
Introduction
Large Transformer inference is increasingly memory-bandwidth bound rather than compute-bound. In autoregressive decoding, each token requires repeatedly reading the KV cache from memory, and this cost scales linearly with sequence length, layers, and head count. In long-context settings, the KV cache can rival, or exceed, the model’s parameter memory, making memory movement, not FLOPs, the dominant bottleneck.
This post introduces Low-Rank Key-Value (LRKV) attention, a drop-in modification to multi-head attention that reduces KV cache size by 45–53% vs standard MHA, while achieving lower test loss across model scales (128M → 6.3B), faster convergence in training steps, and stronger downstream performance after supervised midtraining.
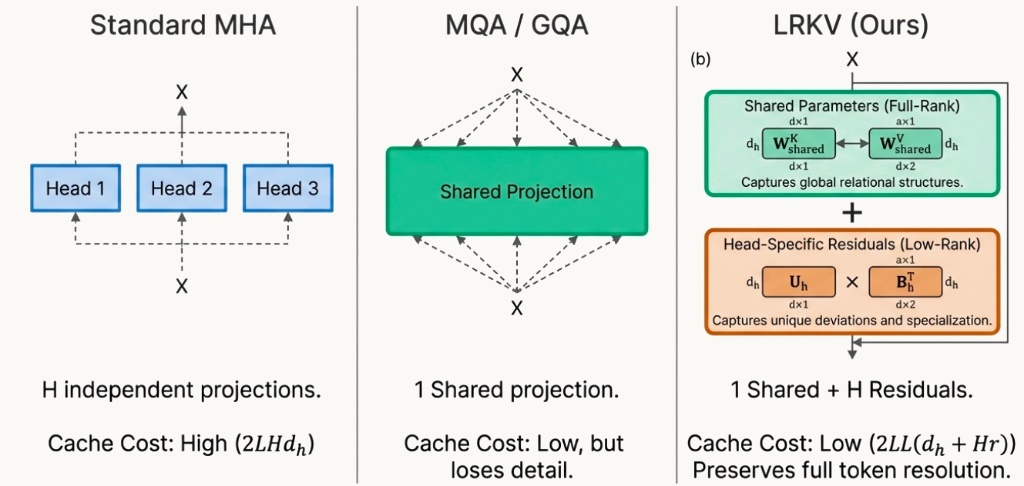
The key idea is that attention heads are not independent. There’s structured redundancy across heads – yet fully sharing keys/values (like in MQA/GQA) can constrain expressivity. LRKV instead exploits redundancy using a shared full-rank KV basis plus head-specific low-rank residuals, yielding a continuous knob between complete sharing and full per-head independence
Why this matters: the KV cache bottleneck
In autoregressive decoding, each layer caches keys and values for all previously generated tokens.
For a sequence length L, number of heads H, per-head dimension dh, and hidden dimension d =Hdh, standard multi-head attention (MHA) caches, for each head, keys and values $$\mathbf{K_h}, \mathbf{V_h} \in \mathbb{R}^{L \times d_h}$$
So the KV cache memory per layer scales as:
$$M_{\text{standard}} = 2 L H d_h = 2 L d$$
Existing methods such as MQA (Multi-Query Attention) and GQA (Grouped-Query Attention) reduce cache size by sharing K/V across heads (or groups). This often improves throughput, but it forces heads to look through the same K/V representations, reducing representational diversity.
Empirically and theoretically, we know that heads specialize: different heads represent complementary syntactic and semantic patterns, and so fully sharing K/V across attention heads can degrade capabilities such as code generation and structured reasoning.
At the same time, we know that head specialization is not fully independent: recent analyses show high correlation and overlapping subspaces across head projections, so the redundancy is structured rather than random.
This motivates the central question:
Can we compress the KV cache by exploiting cross-head redundancy without comprimising head specialization?
This bring us to our main contribution, Low-Rank Key Value Attention (LRKV).
Background
Before discussing our proposed LRKV attention mechanism, we give a concise refresher on the well-established baselines that have been the mainstay mechanisms used in Transformers. If you are already familiar with Multi-Head Attention (MHA), Multi-Query Attention (MQA), Grouped Query Attention (GQA) and Multi-Latent Attention (MLA), you can skip this section.
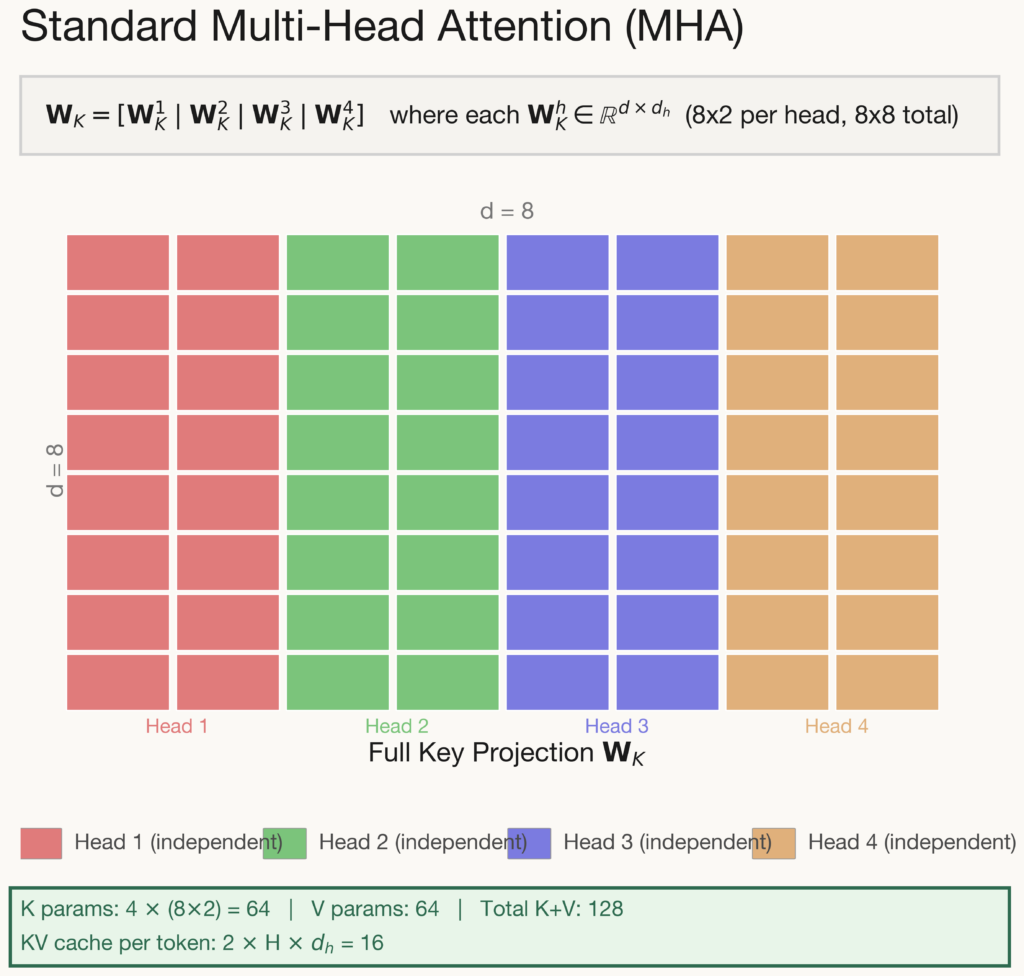
For Multi-Head Attention, each attention head maintains its own independent key and value projection matrices. Standard attention uses per-head key and value projections:
$$\mathbf{K}_h = \mathbf{X} \mathbf{W}_h^K, \quad \mathbf{V}_h = \mathbf{X} \mathbf{W}_h^V \quad \text{where} \quad \mathbf{W}_h^{K,V} \in \mathbb{R}^{d \times d_h}$$
The full projection matrix is formed by concatenating H independent weight blocks side by side, i.e. there is no parameter sharing whatsoever between heads. This gives each head complete freedom to learn specialised key/value representations, making MHA the most expressive configuration available. However, this expressiveness comes at a steep cost: the KV cache scales linearly with the number of heads (\(2Hd_h\) values stored per token), making it the most memory-intensive option during long-context inference.
All other attention variants can be understood as different strategies for reducing this cost while preserving as much of MHA’s expressiveness as possible.
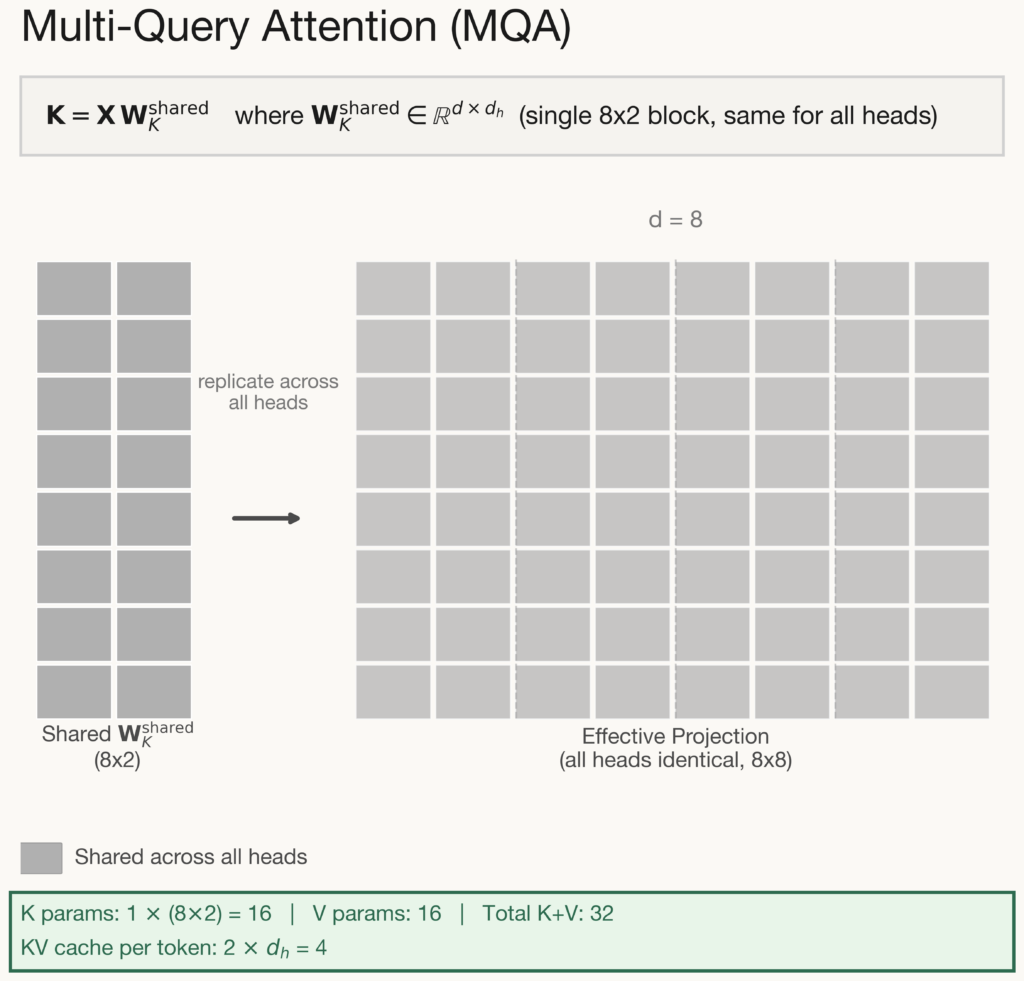
Multi-Query Attention takes the most aggressive approach to KV cache reduction: all heads share a single key and value projection. Each head still computes its own query, preserving some capacity for diverse attention patterns. However, every head attends over the exact same keys and values. The KV cache shrinks from \(2Hd_h\) to just \(2d_h\) per token – a 75% parameter reduction that is transformative for long-context inference where cache memory is the primary bottleneck.
But the trade-off is severe: because all heads attend over identical keys and values, the only way they can differentiate is through their query projections. In practice, heads tend to converge on similar attention patterns, reducing the model’s ability to capture diverse linguistic phenomena simultaneously. In fact, in our paper (see at the end), we quantitatively show that the query parameters are forced to diversify more compared to other less restrictive mechanisms because K and V are the same across heads.
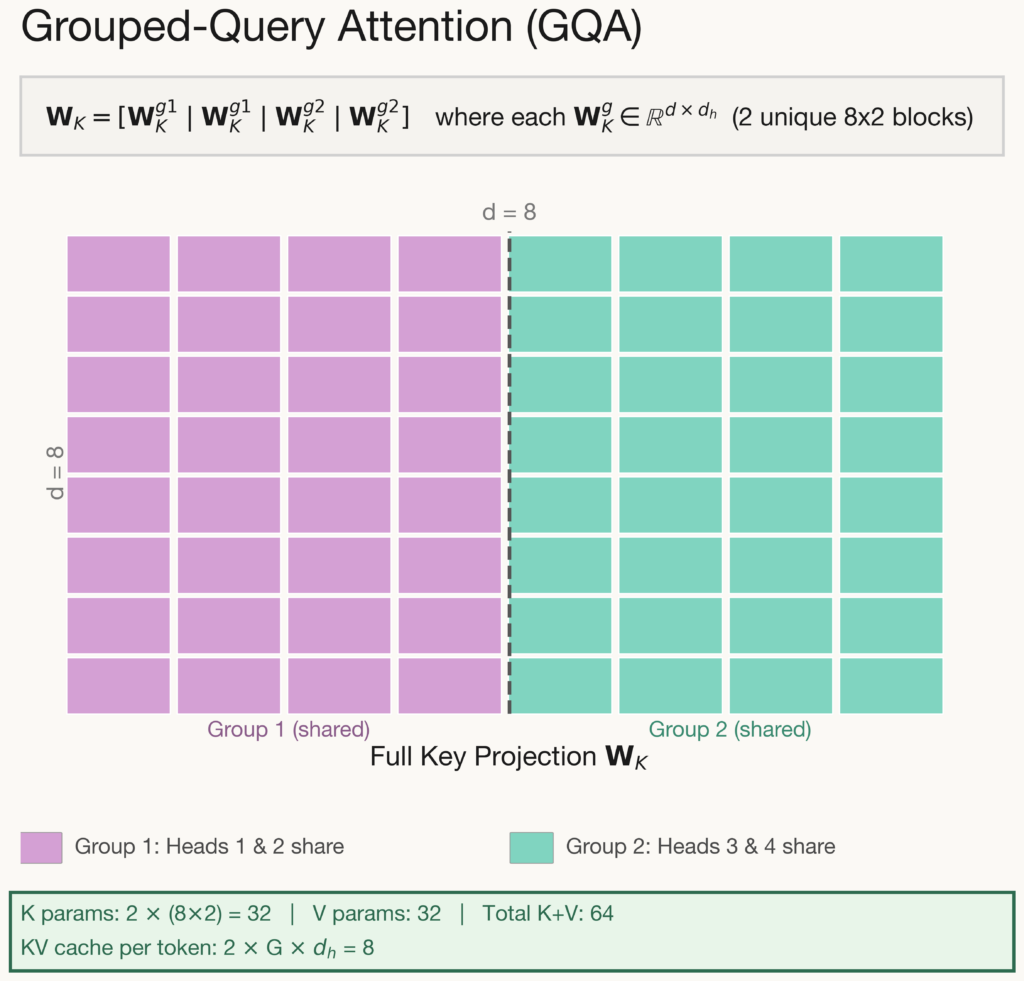
Grouped-Query Attention offers a middle ground between MHA and MQA. Attention heads are divided into G groups, and all heads within the same group share a single key and value projection. In the example above, \(G= 2\): heads 1 & 2 share one projection while heads 3 & 4 share another. This allows groups to specialize in different roles. For instance, one group might focus on local syntax while another captures long-range dependencies. The KV cache reduces from \(2Hd_h\) to \(2Gd_h\) per token. In practice, G is typically set to H/4 or H/8, yielding a 4-8× cache reduction.
The key limitation of this approach is that sharing boundaries are fixed at architecture design time and cannot adapt to the data. Heads assigned to the same group must share representations regardless of whether their learned roles are compatible. This is a coarse-grained constraint that limits flexibility compared to methods that can adapt per-head.
Introduced in DeepSeek-V2, Multi-Latent Attention takes a fundamentally different approach to KV cache compression. Rather than sharing projections between heads (like MQA/GQA), MLA compresses all key/value information into a single low-dimensional latent vector per token. During inference, only this compact latent is stored in the KV cache. When attention is computed, the full per-head keys and values are reconstructed on the fly via learned up-projection matrices. This decouples the cache cost from the number of heads entirely.
This architecture works in two stages. First, a down-projection compresses each token into a latent of dimension \(d_c\) (much smaller than \(d\)). Second, separate up-projections reconstruct per-head keys and values from this shared latent. The effective key projection is an 8×8 matrix but has rank at most d_c. This resembles MHA’s full projection but lives in a lower-dimensional subspace.
There’s a fundamental trade-off here: heads can specialise (unlike MQA/GQA) – but they must reconstruct their keys and values from a shared compressed representation. Any per-head information that does not survive this bottleneck is permanently lost at inference time. We can compare this with LRKV, where each head’s low-rank correction is baked directly into the weight matrix – getting around the information bottleneck during inference.

Given this background on related attention mechanisms, we now move to explaining LRKV.
LRKV parameterization: shared full-rank base + per-head low-rank residual
LRKV factorizes each head’s key and value projection into a shared full-rank base plus a low-rank residual:
$$\mathbf{W}_h^K = \mathbf{W}_{\text{shared}}^K + \mathbf{U}_h^K (\mathbf{B}_h^K)^\top, \quad \mathbf{W}_h^V = \mathbf{W}_{\text{shared}}^V + \mathbf{U}_h^V (\mathbf{B}_h^V)^\top$$
Here Wshared is dense, full-rank, and shared across all heads in the layer,
$$\mathbf{U}_h^{K,V} \in \mathbb{R}^{d \times r}, \quad
\mathbf{B}_h^{K,V} \in \mathbb{R}^{d_h \times r}$$
Finally, \(r << d_h\) is the residual rank.
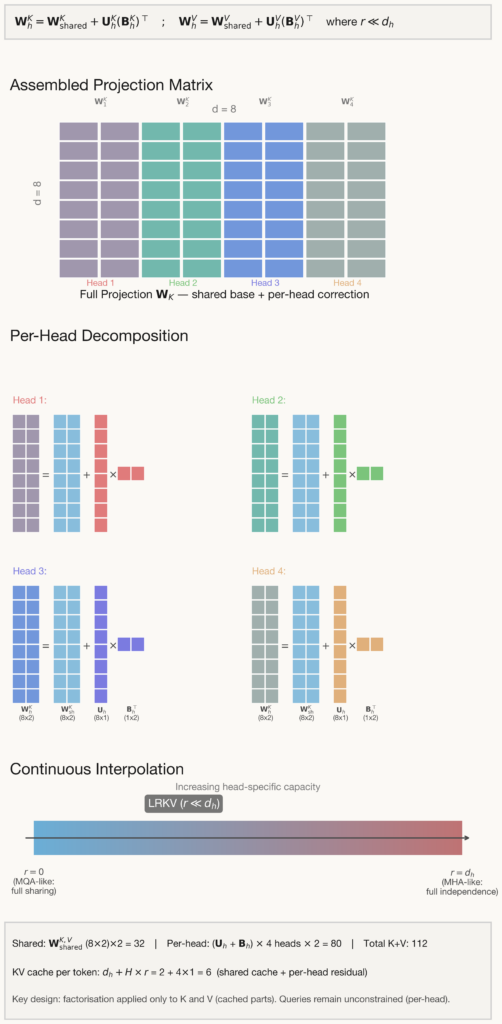
Our interpretation is that the shared base learns a global KV basis for the layer, and each head then learns a small low-rank deviation from that basis. This gives a continuous interpolation: \(r = 0\) reduces to full sharing of K/V within a layer (MQA-style limit) and increasing \(r\) increases head-specific capacity, moving toward MHA.
A subtle but important design choice: LRKV applies the factorization only to K and V (the cached parts). Queries remain unconstrained (per-head), preserving attention expressivity while targeting the true inference bottleneck.
KV caching in LRKV
At inference time, we want to avoid caching Kh and Vh for every head and every token. LRKV caches shared features once per layer:
$$ \mathbf{K}_{\text{shared}} = \mathbf{X} W_{\text{shared}}^K \in \mathbb{R}^{L \times d_h}, \quad \mathbf{V}_{\text{shared}} = \mathbf{X} W_{\text{shared}}^V \in \mathbb{R}^{L \times d_h} $$
Per-head latents:
$$\mathbf{R}_h^K = \mathbf{X} \mathbf{U}_h^K \in \mathbb{R}^{L \times r}, \quad
\mathbf{R}_h^V = \mathbf{X} \mathbf{U}_h^V \in \mathbb{R}^{L \times r}$$
Then the implied per-head features are:
$$ \mathbf{K}_h = \mathbf{K}_{\text{shared}} + \mathbf{R}_h^K (\mathbf{B}_h^K)^\top, \quad \mathbf{V}_h = \mathbf{V}_{\text{shared}} + \mathbf{R}_h^V (\mathbf{B}_h^V)^\top $$
Crucially, Bh are parameters, not cached per token. So the cache memory becomes:
$$M_{\text{LRKV}} = 2 L d_h \; (\text{shared } K,V)\quad 2 L H r \; (\text{per-head latents}) = 2L(d_h + Hr)$$
Relative to standard MHA:
$$\frac{M_{\text{LRKV}}}{M_{\text{standard}}}\frac{d_h + Hr}{H d_h}\frac{1}{H} + \frac{r}{d_h}.$$
This is the cleanest engineering knob LRKV provides: for fixed H and dh, the residual rank r trades cache size for per-head flexibility.
Exact attention without explicitly reconstructing full K/V tensors
Naively reconstructing the full per-head keys and values for every cached token would erase the practical gain. Instead, LRKV computes logits and outputs exactly via associativity.
For a decoding step with query qh the attention logits are:
$$\mathbf{q}_h \mathbf{K}_h^\top=\mathbf{q}_h\mathbf{K}_{\text{shared}}^\top+(\mathbf{q}_h \mathbf{B}_h^K)(\mathbf{R}_h^K)^\top, \quad \mathbf{q}_h \in \mathbb{R}^{d_h}$$
For attention weights ah the value aggregation is:
$$\mathbf{a}_h \mathbf{V}_h=\mathbf{a}_h \mathbf{V}_{\text{shared}}+(\mathbf{a}_h \mathbf{R}_h^V)(\mathbf{B}_h^V)^\top, \quad \mathbf{a}_h \in \mathbb{R}^{1 \times L}$$
These expressions compute the same outputs as full reconstruction, but operate on smaller cached tensors:
$$\mathbf{K}_{\text{shared}}, \mathbf{V}_{\text{shared}} \in \mathbb{R}^{L \times d_h} \quad \text{and} \quad \mathbf{R}_h^K, \mathbf{R}_h^V \in \mathbb{R}^{L \times r}.$$
That is precisely where the memory win is realized.
What does LRKV cost in compute?
During decoding, standard MHA’s dominant per-head cost scales as:
$$O(L d_h), \quad \text{while LRKV adds } O(L r + r d_h).$$
For long contexts: $$L \gg 1 \quad \Rightarrow \quad O(L r) \text{ dominates, giving overhead } \sim \frac{r}{d_h}.$$
In modern inference, we’re often memory bandwidth bound, so reducing the bytes moved can dominate a modest FLOP increase. LRKV reduces total bytes read from cache proportionally to its cache reduction: it reads two shared tensors plus small per-head latents instead of full per-head K/V.
Results
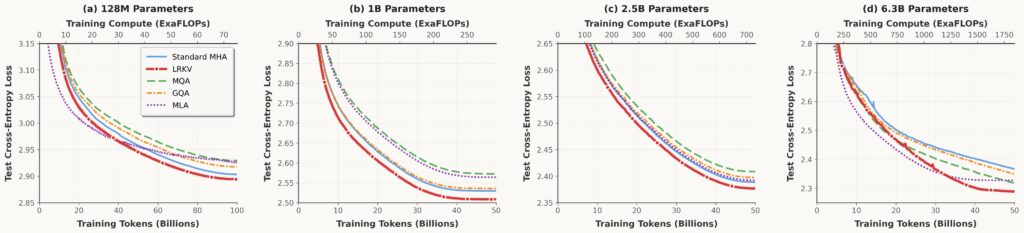
With the design space now fully mapped, from MHA’s full independence, through MQA and GQA’s discrete sharing strategies, to MLA’s latent bottleneck and our proposed LRKV’s continuous low-rank interpolation, the natural question is: how do these architectural choices actually play out in practice? We evaluate all five methods under identical pretraining and midtraining conditions across three model scales (128M, 2.5B, and 6.3B parameters), measuring both pretraining loss and downstream task performance on five diverse benchmarks.
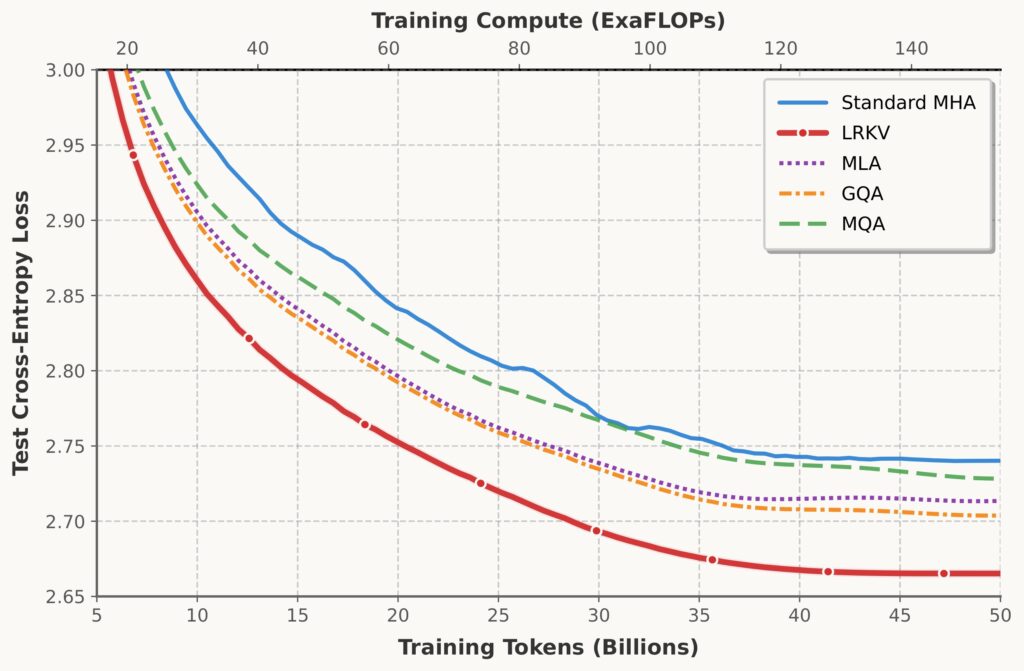
Cross-scale pretraining curves
Our results are very encouraging: LRKV reaches each baseline’s final validation performance 18-30% faster, averaging 23.6% training compute savings across all baselines while achieving better final performance. Critically, this reveals an asymmetric advantage: LRKV reaches any baseline’s performance target early in training, but no baseline reaches LRKV’s final performance (0.719 BPB) even after the full token budget.
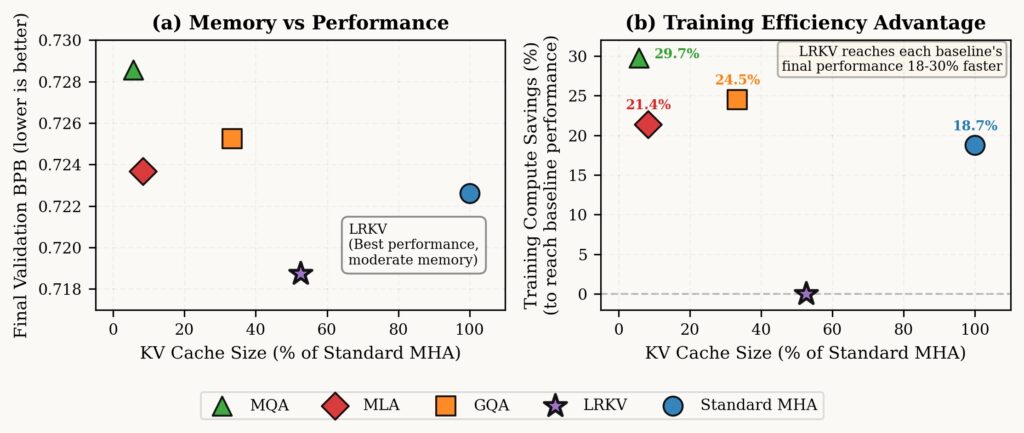
Memory vs Performance (left): Test BPB versus KV cache percentage for all methods. LRKV achieves optimal trade-off with lowest BPB at 48.4% cache usage (2.5B scale). Training Efficiency Advantage (right): LRKV reaches each baseline’s final test loss, quantifying training compute savings. LRKV reaches all baselines’ performance earlier.
- Across 128M → 6.3B, LRKV reaches lower test loss than MHA, MQA/GQA, and MLA, while using 45–53% of MHA KV cache.
- LRKV reaches equivalent baseline quality 18–25% faster (in training steps), i.e., better sample efficiency.
Training efficiency & memory/performance tradeoff
The residual rank r controls the tradeoff. The ablation shows monotonic improvement with larger rank, and a strong Pareto frontier relative to other KV-efficient methods.
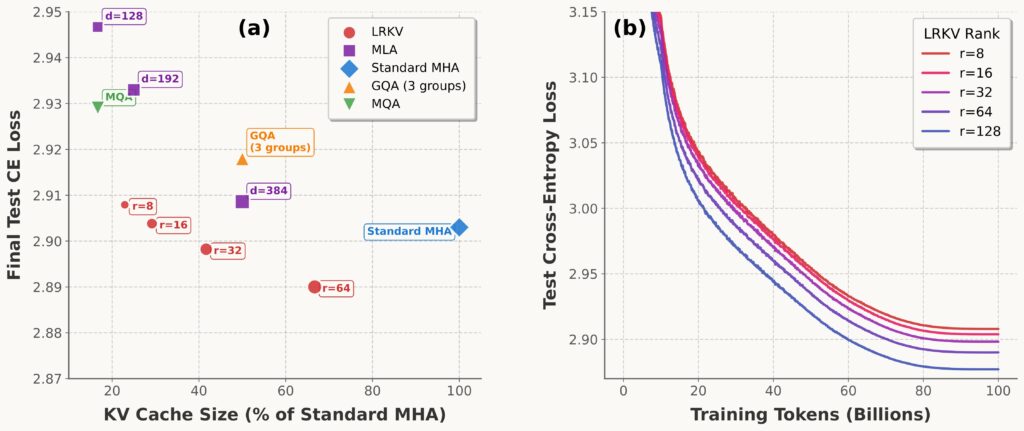
LRKV appears to be not merely “a compression trick”, but a bias that improves optimization and/or effective capacity under the same token budget. Empirically, we see a consistent “useful rank” regime around: $$r \approx 0.36–0.43 \times d_h$$ as a threshold where LRKV matches/exceeds MHA while still delivering ~50% cache reduction.
Long-context pretraining
At longer sequence lengths, the benefits of KV-efficient attention become more pronounced. The below figure shows that LRKV not only maintains its advantage over standard MHA, but actually widens the gap in the long-context regime. At 8K context, LRKV achieves lower test loss while using roughly half the KV cache, outperforming both MHA and other KV-efficient baselines such as MQA, GQA, and MLA. This suggests that the low-rank decomposition is not merely compressing redundant structure, but acting as an effective inductive bias for long-range modeling. As context length increases and KV cache pressure becomes the dominant bottleneck, LRKV’s combination of memory efficiency and preserved head diversity translates directly into improved modeling performance.
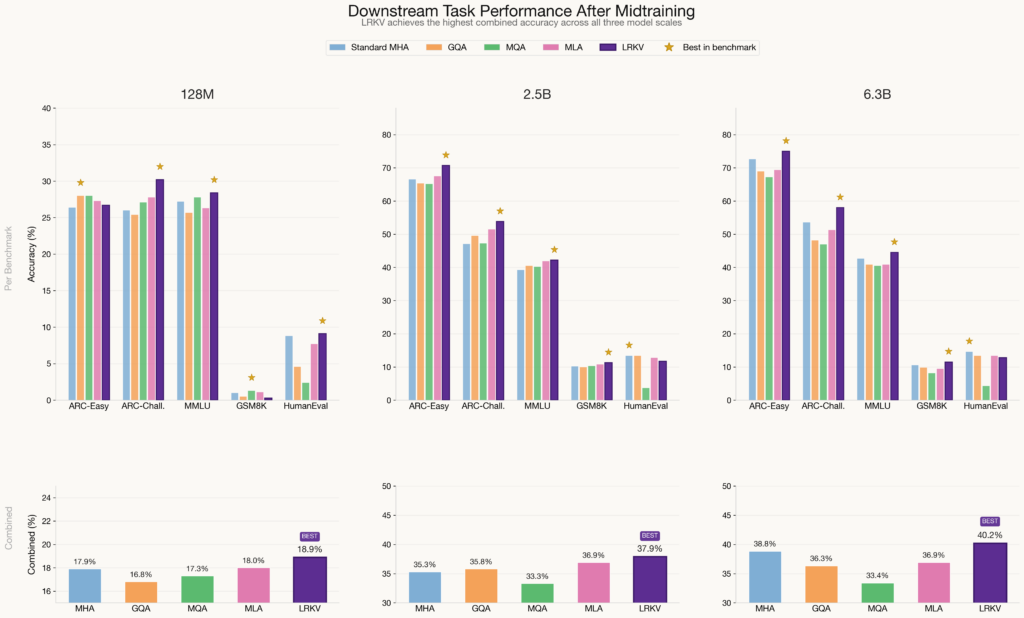
Downstream Task Performance
A reasonable question is whether these gains turn into better downstream task performance. On a standardized evaluation after supervised mid-training, LRKV achieved the highest combined score across ARC, MMLU, GSM8K, and HumanEval, confirming that its improved pretraining efficiency translates into better downstream performance.
The below figure shows LRKV consistently achieves the highest combined accuracy at every scale – 18.9% (128M), 37.9% (2.5B), and 40.2% (6.3B) – demonstrating that the pretraining gains afforded by LRKV transfer reliably to downstream capabilities. At the 2.5B and 6.3B scales, LRKV leads on four of five benchmarks, with particularly strong margins on knowledge-intensive tasks: at 6.3B it surpasses the next-best method by +2.3% points on ARC-Easy, +4.4% on ARC-Challenge, and +1.8 on MMLU. Notably, MQA suffers a pronounced collapse on HumanEval at all three scales (2.4%, 3.7%, 4.3%). Crucially, the gap between LRKV and competing methods widens with scale, rising from +0.9 over MLA at 128M to +3.3 at 6.3B, reinforcing the conclusion that LRKV’s architectural advantages compound as model capacity increases.
Why does LRKV preserve head diversity (and why that’s non-trivial)?
A common failure mode of aggressive KV sharing is that heads lose the ability to represent distinct interactions. LRKV claims you can reduce KV cache without degrading diversity by preserving a shared basis plus low-rank head-specific deviations. We measure head diversity using gauge-invariant similarity metrics derived from bilinear forms:
$$\mathbf{A}_h = \mathbf{W}_h^Q (\mathbf{W}_h^K)^\top$$
We then compare the architectures via similarity matrices and effective-rank via eigenvalue entropy.

Effective rank across scales
We see LRKV exhibits very similar patterns to Standard MHA with sufficient rank of r=64 and achieves 98.3% effective rank at 2.5B scale versus 98.9% for Standard MHA. In contrast, MQA achieves only 86.2% and GQA 95.4%.
Interpreting uncentered vs. PCA-based effective rank.
The distinction between uncentered and PCA-based effective rank reveals LRKV’s factorization structure. Uncentered analysis measures total variance including the shared mean direction, the global structure captured by Wshared. PCA-based analysis centers the Gram matrix, isolating variance around this mean and measuring true head independence. The modest 4.8% gap indicates LRKV achieves diversity primarily through genuine per-head specialization rather than merely perturbing a dominant shared structure. For comparison, MQA shows dramatic improvement from uncentered (86.2%) to centered (91.0%), a compensation effect where forced KV sharing creates a strong mean direction, but heads recover diversity by aggressively diversifying query projections around this baseline.
Implementation notes
Cache layout
Store:
$$\mathbf{K}_{\text{shared}}, \mathbf{V}_{\text{shared}} \in \mathbb{R}^{L \times d_h}, \quad\mathbf{R}_h^K, \mathbf{R}_h^V \in \mathbb{R}^{H \times L \times r}$$
while BhK, BhV are parameters stored in the weights, not the KV cache.
Kernel fusion
The associativity forms used in LRKV are:
$$\mathbf{q}_h \mathbf{K}_h^\top = \mathbf{q}_h \mathbf{K}_{\text{shared}}^\top + (\mathbf{q}_h \mathbf{B}_h^K)(\mathbf{R}_h^K)^\top, \quad
\mathbf{a}_h \mathbf{V}_h = \mathbf{a}_h \mathbf{V}_{\text{shared}} + (\mathbf{a}_h \mathbf{R}_h^V)(\mathbf{B}_h^V)^\top$$
These allow exact attention computation to be embedded in fused kernels (e.g. FlashAttention) without reconstructing full Kh and Vh tensors.
Choosing rank r
Use the memory ratio:
$$\text{ratio} = \frac{1}{H} + \frac{r}{d_h}, \quad r \approx (0.36\text{–}0.43)\,d_h$$
Choose r to match your cache target, then validate quality.
Takeaways
LRKV is a structural change to attention that:
- Targets the true production bottleneck (KV cache memory + bandwidth)
- Exploits structured redundancy across heads
- Provides a smooth knob (rank r) between MQA-like sharing and MHA-like independence
- Empirically delivers a strictly better quality/efficiency frontier than common baselines, on analysis across a wide range of scales.
For full details and additional experiments, see the paper: Low-Rank Key-Value Attention (arXiv).



