The Looped Transformer Moment
Looped transformers are having a moment – possibly fuelled by rumours that Claude Mythos is built on a looped transformer architecture! We’ve since seen open-source projects such as ‘OpenMythos‘, and researchers at the University of Tokyo formally comparing looped transformers to chain-of-thought reasoning.
While this is all still speculation, it would be consistent with Mythos’s jump on GraphWalks BFS 265K–1M (80% vs Opus 4.6’s 38.7%) — exactly the kind of recursive graph-traversal task where iterative latent refinement should shine.
Whether there’s truth to the rumours or not, the underlying idea of Looped Transformers is both interesting and deceptively simple: take a transformer, loop it over its own representations, and watch it reason.
The lineage behind this idea runs from Universal Transformers (Dehghani et al., 2019) through the recent theoretical analysis of Looped Transformers (Saunshi et al., 2025), depth-recurrent architectures (Geiping et al., 2025), and the TRM/HRM family of models that my co-authors and I have been working on. The headline result that sparked much of this recent buzz was a model with only 7 million parameters, looped repeatedly over latent states, achieving 44.6% on ARC-AGI-1 — dramatically outperforming comparably-sized models and notably surpassing many commercial LLM APIs on this benchmark.
Our recent ICLR 2026 workshop paper also sits squarely in this space — we replaced the Transformer blocks in TRM with Mamba-2 hybrids and found something interesting:
- The hybrid model is more likely to find the correct answer than the pure Transformer recursive model,
- …but the pure Transformer is more confident at placing the correct answer in first position.
I will get to those results later in this post, but first, I want to step back and think about reasoning with LLMs at a higher level. Before we can answer questions like why looped transformers have a reasoning edge, whether we should be looping all LLMs, or what the final form of a reasoning model looks like, we need to understand what reasoning actually is in the context of these models.
What is the source of reasoning? Is it the visible chain-of-thought — the quality of the intermediate steps, the right decomposition? — or is it the iterative process itself, providing enough forward passes for the model to refine its answer regardless of what the tokens say? Does reasoning come from the trace or from the recursion?
These questions are not academic – they determine whether the path forward is better prompting, better training data for chain-of-thought, or fundamentally different architectures that think in latent space. Getting the framing right matters as we invest in any particular direction.
Reasoning as Conditional Distribution Shaping
An autoregressive transformer models a conditional distribution over token sequences. Given an input \(x\), it assigns probability to a continuation by predicting one token at a time. This is the standard next-token prediction view, and it is correct but incomplete.
The problem is that reasoning is not well captured at the token level. A final answer is a semantic object that can be expressed by many different token strings. “42”, “the result is 42”, and “forty-two” are all the same answer. The right abstraction is therefore not the token distribution but the induced distribution over semantic outcomes:
\(P(A = a | x) = \sum_{y \in Y(a)} ^{} P(y|x)\)
where \(Y(a)\) is the set of all token sequences that express answer \(a\). Reasoning, from this perspective, is the process of shifting probability mass among semantic outcomes — not among surface strings.
This reframing matters because a model might assign low probability to a terse answer but high probability to a full explanation that ends in that answer. The model’s reasoning behaviour is better studied as a distribution over possible solution trajectories and final outcomes.
Reasoning is not convergence
It is tempting to describe autoregressive reasoning as repeated self-refinement: the model keeps processing the same problem until the answer distribution converges. But this is not quite right.
Every generated token becomes part of the next condition. After the model emits a token, the context changes, and the next distribution is conditioned on a new state. Autoregressive reasoning is better described as path-dependent conditional refinement rather than convergence. The model is not “getting more confident by re-reading the prompt.” It is constructing a new context at each step, and its predictions are shaped by the path it has taken.
This process may sharpen the answer distribution: the entropy of the answer given the reasoning trace is often lower than the entropy given only the prompt. But entropy reduction is not the same as correctness. If the model generates an incorrect intermediate step, later predictions condition on that error and may become confidently wrong.
Three levels of computation
A transformer can reason at several different levels:
- Within a forward pass: a single pass through the layer stack can resolve references, classify intent, retrieve memorised facts, or perform simple inferences. Some computations complete entirely inside this one pass.
- Across tokens (chain-of-thought): when the model generates intermediate tokens before answering, each new token triggers another forward pass conditioned on an expanded context. This buys additional serial computation depth.
- Context-conditioned: the user may provide facts, examples, or constraints. Conditioning on genuinely new information can reduce uncertainty in ways that self-generated tokens cannot.
The key distinction is that self-generated reasoning usually adds computation and structure, while externally provided context can add genuinely new information. Both sharpen the answer distribution, but generally through different mechanisms.
The latent-variable view
We think the most useful abstraction is to treat reasoning as inference over latent solution paths. Let \(x\) be the problem, \(z\) a latent reasoning process (a proof, a plan, an algorithm), and \(a\) the final answer. Then:
\(P(a|x) = \sum_{z} P(a|x,z)P(z|x)\)
A direct-answer model tries to marginalise over all possible reasoning paths implicitly — in a single forward pass. A chain-of-thought model usually generates an explicit approximation to one such path and then predicts the answer conditioned on that.
This explains both why chain-of-thought helps and why it can fail. Estimating \(P(a|x,r)\) for a specific reasoning trace \(r\) is often easier than estimating \(P(a|x)\) directly, because \(r\) introduces intermediate variables and constraints. But if the sampled path \(r\) is wrong or biased, conditioning on it pushes the model toward an incorrect answer — it can become more confident because the context is more specific, rather than because it is more true.
As an enhancement, self-consistency methods exploit this view: sample multiple candidate paths and aggregate over the answers. In probabilistic terms, this is a crude approximation to marginalising over multiple possible \(z\)’s rather than trusting one sampled trajectory.
What Is Chain-of-Thought Actually For?
CoT as additional computation
The most obvious benefit of chain-of-thought is computational. A decoder-only transformer has bounded computation per generated token — one forward pass through the layer stack. If the model answers immediately, it must map the prompt to the answer in that single pass. But if it generates \(T\) intermediate tokens first, it gets \(T\) additional forward passes, each conditioned on an expanded context. Chain-of-thought thus buys serial depth at inference time.
Merrill and Sabharwal (2024) made this precise in “The Expressive Power of Transformers with Chain of Thought.” They proved that allowing a transformer to generate intermediate tokens fundamentally extends its computational power, with the expressiveness scaling with the number of intermediate steps. A polynomial number of CoT steps enables transformers to solve exactly the class of polynomial-time problems — something a bounded-depth transformer without intermediate tokens cannot do. The implication is clear: even if the intermediate tokens contained no semantic information at all, the extra forward passes alone could expand what the model can compute.
Does the reasoning trace actually matter?
If the computational depth is the key benefit, a natural question follows: does the content of the reasoning trace play any role, or is it just a vehicle for additional forward passes?
The “dot by dot” result makes this sharper. Pfau, Merrill, and Bowman (2024) showed that meaningless filler tokens — repeated dots — can help transformers solve certain algorithmic tasks that they cannot solve without intermediate tokens. Their conclusion is that additional tokens can provide computational benefits independent of the semantic content of those tokens. The content was empty; but the computation was useful.
There is further evidence from the faithfulness literature. Lanham et al. (2023) systematically measured how much models actually condition on their own chain-of-thought when predicting final answers. Their findings are revealing: models show large variation across tasks in how strongly they rely on their CoT, sometimes heavily conditioning on it, sometimes largely ignoring it. Most telling, as models become larger and more capable, they tend to produce less faithful reasoning — suggesting that stronger models may generate explanatory text while following a predetermined answer pathway. Such a chain-of-thought begins to look more like a post-hoc rationalisation, rather than a causal driver of the answer.
Taken together, these results build a compelling case that the internal recursion — the additional forward passes — contributes significantly to reasoning competence, potentially more so than the semantic content of the reasoning trace itself.
But that is not the full picture
However, it would be premature to conclude that the reasoning trace is merely a vehicle for computation. There are important confounders that complicate this narrative.
The scratchpad as external memory. A transformer’s hidden activations during one forward pass are transient. Without a scratchpad, the model must compress all relevant intermediate computations into the current residual stream. With a scratchpad, it can write intermediate results into the token sequence, and those tokens become part of the context — in implementation terms, they produce key-value cache entries that later tokens can attend to. The scratchpad creates an addressable external memory.
Consider arithmetic:
37 + 48
7 + 8 = 15, write 5 carry 1.
3 + 4 + 1 = 8.
Answer: 85.
The token “carry 1” is not just an explanation. It is a stored variable. Later computation attends to it. By pinning intermediate variables into token space, the model does not need to maintain all intermediate state implicitly in a single compressed hidden representation. It can externalise state into the context and retrieve it later through attention. This is a genuine benefit of the content of the trace, not just its length.
Commitment and discretisation. There is another subtle role: the scratchpad turns soft latent possibilities into explicit symbolic commitments. Before writing an intermediate result, the model may have a distributed representation containing several possible latent paths. Once it writes “The carry is 1,” future predictions are conditioned on that discrete commitment. The model has selected a path.
This can help — it reduces the space of downstream possibilities and makes the remaining computation simpler. But it can also harm. If the model commits to the wrong intermediate result, subsequent tokens build a coherent but incorrect continuation. The reasoning thus becomes confidently wrong because the commitment was wrong.
This trade-off between commitment and flexibility points to something important. Research on latent reasoning suggests that continuous latent representations can maintain multiple possible reasoning paths simultaneously rather than committing to one. Hao et al. (2024) showed in COCONUT that continuous thought vectors can encode multiple alternative next steps at once, enabling the model to perform what is essentially breadth-first search over the solution space — exploring many possibilities in parallel rather than committing to a single depth-first path as explicit CoT does. This idea has been further developed at ICLR 2026 by work on continuous chain-of-thought (\(CoT^2\)), which establishes theoretically how continuously-valued tokens enable models to track multiple discrete traces in parallel within a single inference pass.
Scratchpad tokens are not necessarily faithful reports of reasoning, but they can be active components of reasoning.
So the picture could be genuinely complex. If the reasoning trace is not just a vehicle for forward passes, but neither is it a faithful transcript of internal computation, then the truth could sit uncomfortably in between. Understanding where exactly it sits may be crucial for designing the optimal form of reasoning architecture. This is one of our future research directions to investigate.
In the meantime, it is useful to think of explicit CoT and latent reasoning as two ends of a spectrum.
On one end, chain-of-thought externalises everything: intermediate steps are visible tokens that provide computation, memory, and discrete commitments — but at the cost of path commitment and potentially unfaithful traces. On the other end, latent reasoning internalises everything: iterative refinement happens entirely in hidden representation space, with no visible tokens, no discrete commitments, and the ability to maintain multiple reasoning paths simultaneously.
Neither extreme is necessarily the right answer. The optimal form of reasoning may sit somewhere in between — perhaps combining the computational depth of latent iteration with selective externalisation of key intermediate state. Our goal is to verify where the balance lies, and then find it.
In the meantime, studying the latent extreme is instructive. This is what looped transformers do.
From Scratchpad to Latent Loop
The Tiny Recursive Model (TRM) is a concrete instantiation of this idea. Instead of generating explicit reasoning tokens, TRM maintains two latent state vectors (\(z_H\) and \(z_L\)) and iterates them through a learned update function. The “scratchpad” is the hidden state itself, updated through 3 outer cycles and 4–6 inner cycles. No tokens are emitted during reasoning — the refinement happens entirely in representation space.
The scale context is striking. TRM has roughly 7 million parameters. For reference, GPT-2 Small has 117 million. This is not a large model thinking hard; it is a tiny model thinking repeatedly. And yet it outperforms models orders of magnitude larger on ARC-AGI, a benchmark specifically designed to test abstract reasoning and generalisation.
The recursive process — not scale — appears to be the key ingredient.
This raises a natural question. If the power comes from the loop, does the specific operator being looped matter? TRM uses standard Transformer blocks: attention layers for cross-position communication, MLPs for per-position computation. But attention is not the only option.
Mamba-2, a state space model, processes sequences through a recurrent state update:
\(h_t = a_th_{t-1} + B_tx_t\)
where the parameters are input-dependent, allowing the model to selectively propagate or forget information. This recurrence is itself a form of iterative refinement. There is a conceptual elegance to putting an inherently iterative operator inside an iterative loop — recurrence within recurrence.
The practical question is whether Mamba-2 can enter the design space of operators for recursive reasoning without degrading capability. We tested this directly.
Swapping the Operator: Results on ARC-AGI
In our workshop paper, published at the Latent & Implicit Thinking Workshop at ICLR 2026, we replaced the Transformer blocks in TRM with a Mamba-2 + Attention hybrid operator. We maintained parameter parity as the key constraint. The original TRM-attn has 6.83M parameters, and our hybrid TR-mamba2attn has 6.86M. We kept the same recursion schedule, same state representation, and same evaluation protocol.
The headline result on ARC-AGI-1 is as follows:
| K | TRM-attn | TR-mamba2attn | Delta |
|---|---|---|---|
| 1 | 40.75 | 40.50 | -0.25 |
| 2 | 43.88 | 45.88 | +2.00 |
| 5 | 49.25 | 51.88 | +2.63 |
| 10 | 52.13 | 54.50 | +2.37 |
| 100 | 60.50 | 65.25 | +4.75 |
| 1000 | 65.50 | 69.75 | +4.25 |
The hybrid improves pass@2 (the official ARC-AGI metric) by +2.0%, and the advantage grows at higher K values, reaching +4.75% at pass@100. Meanwhile, pass@1 is near-parity.
This pattern is consistent throughout training — it is not a late-training artefact:
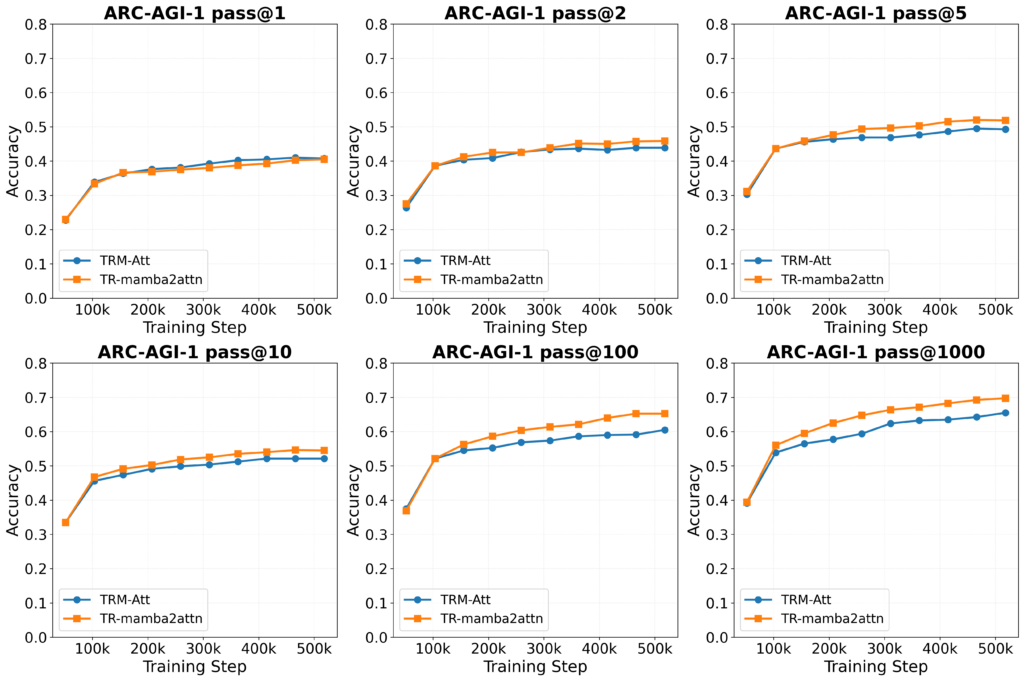
Coverage vs selection
The pass@K pattern also reveals a potential coverage vs selection trade-off. The hybrid generates the correct solution within its candidate set more often (better coverage), but both models rank the correct solution first at similar rates (similar selection).
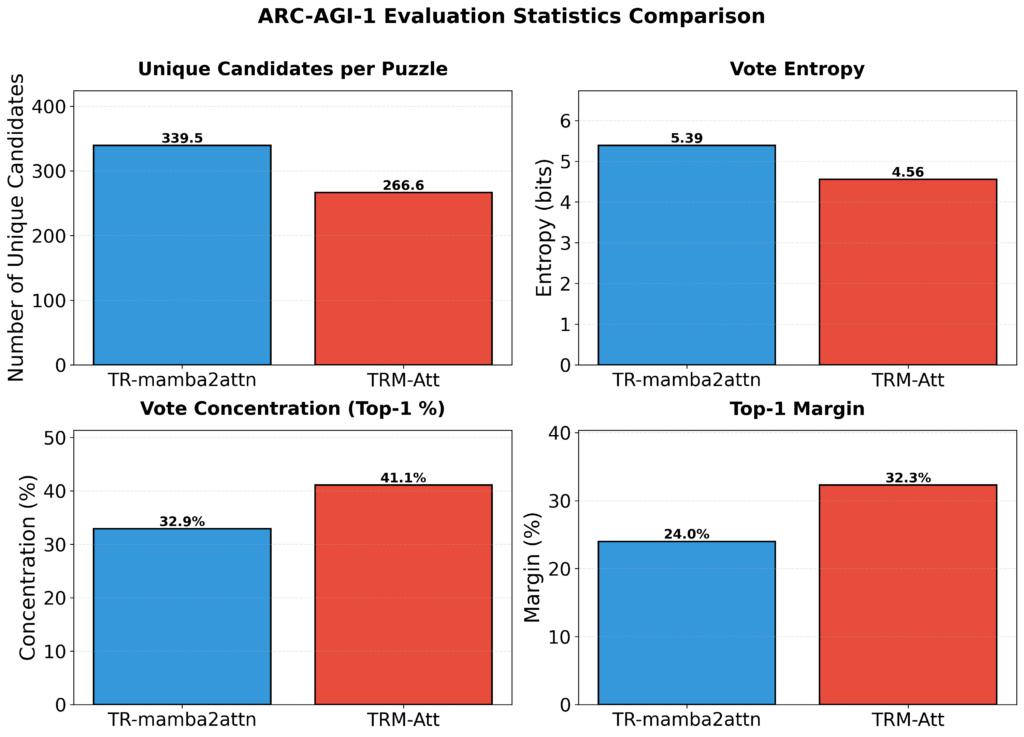
The hybrid generates 27% more unique candidates per ARC AGI puzzle (339.5 vs 266.6) with higher vote entropy (5.39 vs 4.56 bits). Conversely, TRM-attn concentrates 41.1% of votes on its top-1 candidate (vs 32.9% for the hybrid) with a larger top-1 margin (32.3% vs 24.0%).
Mamba-2’s sequential processing appears to contribute different solution trajectories during augmentation, increasing the diversity of the candidate pool without degrading the quality of the best prediction. It seems like the hybrid explores more, while the Transformer commits.
This would map directly onto the conceptual framework: the hybrid is perhaps stronger at search over solution paths, while the pure Transformer excels at discrete commitment.
The results on other benchmarks add nuance. On Sudoku (small 9×9 grids), dense all-to-all mixing via MLP-t blocks outperformed both attention and hybrid models, suggesting constraint satisfaction benefits from a different communication pattern. On Maze (large 30×30 grids), the hybrid achieved 80.6% vs 60.8% for TRM-attn, though training instability makes these results preliminary. It seems that different operators suit different tasks.
What This Tells Us
The coverage vs selection trade-off is not just a quirk of one benchmark. It reflects something deeper about how different operators shape the distribution over latent reasoning paths.
Return to the latent-variable view: \(P(a|x) = \sum_z P(a|x,z)P(z|x)\). Different operators induce different distributions over \(z\). A broader \(P(z|x)\) means more diverse reasoning paths, which helps when you can marginalise over them — self-consistency, best-of-N, pass@K evaluation. A sharper \(P(z|x)\) helps when you need to commit to one path — greedy decoding, pass@1.
The practical implication might be that the best operator for recursive reasoning may depend on your inference-time compute budget. If you can sample many candidates, diversity wins. If you get one shot, decisiveness wins.
This is reinforced by a difficulty-stratified analysis from the paper. On hard puzzles (where neither model reliably produces the correct answer), the hybrid gains +4.9 percentage points at pass@5 over TRM-attn — its flatter vote distribution avoids concentrating on a single dominant-but-wrong candidate. On easy puzzles, the pattern reverses: TRM-attn’s sharper concentration more reliably promotes an already-dominant correct answer to the top rank.
Perhaps most telling is that at pass@5, the two models solve partially disjoint puzzle sets — 31 hybrid-only vs 23 TRM-attn-only. Different mixing strategies contribute complementary strengths. At least given our current understanding, the operators are not interchangeable, but appear more complementary.
For the full experimental details, architecture diagrams, and analysis, see the paper: Tiny Recursive Reasoning with Mamba-2 Attention Hybrid, published at the Latent & Implicit Thinking Workshop at ICLR 2026.



