
We designed a topic modelling system to improve the Fin AI agent by detecting underperforming areas, identifying root causes, and enabling continuous optimisation.
We wanted to get the quality benefits of modern generative AI, and the scalability and reliability of machine learning based approaches.
This blog describes how we achieved the following progress:
- Topic modelling is good for extracting themes from large text corpora. However, support conversations are short, noisy, and informal, which poses a lot of unique challenges
- To address this, we adopted an embedding-based clustering approach with HDBSCAN (which avoids predefined cluster counts and adapts to each customer’s vocabulary, volume, and complexity)
- Using a bottom-up hierarchy, the system organically discovers emerging topics – such as new feature friction or early bugs – without requiring prior labels
- Finally, we layered generative AI on top of the unsupervised structure to name topics, summarise intent, and surface examples
- This hybrid approach transforms messy support conversations into actionable insights
Introduction
Support conversations are messy – tickets and messages flood in daily, full of critical feedback and pain points. They’re also fragmented and hard to summarise at scale. We wanted to turn this chaos into clarity: transform raw conversation data into a structured, actionable view of what customers are saying.
Our solution combines classic machine learning with generative AI to automatically detect and label topics within support conversations. These topics give teams a clear lens to understand user behaviour, spot issues early, and take action. Originally built for Fin, our AI agent, the system began as a feedback loop:
- Detect topics with low AI performance (low resolution rate), frequent handoffs, or poor satisfaction
- Analyse representative conversations
- Act – update knowledge, add tasks, refine workflows
- Measure results
- Repeat
This cycle still powers how topics drive improvement, and is very useful. But we soon realised that topics were more than a debugging tool – they became a shared language across teams: support specialists, analysts, engineers, managers, and product marketers. Topics can be very useful for…
- AI Content Managers: to track which topics Fin handles well vs. those needing training or escalation (i.e. using performance data to prioritise improvements)
- Data Analysts: to monitor trends over time and user segments (e.g., perhaps refund issues are spiking; or there are more onboarding questions than expected post-release)
- Technical Support Engineers: to identify clusters of related bugs, measure scope, and track how long issues persist
- Support Managers: to see ticket volume by topic, to allocate support resources, and evaluate operational metrics across categories
- Marketing and Sales: to spot patterns in product questions to refine messaging, improve docs, and surface recurring feature requests
- …even more roles in future. Topics have proven flexible and interpretable, powering both day-to-day workflows and higher-level strategic decisions.
Pipeline Overview
Practical Challenge
Topic modeling has decades of research behind it. At its core, it finds abstract themes – or “topics” – within large text collections without labeled data. It’s been applied everywhere from academic literature and news clustering, to social media and network analysis.
However, conversational data is different. Support chats and assistant transcripts are short, noisy, and informal – far from the structured documents most models were built for. Our challenge was to adapt topic modelling to this messy reality and make results both accurate and useful for business teams. We also had to ensure it could scale.
Choosing the Right Modelling Approach
We treated this as a feasibility analysis – not just a technical evaluation, but a product development challenge. The right model needed to balance accuracy, interpretability, performance at scale, and business usability:
| Method | Pros | Cons | Verdict |
|---|---|---|---|
| Latent Dirichlet Allocation (LDA) | – Interpretable topic-word distributions – Probabilistic foundation | – Performs poorly on short texts due to data sparsity – Requires strong word co-occurrence – Sensitive to hyperparameters – Often yields generic/overlapping topics | ❌ Not suitable for conversational data |
| Non-Negative Matrix Factorization (NMF) | – Fast and simple – More interpretable than LDA – Can work better on short texts than LDA | – Still bag-of-words based – No semantic understanding – Misses contextual or synonymous terms | ⚠️ Fast, but too limited for our needs |
| Embedding-Based Clustering | – Captures semantic meaning – Works well on short, noisy text – Highly flexible (model, clustering, reduction options) – Produces interpretable structure | – Requires tuning – Sensitive to clustering and dimensionality settings – May group by style or length, if not tuned | ✅ Best balance of structure + accuracy |
| Rule-Based / Keyword Tagging | – Transparent and easy to implement – Its issues are well known – Can be a quick win | – Doesn’t scale well – High maintenance – Misses nuance or novel phrasing | ❌ Too brittle for evolving topics |
| Zero/Few-Shot Classification with LLMs | – No training data needed – Fast experimentation – Leverages broad model knowledge | – Limited control – Poor for fine-grained or large topic sets – Not good for discovering unknown topics | ⚠️ Useful for small-scale tasks, not topic discovery |
| Supervised Classification | – High precision for known categories – Good for feedback loops and continuous improvement | – Requires labeled data – Can’t handle emerging or unknown topics – Not useful for discovery | ⚠️ Can be a complementary tool, but not good for discovery |
After exploring approaches mentioned above, we ultimately chose embedding-based clustering because it struck the right balance between flexibility, scalability, and performance. Unlike rule-based methods or supervised classification, it allowed for fully unsupervised exploration – critical for surfacing unknown or evolving topics without relying on predefined labels.
In our initial tests, traditional models like LDA or NMF struggled with short, noisy text, while embedding-based methods handled conversational nuance far better. Just as importantly, they scaled easily to millions of conversations. When we tested it, it just worked – producing coherent, interpretable topics out of the box.
So we made a bet on this method, and it paid off!
How It Works: A High-Level View
Each customer gets a tailored topic model that breaks their conversations into distinct themes. Topics and subtopics are linked to key metrics like CSAT and resolution rate, and teams can drill down to review individual conversations or apply filters to explore trends. Here is how it looks in the UI:
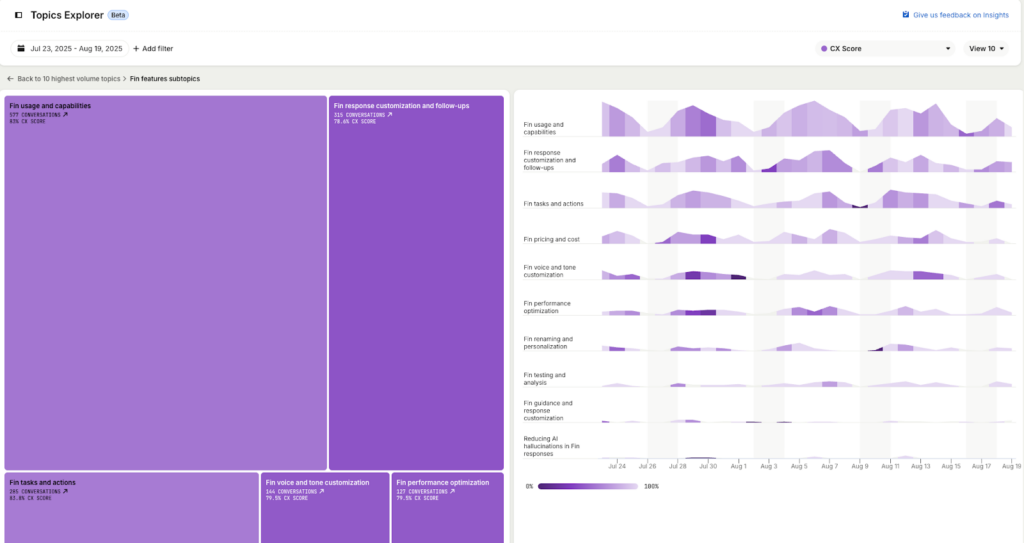
Here’s a simplified view of how it works under the hood:
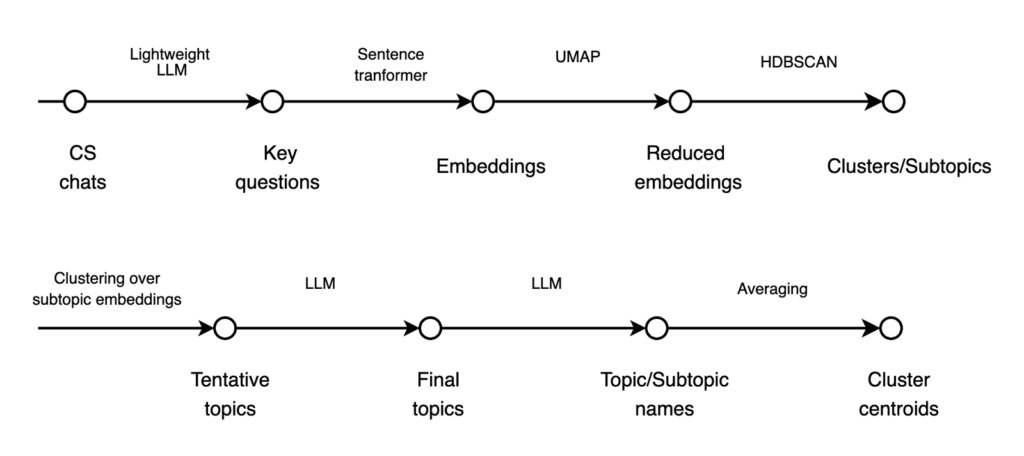
The upper part of the picture is subtopic discovery. It is based on BERTopic framework, and here’s what it does:
- Extract key questions – A lightweight LLM summarises the main questions from CS chats
- Embed questions – A sentence transformer converts key questions into vector embeddings (we settled on sentence-transformers/all-MiniLM-L6-v2, based on speed and quality)
- Reduce dimensions – UMAP (particularly effective for short-text data) projects the embeddings into a lower-dimensional space
- Cluster into subtopics – HDBSCAN groups the reduced embeddings into coherent clusters/subtopics
The rest is topic aggregation:
- From subtopics to topics – Clustering on subtopic embeddings surfaces higher-level, tentative topics
- Refine with LLM – An LLM polishes tentative topics into a definitive set of final topics
- Name topics & subtopics – Another LLM generates clear, human-readable labels, based on the final topics
- Compute centroids – Average embeddings define centroids for each cluster (topic/subtopic)
Why HDBSCAN Beats K-Means for Conversational Data
A pretty natural question is why didn’t we use well-known K-Means for clustering?
Overall, we found embeddings and dimensionality reduction methods had only marginal impact, while clustering algorithms and hyperparameters made the biggest difference in output quality. The main advantage of HDBSCAN for our purposes is that it doesn’t require a predefined number of clusters. That flexibility was essential – each customer needs a unique topic model, and support volume, vocabulary, and conversation style vary widely (which results in very different number of topics for different customers).
The key parameter we tuned was min_cluster_size, which sets the smallest number of messages that can form a cluster. Lower values create more granular clusters; higher values produce fewer, broader ones. We settled on 15 as the minimum, which for our own Intercom data surfaced more than 700 micro-topics – a reflection of how diverse support conversations can be. Cluster counts also scale naturally with company size: more traffic means more clusters. This reinforced our intuition that fixing the number of clusters upfront wasn’t an option.
Here’s a relationship between company size (measured by 3-month conversation volume) and number of discovered subtopics. Larger companies with more diverse customers naturally yield more granular clusters – validating our choice of HDBSCAN’s adaptive approach over fixed cluster counts:
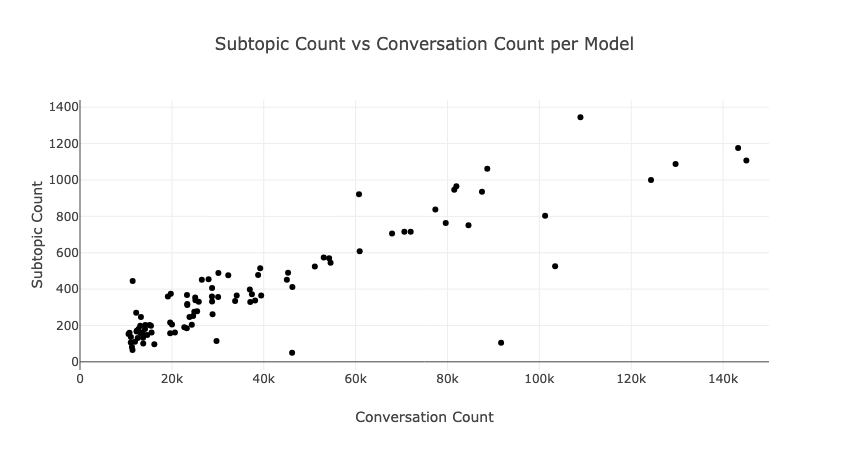
Another advantage of HDBSCAN over K-Means is how it handles noise. K-Means forces every data point into a cluster – even outliers – and offers no confidence scores. HDBSCAN, by contrast, assumes noise exists and can explicitly flag it. In customer support, many one-off or unusual questions don’t fit neatly into a topic. HDBSCAN’s ability to mark these as outliers, with associated scores, is invaluable for managing such edge cases.
From Subtopics to Topics: Building a Bottom-Up Hierarchy
Now let’s get to the second part of the pipeline: topic aggregation.
Many systems define topic hierarchies top-down: decide the categories first, then slot everything in. That works if you already know what to expect – but support data is full of surprises. We wanted the opposite: a bottom-up approach where the data speaks first, surfacing themes customers may not anticipate. The process starts with fine-grained subtopics, discovered via embedding-based clustering with HDBSCAN (as described above). Each subtopic captures a narrow slice of intent:
– Message: “What is the price for resolutions?”
→ Subtopic: Fin resolution rate
– Message: “What model does Fin use under the hood?”
→ Subtopic: Fin LLM usage
While different in detail, these subtopics both belong to the broader Fin topic. The challenge was: how do we automatically group subtopics into meaningful parent topics?
We first tried HDBSCAN’s hierarchy features, but the results were too coarse and inconsistent. So we reapplied our pipeline – this time clustering subtopic embeddings (mean sentence vectors). To our surprise, it worked: fine-grained Fin-related subtopics clustered under “Fin,” and so on. This recursive clustering produced flexible, two-layer hierarchies that adapt to each customer’s data – without predefined categories.
Still, the second clustering wasn’t perfect. To refine it, we added an LLM step: cleaning up inconsistencies, correcting edge cases, and generating clear, human-readable topic names. We layered generative models on top of the unsupervised structure so each cluster becomes understandable and actionable. The LLM helps by:
- Flagging spam or irrelevant data
- Naming subtopics and topics
- Summarising clusters in plain language
- Highlighting representative examples
This hybrid approach gives us the best of both worlds: the scale of ML with the fluency of generative AI.
Conversational Data
Traditional topic modeling was built for long-form, structured text – like news articles or research papers. But conversations don’t follow those rules. They are:
- Short & fragmented – messages like “It’s not working” or “login fails” lack standalone context
- Informal & messy – typos, abbreviations, emojis, and non-standard grammar are the norm
- Multi-turn & multi-speaker – dialogues jump between issues across several back-and-forths
- Contextual & implicit – meaning often depends on prior messages or hidden intent
In other words, applying standard NLP pipelines to chats is like trying to summarize a movie from random one-liners. We had to rethink preprocessing, clustering, and even how we evaluate topic quality.
Preprocessing
Greetings, disclaimers, brand names, agent scripts, typos, and pleasantries can easily swamp the real signal. Without preprocessing, clustering just produces giant, meaningless groups like “Hi, I have a question.” So we built a preprocessing pipeline that goes beyond standard NLP cleanup:
- Remove brand names & boilerplate. Frequent mentions (e.g., “Intercom”) or scripted phrases skew clusters, creating vague, oversized groups that add no real insight
- Extract main messages & collapse turns
– A lightweight LLM pinpoints the messages that carry intent – what the customer wants, the issue they face, or their reaction
– When individual turns are too short or vague, we combine related ones to form richer inputs – especially helpful when intent unfolds gradually across a chat - Spam filtering. We use a lightweight LLM to filter out irrelevant conversations that aren’t related to customer support from our training data
- “Classic” text cleaning. Lowercasing, punctuation handling, stop word removal, typo normalisation, emoji stripping (or translation), etc.
Most of these are self-explanatory, but here’s an example of what step #2 does:
| Raw Conversation | Preprocessed Output |
|---|---|
| User: Hi AI: Hello, how can I help you? User: I have a question AI: I’m here to help you User: Fin User: What is the price? | What is the price for Fin resolution? |
Inference
Our inference strategy was heavily inspired by BERTopic. Instead of running the full sequence of trained models (Embeddings → UMAP → HDBSCAN) for each new conversation, we opted for a simpler, faster, and more production-friendly method: centroid-based inference.
- Cluster representation. After training, each discovered cluster is represented by a centroid – the mean embedding of all conversations in that cluster
- New conversation processing. At inference time, we:
– Assign the conversation to the closest cluster, based on the highest similarity score
– Embed the new conversation using the same sentence transformer
– Compute cosine similarity between the new embedding and all cluster centroids - Confidence thresholding. We define a minimum similarity threshold. If no centroid crosses this threshold, the conversation is considered out-of-distribution and flagged as a potential new or unknown topic.
Switching to centroid-based representations gave us high-throughput, real-time inference with a compact model. But it came with risks. Unlike HDBSCAN, which supports arbitrary cluster shapes, centroid methods assume clusters are roughly spherical. That’s not always the case – some clusters are elongated or multi-modal, so the centroid may sit outside the densest region, reducing accuracy. To check this tradeoff, we analysed cluster geometry to confirm they were compact enough to make centroids a reliable shortcut.
Our geometry analysis confirmed the trade-off was worthwhile: clusters were compact enough for centroids to serve as reliable shortcuts; click to minimise this section, if you want to skip this detail.
To validate that centroids could reasonably represent our clusters, we needed to check if those clusters were roughly spherical – i.e., compact, well-distributed around a center, and not elongated or fragmented. We used Principal Component Analysis (PCA) and spectral entropy as geometric proxies.
Here are the metrics we calculated for every cluster of multiple customer topic models:
- PCA Aspect Ratio: The ratio between the first and second PCA eigenvalues, measures how elongated clusters are
- PCA Top Variance Ratio: Indicates how much variance is captured by the first principal component
- Spectral Entropy: Quantifies the distribution of eigenvalues, measures how evenly variance is distributed across all components
We performed this analysis across multiple clusters to validate the centroid-based approach, and it showed promising signs:
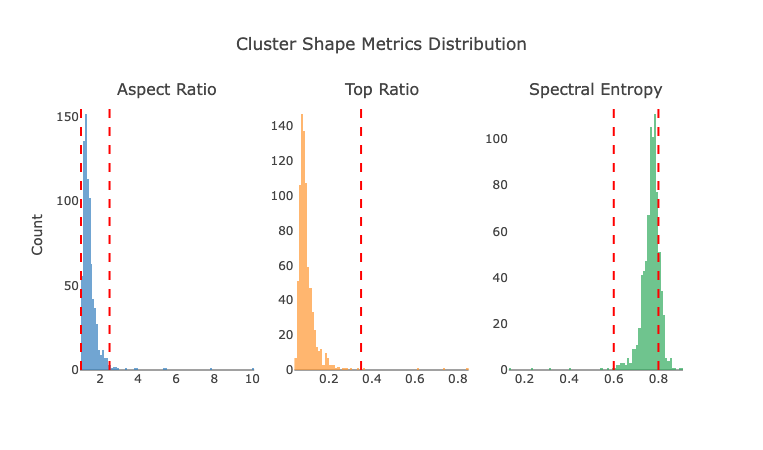
PCA Aspect Ratio & Top Variance Ratio mostly fell in the expected range for spherical clusters (aspect ratio 1–2.5; variance ratio >0.35). Spectral Entropy was more mixed: most clusters scored 0.6–0.8 – egg-shaped rather than round – with some above 0.8, indicating near-spherical shapes.
In practice, this moderate anisotropy didn’t prevent centroids from being effective, especially when clusters were well-separated.
We also visually inspected the clusters to verify their shape, density, and cohesion. While not all clusters are perfectly spherical, both the metrics and visual inspections of samples confirmed that most are compact and coherent enough for centroids to act as reliable representatives:
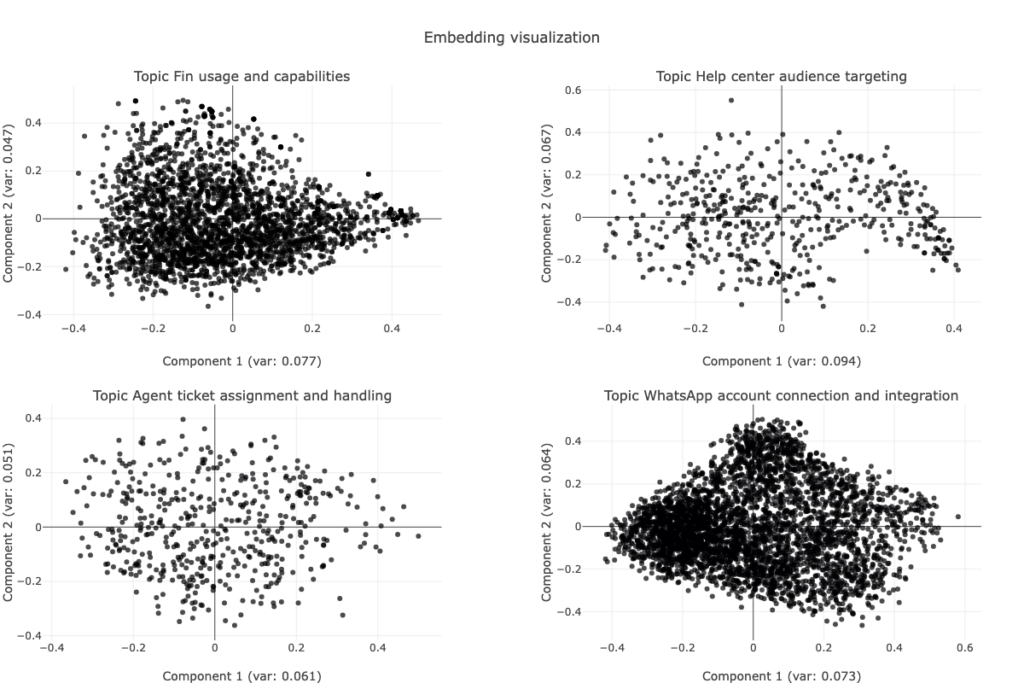
Does it hurt performance? In short – no. To compare inference methods, we used LLM-as-judge: asking an LLM to evaluate whether each subtopic–topic pair accurately captured the theme of a conversation. It’s not a strict system metric, but a useful proxy for human judgment. The results were clear: centroid-based inference performed about 2 points better on average than the full pipeline, with both approaches exceeding 85% accuracy. In other words, simplifying didn’t just hold up – it slightly improved results.
Outlier reduction: switching to centroids cut outliers by 50%, boosting topic coverage. This mattered because support data mixes dense clusters with diffuse, low-density groups. HDBSCAN favors well-defined clusters and often discards the rest as noise – even when those “noisy” points are meaningful. Centroids let us reassign many of those borderline cases to valid topics, improving recall without sacrificing quality.
To balance performance and flexibility, we split the pipeline into two stages:
- Discovery with HDBSCAN – unsupervised exploration to uncover new topics without preset limits.
- Inference with centroids – a fast, similarity-based method optimised for scale
Evaluating Topic Quality
Evaluating topic modelling is inherently difficult. As well as being an unsupervised task, it is also inherently ambiguous. There are many valid ways to split conversations into clusters, and the “best” result often depends on human judgment and downstream usability rather than strict metrics. Still, every ML system needs some form of evaluation. We approached it from multiple angles:
- Clustering quality – Are topics well-separated and coherent?
- Prediction accuracy – Are new conversations assigned correctly?
- Human validation – Do these topics make sense to real users?
Next, we’ll walk you through how we assessed clustering quality, prediction accuracy, and human validation. If you’d rather skip the technical deep dive, feel free to skip – the key takeaway is that our evaluation confirmed the system’s clusters are both coherent and practically useful.
Clustering quality
To evaluate cluster geometry in embedding space, we focused on two cosine-distance metrics:
- Mean Inter-Centroid Distance (Separation). Measures the average distance between cluster centroids. This is critical for centroid-based inference, where close centroids can cause unstable topic assignments
- Higher = better separation → topics are distinct, with less semantic overlap
- Lower = weaker separation → clusters risk blending, making assignments less reliable
- Mean Intra-Cluster Distance (Cohesion). Measures the average distance between messages and their cluster centroid. This shows whether a centroid is truly representative of its cluster
- Lower = stronger cohesion → messages are compact and consistent
- Higher = weaker cohesion → clusters may contain noise or multiple subthemes
Together, these metrics capture the classic trade-off: clusters should be internally cohesive yet externally distinct – a must for our centroid-based approach.
Here’s a plot of these two metrics, with each data point being an Intercom customer:
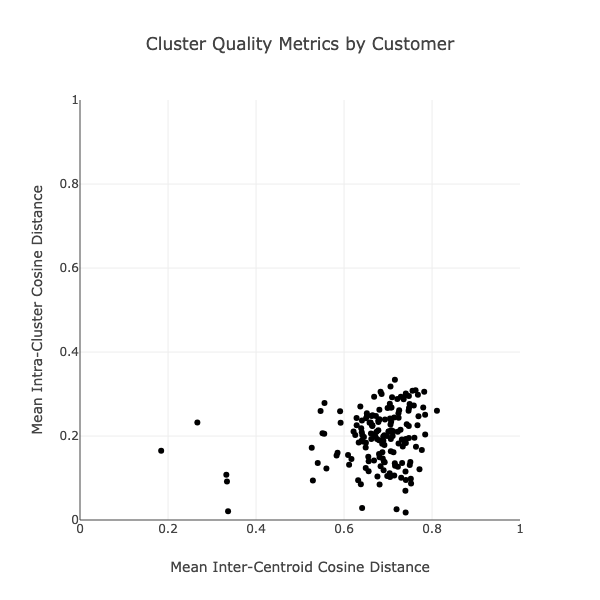
Mean inter-centroid distance falls mostly between 0.6 and 0.8, averaging around 0.75, suggesting strong topic separation. Mean intra-cluster distance ranges from 0.0 to 0.35, with a typical value around 0.2, indicating good cohesion in most cases. We did observe a few outliers – models with lower separation and/or weaker cohesion. These may reflect noisier datasets or edge cases with very small or highly variable support volumes. However, the majority of models fall within an acceptable trade-off zone, showing that our unsupervised clustering approach generalises well across different customers with diverse conversation sets.
Beyond metrics, we ran sanity checks to confirm clusters behaved as expected across datasets:
- Noise Points (Outliers): HDBSCAN flagged ~10–15% of conversations as outliers – reasonable for noisy support data. Too many (50–70%) would suggest the model is overly strict, while too few might mean clusters are too broad
- Uneven Cluster Sizes: another failure mode is one giant cluster swallowing most data, leaving only tiny ones behind – usually a sign of overly permissive parameters
- Cluster Size Distribution: in practice, we saw a J-shaped distribution: many small, focused clusters and a few large, high-volume ones. This matches expectations – most issues are niche, while a handful dominate support traffic:
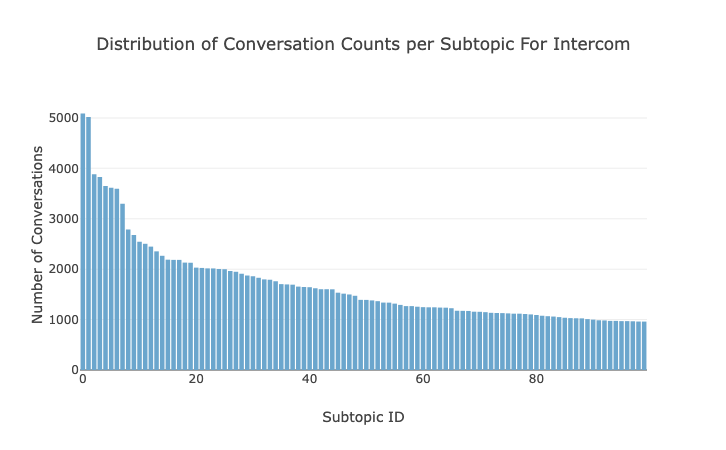
Prediction accuracy
It’s worth emphasising the distinction between cluster discovery and cluster assignment:
- Discovery is about in-sample structure – how well the model can group historical conversations into meaningful topics using unsupervised learning
- Prediction is about out-of-sample generalization – how accurately we can assign new, unseen conversations to the right existing topic.
This framing also highlights one of the most important challenges: deciding when a new conversation doesn’t fit any existing topic. That’s where the similarity threshold plays a key role. If enough conversations consistently fall below that threshold and form a dense region of their own it might signal the need to form a new topic cluster entirely.
To optimize the decision boundary, we inspected the distribution of cosine similarity scores. A threshold of 0.5 provided a good trade-off between precision and recall: above 0.5 = assign to closest cluster; below = flag as unassigned.
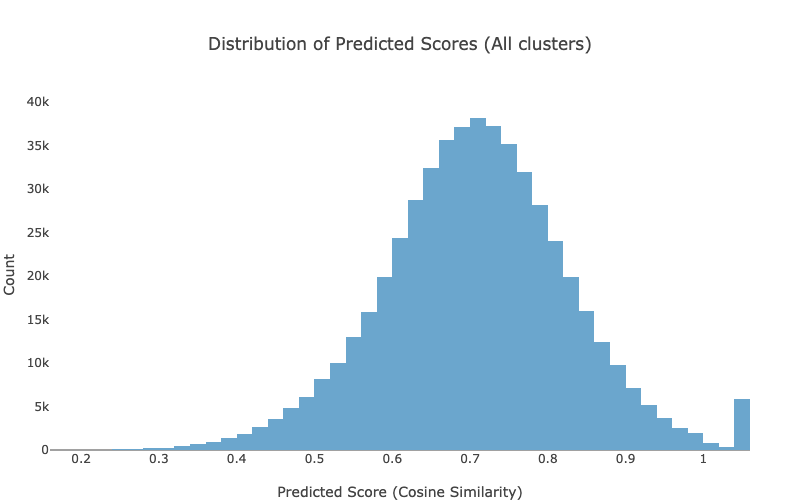
To validate the quality of topic assignments, we used LLM-as-a-judge – a lightweight evaluation method where an LLM was asked: “Does this topic match the conversation theme?”
The model returned a True/False answer, serving as a semantic proxy for accuracy in the absence of ground truth labels. This approach simulates human evaluation and helps assess how well the assigned topic captures the user’s actual intent. We also used this method to cross-validate our cosine similarity threshold. Based on these judgments, we found that a threshold of 0.5 struck the right balance between precision and recall. Overall, assignment accuracy exceeded 85%.
Unassigned: outliers or a new topic? When a new conversation receives a cosine similarity score below 0.5, we assume it doesn’t belong to any existing cluster – and it’s flagged as unassigned. However, that doesn’t always mean the conversation is noise or a rare edge case. Sometimes, it reflects something more important: a new topic that has recently emerged and wasn’t present in the data when the original clusters were created. These unassigned conversations can be early signals – new issues, product questions, or behavioural patterns that haven’t yet been captured by the system. More on how we detect and promote new topics in the next section (Model Updates).
Multi-topic aspect and borderline assignment. We also explored the multi-label nature of conversational data – since it’s well understood that a single conversation can touch on multiple topics. There are two main reasons for this:
- In longer conversations, the topic can naturally change over time. To handle this, we extract multiple key messages per conversation, allowing us to capture more than one topic when necessary. For example, if a chat starts with Fin pricing and then moves on to a bug in conversation assignment, our system will spot and tag both topics separately
- One message can genuinely fit more than one topic. For instance, “What’s the difference between Fin AI Agent and Fin AI Copilot?” belongs to both categories in the absence of a dedicated “comparison” topic. Such semantic overlap is common in real-world language, especially in support data where questions blend multiple intents. Occasionally, overlap instead signals redundancy – two clusters describing the same issue – which can be spotted through small inter-centroid distances.
To quantify ambiguity, we analysed secondary and tertiary topic matches via cosine similarity. Only about 5% of messages showed less than a 0.05 gap between their top two or three topic candidates – meaning true borderline cases are rare. While clearer separation between clusters reduces edge cases, genuine multi-intent conversations will always resist perfectly clean boundaries.
Human validation
No matter how good the metrics look, topics must make sense to people. Cohesion and separation scores are helpful, but they’re meaningless if clusters don’t reflect how users actually interpret their data.
Quantitative metrics can’t fully capture subjective structure – especially hierarchies. There’s no single “right” way to group subtopics: we cluster by semantic similarity (e.g., all “Fin”-related items under one topic), while some users prefer grouping by issue type, like bugs or pricing, across products.
To stay grounded in real-world needs, we interviewed customers and gathered qualitative feedback on topic clarity and usefulness. This feedback loop remains central to our process – because in the end, quality is measured by how well the system helps people do their jobs.
How to Update the Model?
Emerging topics
Unsupervised models are typically static – they’re trained once and can’t easily adapt to new data. But support data evolves constantly: new products launch, features change, and fresh themes appear. A model trained weeks ago won’t recognize today’s conversations. This causes two main issues:
- Misassignment – new topics get forced into old clusters
- Unassignment – new conversations fall below the similarity threshold (e.g., cosine < 0.5) and remain unlabelled
To address this, we built a daily pipeline that detects emerging topics and incrementally updates the model. Thanks to the centroid-based architecture, adding a new topic is simple – just introduce a new centroid.
This is how we identify new topics:
- Discovery on new data. We apply the same topic modelling pipeline (embedding → UMAP → HDBSCAN) to a combination of new unseen support conversations (out-of-sample), and unassigned conversations from recent inference runs
- Centroid comparison & deduplication
– We compare the centroids of these newly discovered clusters against existing centroids to check for similarity
– We retain only the clusters that are well-separated from existing topics – ensuring they represent genuinely new themes. - Update the model. The filtered centroids are simply appended to the existing centroid list – effectively extending the model without retraining. This process lets us keep the topic model fresh and adaptive, without sacrificing scalability or interpretability.
Archiving topics
Just as new topics emerge, others naturally fade. Over time, two patterns appear:
- Recurring topics – persistent themes like pricing, cancellations, or onboarding that remain active and should stay in the model
- Event-driven topics – short-lived spikes tied to launches, campaigns, or temporary bugs
When these transient topics go quiet, we archive them. Centroids for inactive clusters are removed, reducing noise and keeping the model aligned with current conversation trends.
Conclusion
We’ve designed the system with real-world constraints in mind: messy input data, changing user behavior, and the need for fast, high-throughput inference. With centroid-based inference, ongoing model updates, and human-in-the-loop validation, we’ve built a flexible, production-ready system that evolves alongside the conversations it’s built to understand.
Now, topics are no longer just labels – they’re a lens into customer reality. And with the right mix of structure and language, that lens becomes a powerful tool for action.

