
Using customer service conversations as a source of truth is a very tempting idea but the sheer volume of the conversations may flood AI Specialists. By experimenting with various architectures, we have found a solution that offers promising volume/quality trade-off.
Today, AI Customer Agents like Fin are handling more tickets than humans do. But as the conversation volume they handle continues to grow, the bottleneck becomes high quality knowledge, and keeping your knowledge center up-to-date.
On May 21st, we launched Insights, an AI-powered suite of products that delivers real-time visibility into your entire customer experience. As part of Insights, we built ‘Suggestions’ to help improve knowledge center documentation and Fin’s performance.
Fin relies on retrieval-augmented generation (RAG) to answer questions, so the quality of its responses depends on the quality of your content. While the AI Group has invested heavily in making both the retrieval and the generations better, we also needed to help improve documentation. Suggestions uses LLMs to generate targeted, pre-written updates, and delivers them in a simple UI so you can review, accept, or edit changes with a single click.
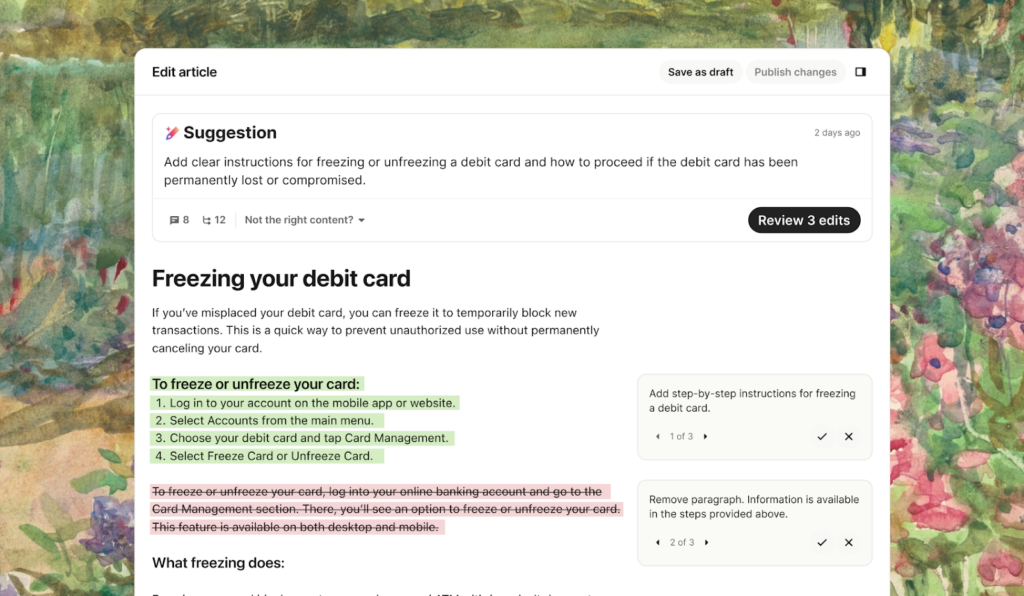
To generate these Suggestions we analyse all your unresolved conversations to recommend ‘Edit Suggestion’ or question-answer ‘Snippets’ based on how human agents handled these cases. This creates a self-improving loop, helping to enhance both the knowledge base and Fin’s resolution rate while giving more control and support to AI Specialists maintaining them.
Since the launch of this new feature, the average approval rate of new Suggestions is around 60%, and we have found strong evidence of positive impact on resolution rate. For a detailed explanation of how suggestion effects are calculated, please refer to the companion article. You can access it through this link.
Building the Suggestions product
Our system began as a single conversation extraction system called Inbox Snippets and evolved into the current iteration of the Content Suggestions. The key success of this new feature is a new architecture that we’re calling `accumulation driven extraction`. In this article, we’ll present the main features of both of the systems and the reasoning behind the improvements and trade-offs we made to achieve these results.
This new Accumulation Driven Extraction architecture enables us to gather multiple conversations as evidence for new content generation. This new system addresses previous issues from the Inbox Snippets like content duplication and low relevance by generating suggestions only when there is evidence from multiple customer conversations. This approach also significantly improves the content quality.
Extracting Answers from Conversations
LLMs demonstrate significant strengths in summarizing and rewriting the information found in documents.
Because Fin utilizes a customer’s knowledge center to answer new customer questions, a lack of up-to-date data could result in a poor customer experience and missed opportunities to answer informational queries.
Our hypothesis was that we could leverage the conversations that Fin couldn’t answer but that customer agents did resolve as a source of up-to-date information, by extracting and summarizing these questions, then adding these snippets to the knowledge center so Fin can use fresh information next time another customer asks the same question. This creates a Data Flywheel for Fin. In this context, a Data Flywheel refers to a system that continuously updates itself with new data, enhancing its performance over time and counteracting data drift so as to achieve ongoing improvement.
Solution Architecture
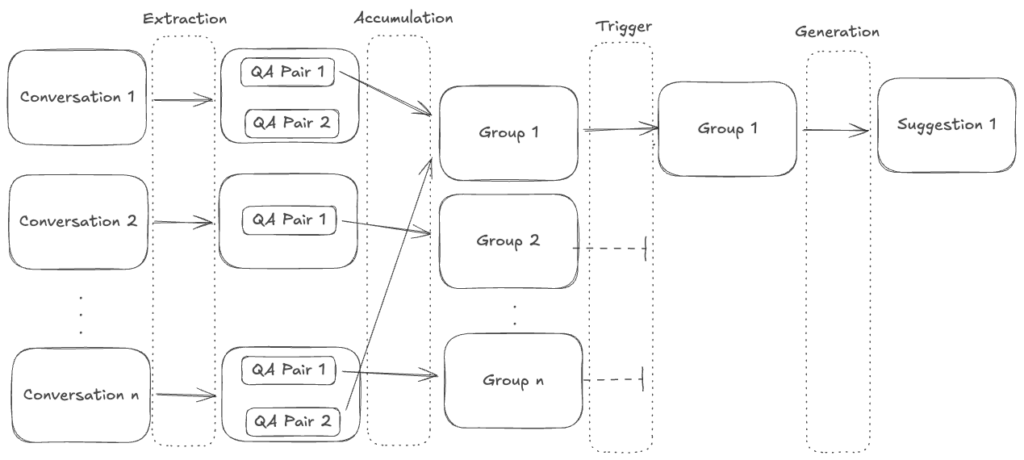
The current system is based on extracting question and answer pairs from relevant conversations, grouping them based on their similarity and triggering them only when certain conditions are met. This structure has many benefits especially for improving the suggestion quality, being able to gather multiple pieces of evidence for any information included and reducing the risk of duplicated suggestions. Finding and eliminating potential duplicates has been a key consideration in the design of this architecture. It achieves this through three primary methods::
- Detection After Extraction: Each Q&A pair is compared against existing knowledge center articles. If the information is identical, the pair is discarded. On average, this step eliminates around 20% of all generated pairs.
- Accumulation Grouping: Similar Q&A pairs are grouped together, and these groups remain active even after a suggestion is generated. If a duplicate slips through initial detection, it is still likely to be caught at this stage. Approximately 8% of Q&A pairs are absorbed into these existing groups, effectively preventing duplication.
- Detection After Generation: Though less frequent, a final comparison with the knowledge center is conducted post-generation. Content found to be too similar to existing articles is removed. This step accounts for the elimination of about 3% of all generated content.
Create Suggestions and Edit Suggestions
Once the content is generated, it can be added to the knowledge center as a stand alone document.
However, as we started to generate longer and more thorough documents, these pieces of content started to have more sections that were natural extensions of the other existing documents in the knowledge center. Also, these sections often covered similar topics from different angles.
To resolve this issue once we generate a suggestion, we check whether it is similar enough to any of the existing documents and if they are similar enough, these are surfaced as Edit Suggestions.
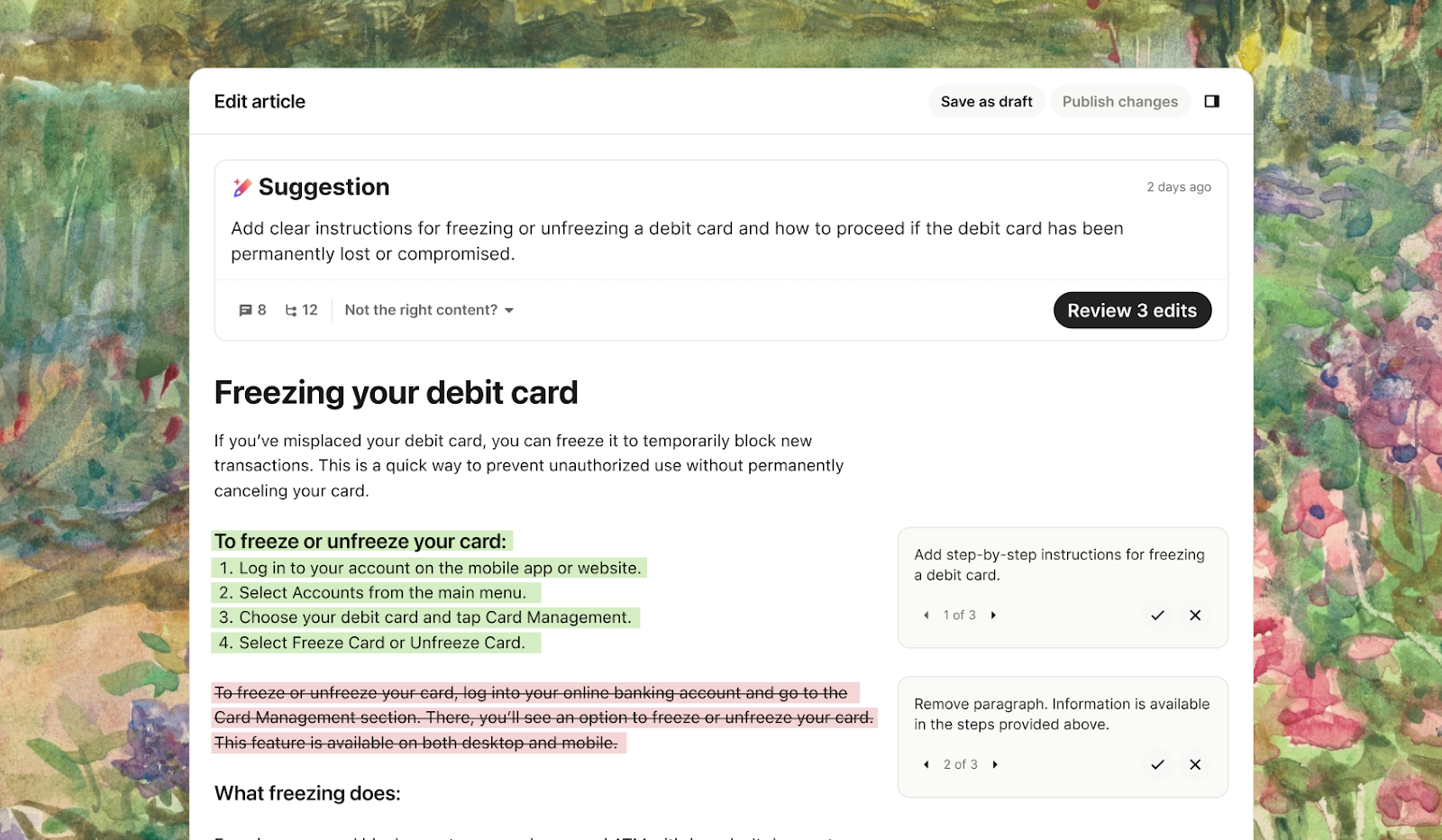
If we don’t find any similarity to the existing content, we instead suggest a standalone document. This is what we call Create Suggestions.
The Foundation: Inbox Snippets
The first iteration of what eventually became today’s automatic content generation was a feature we first built in 2023, called ‘Inbox Snippets’. This feature’s main goal was to capture the answer that resolved a customer’s question after the end-user requested to talk to a human agent. This content was then presented as a simple question and answer to the customer agent before the conversation’s closure. The new content required approval from the agent to be added as a snippet.
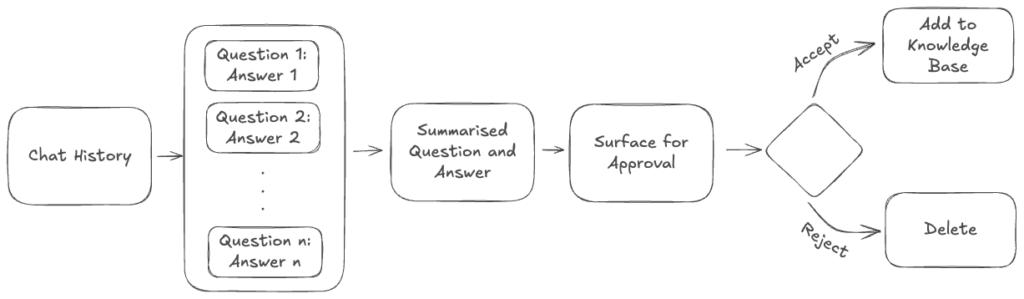
To achieve this, we:
- Discard:
- short conversations
- answers that are too similar to knowledge center articles
- Limit the conversation size to the last 10,000 characters
- Extract all questions and answers in the conversations
- Discard irrelevant or AI-generated Answers
- Summarize high-quality questions
- Present to the customer agent to decide whether to add the snippet or discard
To prevent overwhelming agents, we limited daily recommendations to 3 per agent.
It Worked! But With Caveats
The Inbox Snippets feature gathered a lot of attention and excitement after its launch in November 2023. By November 2024, over 80% of all active Fin customers used the Inbox Snippets. It helped to generate 91,000 snippets.
Over this time, we conducted multiple A/B tests to verify the snippets’ contribution to the resolution rate. While we found a positive effect from these ablation studies, it was difficult to fully quantify the effects. Some of the reasons are as below:
- AI Specialists frequently copy the contents of snippets into articles, thus compromising the independence of the A/B test (up to 30% of the information in the snippets was replicated into articles).
- As the knowledge centers are dynamic environments, the information within them evolves constantly, creating multiple paths to the same resolution, making simple ablation studies hard to conduct, for further discussion on this please refer to the companion article, here.
Despite the positive effects, customer reception and high usage did not fully translate into a high approval rate for the snippets. By July 2024, over nine months after its release, agents accepted only 12% of the generated snippets. They reject most of the snippets immediately or snoozed, only to be reject them in bulk later.
After analyzing the rejection reasons of the snippets and collecting direct customer feedback, we identified the following major issues:
- Too much content: an excessive number of snippets were recommended at any given time. Customers initially expected to receive a large batch of snippets, anticipating a reduction in recommendations over time. However, the number of snippets remained generally consistent, even for customers who accepted many.
- Capturing the low relevance questions: a lot of the customer conversations can focus on the specific information that is focused on a single customer’s case. It is difficult to determine if a conversation is generalizable just by looking at it, and even comparing it with the knowledge center content doesn’t always help because snippets bring new information by nature. Customers regularly complained about receiving frequent snippets that could not be generalized for this reason.
- Wrong approval point: with Inbox Snippets, customer agents decide whether information should be added. However, agents often lack the time to evaluate if the information should be permanent and may need to consult experts. The UI, however, forced an immediate decision. This tension resulted in many agents rejecting high quality snippets.
- Duplicated Content: the system processed all conversations involving Fin, which triggered many content generations. Although we had checks to detect existing information in the knowledge center, duplicate content was still generated. This caused reduced trust in the product from customers and a frustration from agents as it wasn’t easy to check if the information was duplicated in the knowledge center already.
Addressing the Low Approval Rates
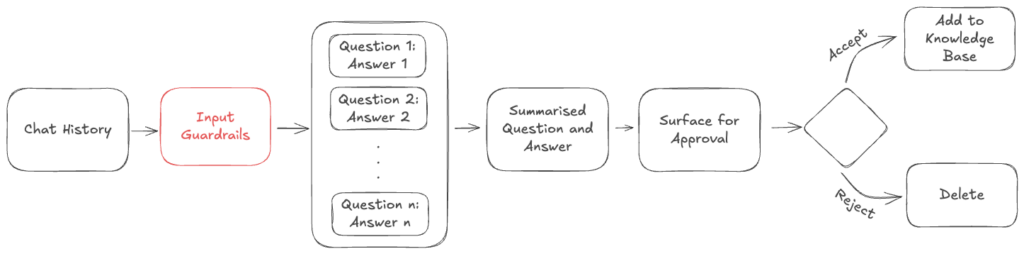
Input Guardrails
First, we introduced input guardrails to more intelligently filter out conversations before we attempt to extract anything. For this step, we added a smaller LLM judge to sanity check if the conversation is above the desired quality. This LLM judge checks the following parameters:
- Make sure that the conversations have a full cycle. A full-cycle conversation is one where an agent has answered at least one of the customer’s questions, and the customer has responded to that answer
- Detect spam or abusive conversations
- Make sure that there are conversation is due to the informational answers and not by actions from the human agent
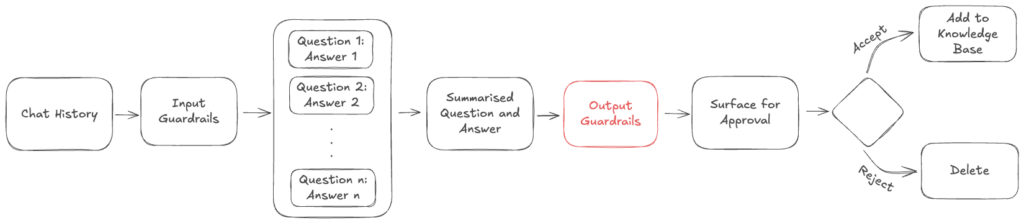
Output Guardrails
Output Guardrails were added to detect any issues leftover after the extraction was complete. It acts as a second pass to detect:
- PII
- Time sensitivity
- Non-informational answers (such as agent changing some data manually)
- Personal links and URLs
- Phatic expressions
- Situational interactions (e.g. account verifications)
If any of these issues were detected, the output guardrails would try to rewrite the information without these, and if the rewritten content lost the critical information that could make the suggestion unviable, the system discarded the content.
Better Duplicate Detection
The original system we implemented checked whether the customer agent’s response was a direct copy from an existing knowledge center article. While this actually was successful in filtering out around 3% of all extractions, it failed whenever the agent altered the text semantically or added any information.
To improve detection, we added an LLM judge that also evaluated the generated content and checked for similar passages in the existing knowledge center.
We considered evaluations in the following details:
- Identical: The new generation is completely covered by the knowledge center article
- Similar with variations: There is some similar information but some novel information exists as well
- Unrelated: There are no overlapping information between the texts

Impact on Snippets Approval Rates
Following the implementation of all these guardrails, the approval rates of the snippets increased to 28% from the initial 12%.
Filtering out lower quality conversations, rewriting bad quality outputs and catching duplicates helped, but we still suffered from a high number of snippets being generated. We also couldn’t solve the problem ofthe snippets capturing non-generalizable information.
While much better than the initial 12%, 28% approval rate didn’t signal a well trusted solution by the users. That led to seeking alternatives that changed the approach more dramatically, leading us to Accumulation Driven Extraction architecture.
Extracting via Accumulation: Content Suggestions
While the improvements described above doubled the approval rates of automatically generated content, the issues of generalization and duplication persisted. The number of duplicated content decreased but the issue of too many snippets and the non-generalisable information were only affected marginally by these changes.
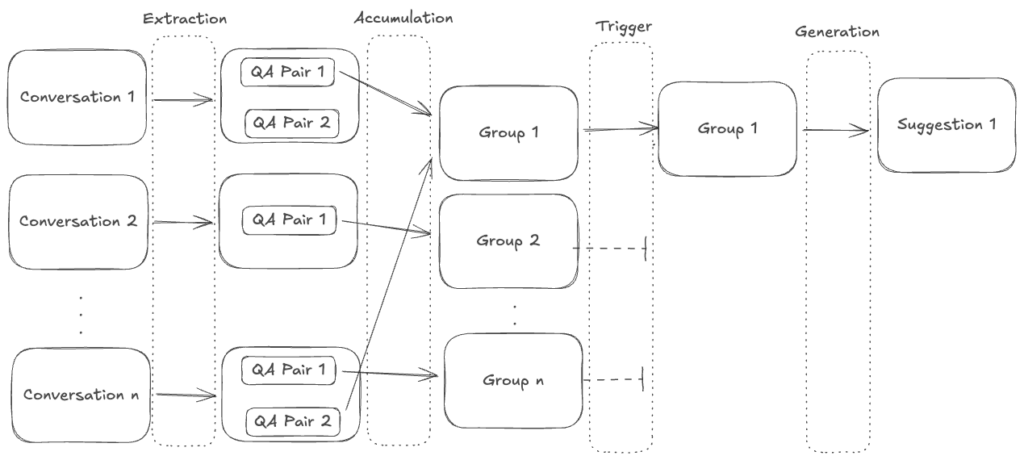
The solution we came up with is to add an additional layer between extraction and generation. This layer would group similar questions together and only generate content for information that can be verified from multiple conversations. After extracting all of the questions from the conversations, the questions are grouped by the accumulation system and only if specific conditions are met, these groups are moved to the generation stage, where we attempt to validate the information presented from multiple conversations and propose a final document for the customers to review:
Previous improvements, such as duplicate reduction, are still part of the extraction pipeline.
Notably, we shifted the decision-making from customer agents to AI Specialists, providing them with multiple opportunities to validate the underlying conversations and understand their necessity. Here’s how it looks in the UI:

The extraction has been divided into four independent layers:
- Extraction: filters out low quality conversations and extracts any resolution source found in the document, also checks if the extracted information already exists.
- Accumulation: checks whether a similar question has been asked, and groups them together.
- Trigger: checks whether trigger conditions are met. The trigger conditions could be based on the volume, a sudden spike in the group or persistent long term queries that might have lower volume.
- Generation: selects the relevant question answer pairs that can be verified from the triggered group and generates content. There are two kinds of suggestions:
- Create Suggestions: if the new content is not substantially similar to any existing content available to Fin, we recommend adding it as a standalone article.
- Edit Suggestions: if the newly generated content is similar to an existing article, the system can suggest adding the new information to that article. The system might decide to generate the edit, or AI Specialists can decide to add the content to an article themselves.
This new architecture solves the previous issues as detailed below:
- Too Much Content: as the system waits until there’s enough evidence, the singular questions from customers never get to be surfaced. This acts as a barrier also after the suggestion is surfaced to ensure that we don’t pose similar suggestions.
- Generalizable Information: by cross-checking many conversations, we can confirm that the same information is being repeated to multiple customers, creating a more solid foundation for generation.
- Duplicated Content: the questions groups formed in the accumulation step forms an effective catch-all even after the generation.
Trade-Offs
Lower Suggestion Volume for Higher Relevance
The system deliberately waits for content to accumulate and finds multiple pieces of evidence to cross-check the validity of any information that is discovered from the conversations. This requires a significantly higher volume of conversations. To mitigate this, we implemented a variable triggering structure that sets the threshold to trigger a suggestion based on conversation volume. While this partially offsets the effect, the trade-off remains: companies with lower conversation volumes (under 500 per month) will receive fewer suggestions than they might have with the previous, less precise system.
Higher Cost-per-Suggestion for Greater Accuracy
The new system is more complex and as we rely on multiple pieces of evidence, this relies on substantially longer inputs to our LLM services, making the cost-per-suggestion significantly higher than in the previous system.
This increased cost-per-suggestion is balanced by a lower frequency of generation. Due to our aggressive, multi-stage filtering, the system generates suggestions less often, leading to a more manageable total cost. We also put a limit to the number of suggestions generated in a week as the customers are unable to review too many generations at a time.
Results
The new suggestions experience has moved to Open Beta after the Intercom’s Built For You event in May 2025. Within the first month, we have seen rapid adoption and the customers added over 5,000 suggestions to their knowledge centers.
During this month, we have seen a massive increase of approval rates
| Overall Approval Rate | Edit Suggestion Approval Rate | Create Suggestion Approval Rate | Previous Approval Rate |
| 60% | 68% | 53% | 28% |
The articles with accepted suggestions have so far been used in over 100k conversations and contributed to over 70k resolutions made by Fin.
We estimate an overall 1.2% absolute resolution rate improvement. The full distribution of the resolution rate results can be seen below.
The results and the graphs above are taken from our companion article on how we measured the effectiveness of the suggestions feature. Make sure to check that article to understand how we think about measuring the impact of Suggestions.
Future Of Suggestions
With Suggestions, AI Specialists finally have a scalable way to teach Fin, spot knowledge gaps, and deliver smarter answers—faster and better. The results speak for themselves: embracing Suggestions leads to higher resolution rates, and those who adopt them widely see the greatest benefits.
This is just the beginning. As we keep refining Suggestions, we’ll be working on smarter features: surfacing duplicates, highlighting contradictions, and even recommending actions that will make Fin more personalized than ever. Stay tuned—we’re grokking even more sophisticated Insights into AI support experience provided by Fin.



