interactions to human support. This challenge has only grown as Fin has become more conversational, and now most escalations happen through natural language, not Talk to a person 👤 button.
Get this wrong, and you either flood support teams with unnecessary escalations or leave users stuck without human help. This decision needs to be both fast and very accurate.
Today, we’re sharing how we built a custom multi-task model for escalation routing, achieving >98% escalation accuracy, reducing latency, and increasing resolution rate.
Understanding the Escalation Challenge
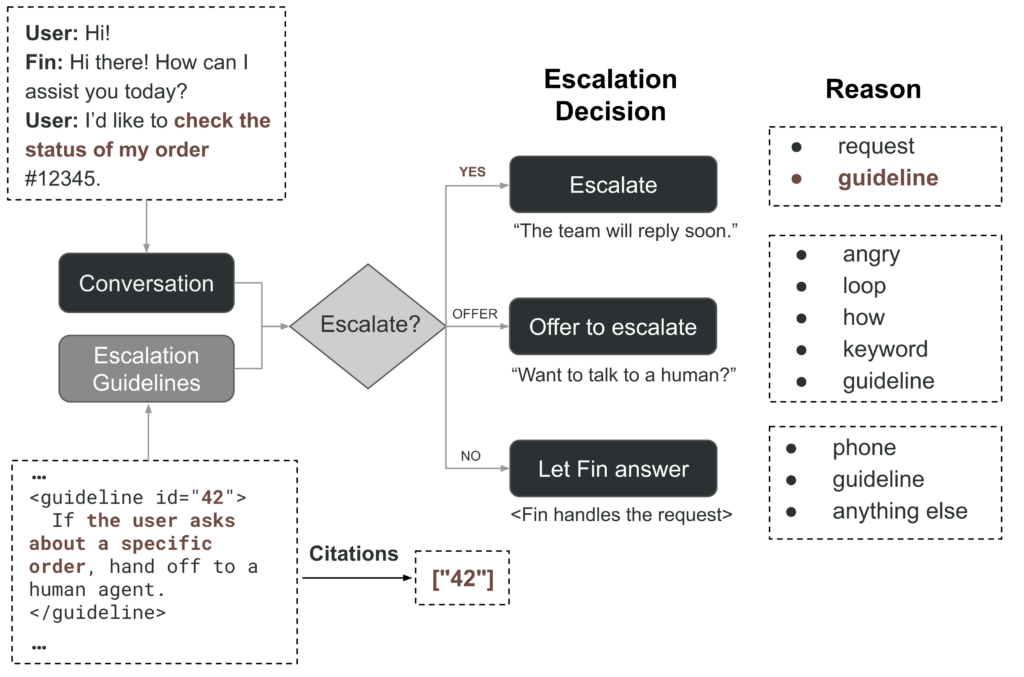
Whenever a user interacts with Fin, our system needs to make a real-time, three-way decision:
- Escalate immediately – Hand off to a human agent or trigger the custom escalation workflow
- Offer to escalate – Ask the user if they’d like to talk to a human
- Let Fin answer – Continue the AI-powered conversation
This decision is informed by two key inputs: the conversation history and business-defined escalation guidelines. These guidelines are rules that businesses configure, such as “Escalate immediately if the user expresses anger about billing”.
The system must also provide reasoning for its decisions. When escalating due to a guideline match, we cite the specific guideline. Internally, we also log broader categories like angry, request, or guideline.
For example, if a user writes “I’d like to check the status of my order #12345” and there’s a guideline saying “If the user asks about a specific order, hand off to a human agent”, the router would escalate right away, cite the guideline ID, and mark the reason as “guideline”.
Starting Point: LLM-Based Routing
Our first setup used a large language model (LLM) to decide: should we escalate, what’s the reason, and which guidelines matched. We also added guardrails to avoid edge cases like offering escalation twice in a row or escalating on the very first user message, unless there’s a guideline explicitly allowing it.
While it worked well, the LLM-based approach had limitations around latency and how much control we had over decision thresholds.
Attempt 1: Fine-Tuning Smaller LLMs
We first tried replacing our LLM with fine-tuned models. We experimented with Gemma and Qwen models of various sizes, training on 100,000 multilingual examples labeled with LLM outputs. This approach achieved solid 97% escalation accuracy, proving that custom models could compete with our LLM baseline.
At the same time, we saw excellent results with encoder-based models on other tasks like issue classification and reranking, which made us curious about using them for escalation routing too. Encoder models looked promising for faster inference and more reliable predictions.
Attempt 2: Classification Without Guidelines
Our next approach was intentionally simple: use a BERT-style encoder for three-way classification not escalate / offer / escalate on English conversations without any escalation guidelines.
We treated it as a standard text classification problem. The model takes the conversation history as input and outputs probabilities for each of the three escalation options.
The results surprised us. The custom model achieved 98% accuracy and often made better decisions than the “teacher” LLM.
However, this approach couldn’t scale: the share of conversations with escalation guidelines was growing fast (now 75% of the traffic), and this model couldn’t handle guideline citations. We needed something more powerful.
Attempt 3: Multi-Task Architecture with Citations
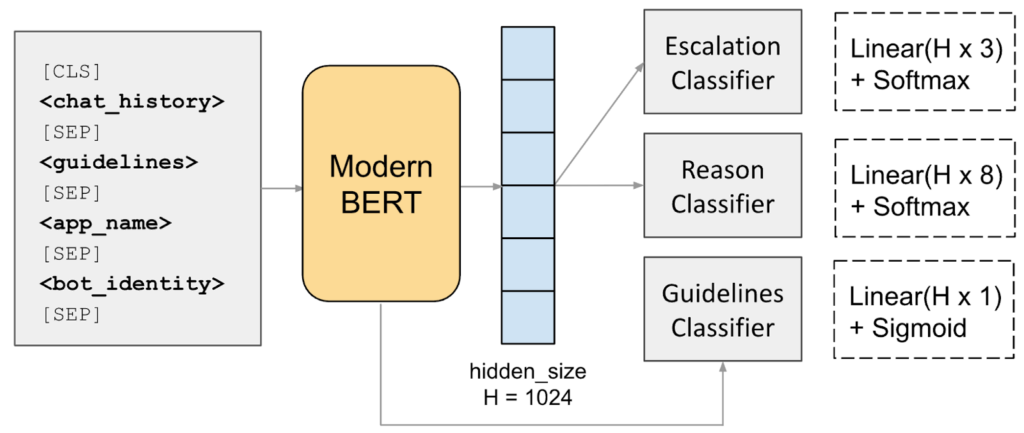
For our final approach, we built a single multi-task model that predicts three things at once:
- Escalation decision (3-way classification)
- Escalation reason (8 categories)
- Guideline citations (which guidelines to cite)
This approach gives us the accuracy we need and full control over the decision process. The multi-task design allows the model to learn shared representations that improve performance across all three tasks: the escalation decision informs the reason prediction, and both help with accurate guideline citation.
Architecture Deep-Dive
Our model uses a single encoder backbone with three classifier heads: escalation and reason classifiers use linear layers with softmax, and the guidelines classifier uses a linear layer with sigmoid for multi-label classification.
The most complex component is guideline citation. The encoder processes the entire input and produces contextual embeddings for every token:
$$\mathbf{h}_t = \mathrm{ModernBERT}(x)_t$$
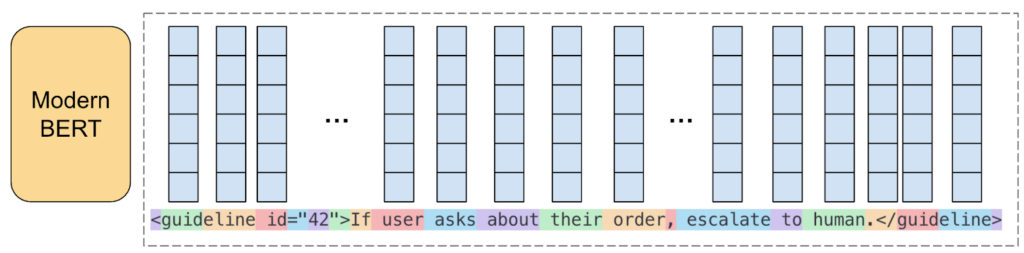
To represent a guideline (a span of tokens in the input), we:
- Identify its \([\mathrm{start}, \mathrm{end})\) token positions
- Extract the contextual embeddings for those tokens and average them (mean pooling):
$$ \mathbf{h}_{\mathrm{guideline}} = \frac{1}{\mathrm{end} – \mathrm{start}} \sum_{t = \mathrm{start}}^{\mathrm{end} – 1} \mathbf{h}_t $$ - Score each guideline by passing its embedding through a linear layer and sigmoid:
$$P(\mathrm{guideline\,is\,cited}) = \sigma ( \mathbf{W} \mathbf{h}_{\mathrm{guideline}} + b )$$
Training details
We trained the multi-task model on 4M examples using a combined loss function that optimizes all three objectives end-to-end:
$${\mathscr{L}}_{\mathrm{total}} = \mathrm{CE}(P_{\mathrm{esc}}, Y_{\mathrm{esc}}) + \mathrm{CE}(P_{\mathrm{reason}}, Y_{\mathrm{reason}}) + \sum_{i=1}^N \mathrm{BCE}(P_{\mathrm{guideline}_i}, c_i)$$
\(\mathrm{CE}\) is cross-entropy loss for escalation and reason classification, and \(\mathrm{BCE}\) is binary cross-entropy loss for guideline citations. Training resulted in stable loss convergence with strong performance metrics on evaluation set:
- Escalation accuracy: 97.4%
- Reason accuracy: 97%
- Citation AUC: 98.7%
Testing and Optimization
We conducted thorough offline testing, covering both in-distribution and out-of-distribution cases. The model performed well across the board, especially at spotting escalation requests and handling ambiguous situations. It often outperformed our original LLM-based system.
To improve further, we analyzed conversations where the custom model and the old production model disagreed. This helped us spot edge cases and refine how we deal with tricky guideline-related situations.
Instead of relying solely on a single model, we implemented a hybrid strategy:
- Our custom model handles 90% of cases with >98% accuracy.
- For the other 10% (mostly very long inputs or complex cases), we fall back to an LLM, which can handle longer context and has better generalization capabilities
This setup gives us the best of both: the reliability and speed of a custom encoder model for common cases, and the adaptability of an LLM for the most challenging interactions.
Impact
An A/B test showed clear improvements:
- Resolution rate increased significantly (p < 0.01), including a significant gain in confirmed “hard” resolutions
- Escalation detection latency dropped by 0.5s
- Cost per resolution decreased by ~3%
Also, refining escalation thresholds improved accuracy and cut false negatives – something we saw with our earlier LLM-based method.
Key Learnings and Discussion
A big part of building this system safely and effectively was treating fine-tuning code like production-grade software. For our multi-task model, we validated each component separately: starting from data collection, finding guideline positions, and batch construction, to checking output shapes, evaluation metrics, and loss computation.
Before scaling up, we trained on small toy datasets to make sure outputs looked correct and the loss converged to zero. These early checks caught subtle issues that would’ve been painful to discover later during full training runs.
Another key to our success was having access to high-quality, domain-specific customer support data. Combined with guidance from LLMs, this let us train a smaller model to outperform its original LLM teacher for our specific support scenarios.
But developing robust ML systems takes more than just good performance on average. It requires careful handling of edge cases, using fallback strategies when the model isn’t confident, and thorough testing with out-of-distribution data.
Our custom escalation router demonstrates all these principles in action. As a result, we built a system that’s not just more accurate, but also faster, cheaper, and more controllable.
