How we built an AI shopping agent around ecommerce product catalogs
AI agents are remarkably good at answering questions. But shopping isn’t really about answers. It’s about navigating a space of products, constraints, and tradeoffs, balancing open-ended discovery with a pointed intent to buy. We recently built an AI ecommerce agent powered by Fin, Intercom’s AI agent, around this insight.
Our ecommerce agent browses product catalogs, answers shoppers’ questions, recommends products, and helps customers find exactly what they’re looking for. Although rooted in years of learning and experience obtained from our customer service offering, the ecommerce agent required us to rethink how we approach retrieval-augmented generation for structured domains that have richer information than what is represented in a flat collection of documents.
Fin already uses RAG to answer customer queries from existing documentation. For unstructured knowledge queries such as “How do I reset my password?” or “What’s your refund policy?” embedding-based retrieval works remarkably well. The question and the answer are semantically similar, and vector similarity does the rest. But product catalogs are a different beast. They come with rich pre-existing structure: category hierarchies, typed prices, stock levels, variant relationships, collections that encode merchandising intent. Shoppers have hard constraints (e.g. budget, size, discounts) – that can’t be approximated by embedding similarity. Flattening all of this into a vector space loses information that was already there.
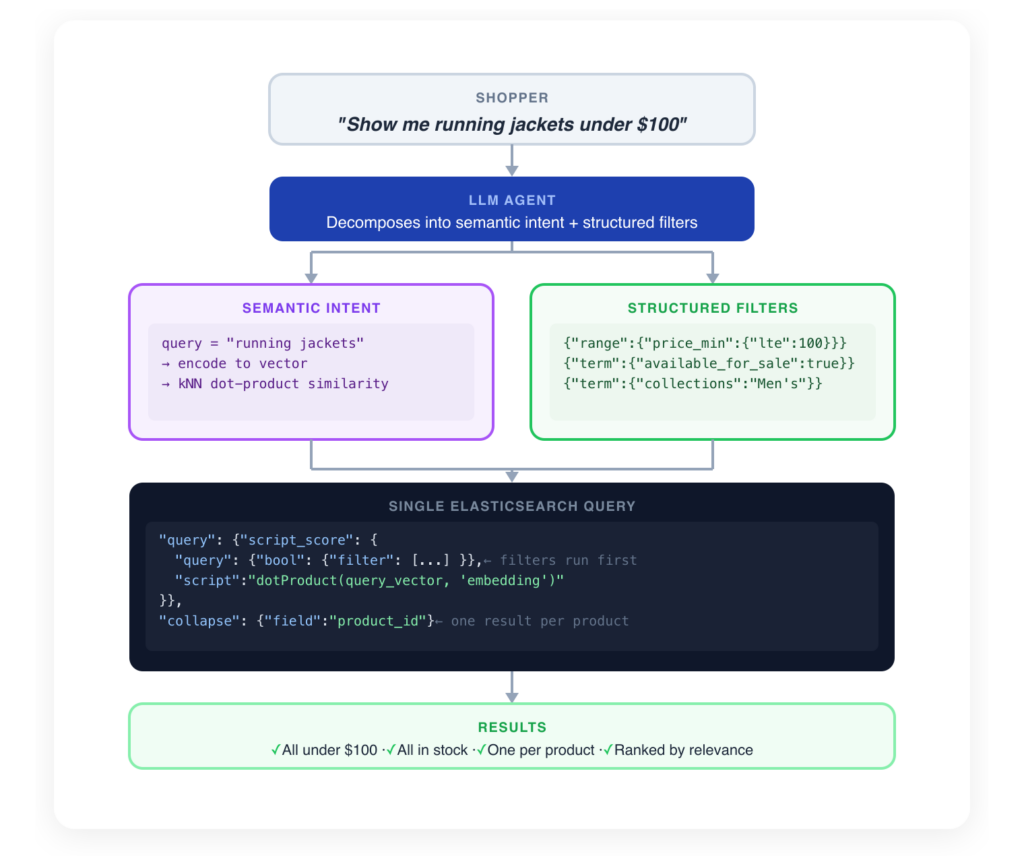
So we built a structured, agentic RAG system that preserves and exploits the inherent structure of product catalogs. On the retrieval side, semantic search handles the soft, intent-driven part of a query while deterministic filters enforce hard constraints like price ceilings and stock availability. The two combine in a single Elasticsearch query: structured filters narrow the candidate set first, then vector search ranks the survivors by relevance. Here’s the overall picture:
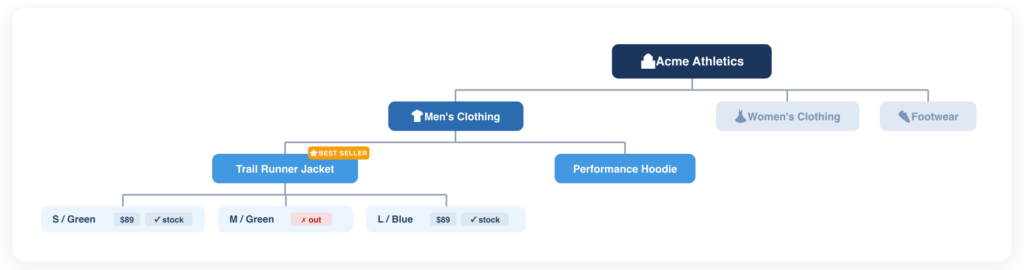
A product catalog is a tree, not a document collection
A product catalog is a tree of categories, collections, products and variants. Variants being the purchasable leaf nodes with attached metadata such as prices, discounts and stock states. Each level in the tree encodes useful information. “Best Sellers” is a signal about popularity. “Men’s Clothing” reduces the search space before a single query is issued. The relationship between a shirt in Small and the same shirt in Large is structural, i.e. they share a product identity, differ on a typed attribute, and have independent prices and stock levels. Knowing these relationships enables more flexibility in shopping conversations – “I only have that in medium, small and large are out of stock”.
When you run this catalog through a standard RAG pipeline, the tree gets flattened. Each product page becomes one or more text passages. The hierarchy disappears. The price becomes a substring in a paragraph. The variant relationship becomes incidental overlap in embedding space. The retrieval system no longer knows that two passages describe the same product in different sizes, it just knows they have similar vectors.
This flattening is fine when the user’s question is semantic: “What material is this jacket made of?” But it breaks down the moment a shopper’s question involves structure, e.g. “Show me running jackets under $100 in medium”.
Here are some of the concrete patterns that we saw.
The undecided user. A new customer arrives at a jewelry store and says, “What do you sell?” The agent has no preferences to work with and needs to make a smart first move. With flat RAG, the agent attempts a query like “representative products” and gets back essentially random items, because semantic similarity on a vague query produces no strategic ranking. Once we gave the agent structured catalog tools, it discovered the store’s “Best Sellers” collection, used it as a prior, and surfaced a varied mix of bracelets, earrings, and necklaces. The collection acted as domain knowledge the flat system simply couldn’t access, and the shopper got a recommendation that felt curated.
The variant flood. A customer asks, “Show me some men’s clothing.” With flat RAG, the top-K retrieval budget of semantic search over the full catalog is overwhelmed by multiple variants of the same product. The product carousel collapses to a single independent item. With structured search, the agent scopes the search to a relevant subset by using a relevant category/collection e.g “All Men’s Products”, and returns a varied set of shirts, hoodies, and jackets. Pre-filtering on the collection dramatically reduced the candidate set thereby improving precision. The shopper sees five distinct, relevant products instead of one.
The hard constraint. A customer asks for “blue shirts under $50 in Medium.” Price is a hard constraint, not a soft preference. Semantic similarity cannot enforce a price ceiling via embeddings alone. With a fixed number of retrieval slots, expensive shirts with strong text matches crowd out cheaper alternatives that actually satisfy the constraint. With structured filtering, price is a pre-filter. Products above $50 are excluded before ranking even begins.
These aren’t edge cases. They’re the normal shape of shopping conversations: broad exploration, filtering on typed attributes, and navigating variant relationships:
| Query type | Flat RAG | Structured search |
|---|---|---|
| Broad exploration (“What do you sell?”) | Random text-matched products | Category tree → strategic starting point |
| Filtered search (“Under $50”) | Can’t enforce; price is text | Pre-filter → exact numeric constraint |
| Variant-heavy catalog | Same product fills multiple slots | Per-product deduplication → one result per product |
| Variant comparison (“128GB vs 256GB”) | No concept of sibling variants | Explicit product→variant traversal |
| Stock correctness | Product-level text hides variant-level truth | Variant-level stock checked before recommendation or cart |
Hybrid search: semantic retrieval meets structured filtering
The architecture we built for Fin decomposes every product search into two parts: a semantic intent and a set of hard constraints.
Data ingestion
We index product descriptions as usual text passages for vectorisation, but keep several other typed metadata fields alongside each text chunk. E.g. price, categorisation taxonomy, stock availability, discount status and variant structure. Every passage carries its full metadata into the index. Products sync from Shopify via bulk import jobs during onboarding and webhooks on product updates so the index stays current as merchants update their catalogs.
Querying
At query time, the agent specifies both a semantic intent and optional hard constraints. The semantic intent such as “leather jacket”, “running shoes”, “gift for mom”, “beach holiday look” gets encoded into a vector and matched via kNN similarity, the same way flat RAG works. The hard constraints such as price < 150, collection = “Kids”, discounted = true get translated into deterministic ElasticSearch filters that are applied before the vector search runs.
This is a filter-then-score architecture. Structured filters narrow the candidate set first, removing products that can’t possibly satisfy the constraints. The vector search then ranks only the survivors by semantic relevance. With a fixed top-K budget, every slot that might have been occupied by an irrelevant product is now available for a relevant one.
Product Category Tree Expansion. We also give the agent capability to explore nested product categories. A product categorised as “Animals & Pet Supplies > Live Animals” gets indexed with expanded prefix paths, both “Animals & Pet Supplies” and the full path, so a filter on the parent category matches products at any depth in the hierarchy. The agent can search at whatever level of specificity the conversation demands.
Why ElasticSearch is a natural fit? This hybrid approach works because ElasticSearch natively supports combining vector search with structured filters in a single query — no separate systems, no multi-index orchestration. Three capabilities make it practical:
- First, structured filters can be combined with vector scoring in a single query. Filters run in boolean filter context — binary match-or-don’t, not scored, faster than full-text queries, and cacheable. Documents that fail the filter never reach the vector comparison.
- Second, field collapsing deduplicates results on a metadata field at query time. One best passage per product, no post-processing needed.
- Third, terms aggregations let us discover catalog structure without searching at all. A single aggregation on the category tree returns the store’s entire category distribution with product counts, giving the agent a map of the catalog before it issues a single search query.
The net effect: a single index serves both the semantic and structured sides of every query. The agent’s tools translate shopper intent into ES queries that combine embeddings based (soft) similarity with deterministic filters, and it all runs in one network round-trip.
Tools that match the domain’s shape
Structured data in the index isn’t enough on its own. The agent also needs tools whose interface reflects how shoppers actually navigate a store. Users browse, ask questions, compare, and narrow down. We used two tools that mirror this:
- Browse Product Categories/Collections: returns the store’s category tree with catalog share percentages. It enables top-down exploration: “What do you sell?” The agent sees that 70% of the catalog is Clothing, 15% Bags, 15% Accessories and can make an informed opening statement instead of guessing. It enables the agent to see promotional content such as a “Best Sellers” collection. This is how the agent knows to start off with good defaults if the customer has not expressed any preferences.
- Search Product Catalog: is the hybrid search workhorse. It accepts a natural language query plus optional hard filters and returns relevant products with variant vocabulary information (“available in 5 sizes and 3 colours”). The agent can then choose to get detailed information on a specific variant. This two-stage hierarchical approach keeps the agent’s context focused on discovery rather than drowning in details of all other variants that the shopper hasn’t asked about.
Agent behavior
Good tools aren’t enough if the agent calls them naively. A shopping conversation has a natural arc from open-ended browsing to a specific purchase decision. The agent needs to recognize where the shopper is in that arc to decide what to do next and to balance between exploratory discovery and a targeted intent to sell.
Shopping phases as agent planning. The agent doesn’t just call tools reactively, it tracks where the shopper is in their purchase journey and adjusts its behaviour accordingly. We define four phases:
- Exploring: The shopper’s intent is broad or unclear. The agent leads with category browsing and asks clarifying questions to narrow scope.
- Detailing: The shopper has identified products of interest. The agent drills into variants to surface specific pricing, availability, and discount information.
- Narrowing: The shopper has expressed preferences (size, color, price range). The agent stops expanding the search, highlights specific products and offers to add to cart.
- Selling: Customer has identified what they want. The agent confirms the choice, and offers to add to cart.
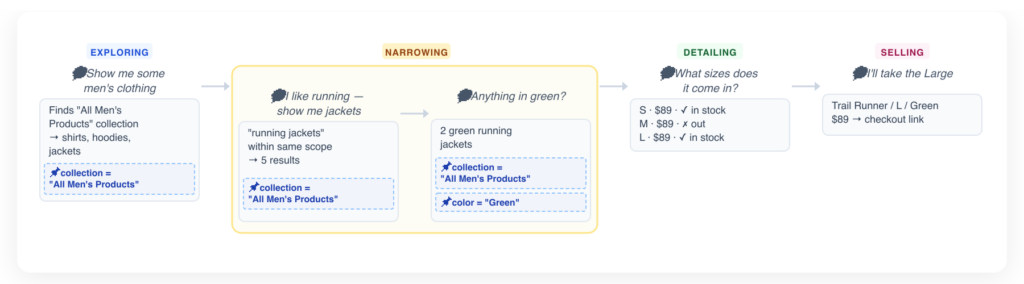
This phased model gives the agent a lightweight planning framework — it knows when to explore broadly, when to dive into detail, and when to stop showing new products and attempt to close the sale.
Behavioral grounding from browsing context. When a shopper has a product page open while chatting, the agent receives the current page URL as silent context. It parses signals such as product name, variant information etc from the URL and uses this to inform its first tool calls. If a customer says “Is this available in blue?” while viewing a specific jacket, the agent already knows which product they mean without asking.
Structured output for product carousels. When the agent decides to recommend products, it emits structured XML tags containing serialised carousels. These tags get post-processed into visual product carousels in the chat interface with images, prices, contextual descriptions (why this product is recommended) and other UI elements. The LLM generates the recommendation logic, the XML format bridges text generation to interactive UI.

No free lunch
Structured search isn’t free, multiple tool calls add latency compared to single-shot RAG. Maintaining structured metadata alongside embeddings is more complex ingestion than pure text chunking. And structured search is only as good as the structured data: if a merchant doesn’t categorise their products, the structured filters add no value — though the system degrades gracefully to pure semantic search rather than breaking.
We accept these costs because structured pre-filtering produces smaller, higher-signal product recommendations.