
Introduction
Fin’s north start metric is resolution rate; it’s how we measure how well Fin, our customer support AI agent, is performing. Each resolution is priced at US$0.99, so accurately detecting when Fin resolves a conversation directly impacts our revenue.
At Intercom, we classify resolutions in two categories: assumed resolutions and confirmed resolutions. An assumed resolution, on the one hand, happens when a user leaves the chat without giving feedback (positive or negative), and without the conversation being escalated to a human support agent. A confirmed resolution, on the other hand, occurs when a user explicitly states that Fin’s answers were helpful. We typically view confirmed resolutions being more valuable than assumed resolutions because they come with clear, reliable signals from users that we did a good job.
User feedback plays a central role in determining both assumed and confirmed resolutions. A user’s response to the question “Was that helpful?” defines whether their issue remains unresolved (in the case of negative feedback), counts as an assumed resolution (if there’s no feedback), or becomes a confirmed resolution (in case of positive feedback). Any confusion or errors in this step lead to frustration for end users, dissatisfaction from our customers, and ultimately lost revenue for Intercom.
If we incorrectly classify feedback as negative, Fin may keep pushing to solve a problem that is already solved, wasting time and money. On the flip side, if we mistakenly treat a bad experience as a positive one, Fin might abandon the user prematurely, leaving them without help and unfairly charging our customers for a failed resolution.
Historically, Fin was fully powered by large language models (LLMs). These models are zero-shot learners: they can generalize to new and complex tasks, follow instructions, reason, and interpret subtle cues – skills we once thought only humans possessed. LLMs have completely disrupted the chatbot space. What used to be clunky, scripted decision trees have now evolved into highly autonomous AI Agents within months.
But not every decision in customer support automation requires billions of parameters. Some tasks are simple and binary: Was the answer helpful or not? Does the user need more assistance? Should we bring in a human? With that in mind, we set out to explore whether a simpler model, one with fewer than a billion parameters, could accurately detect user feedback.
We trained a text classification model on hundreds of thousands of real Fin interactions and compared its performance against state-of-the art LLMs. The goal was to see if a smaller, more efficient model could match or even outperform much larger models on this very specific task.
Multitask Learning with ModernBERT
Bidirectional Encoder Representations from Transformers (BERT) is an encoder-only transformer model that has been a major success since its release in 2018. Even today, it’s widely used across the industry, currently ranking as the fifth most downloaded model on HuggingFace, with 60 million monthly downloads at the time of writing.
ModernBERT, released in December 2024, builds on the original BERT architecture by integrating several recent advancements from the research space. One of the most notable improvements is the extended context window: ModernBERT can process up to 8,192 tokens, 16x more than the original BERT’s 512 tokens, while maintaining a comparable model size (see Table 1). This makes it significantly more powerful than the earlier version for long-text understanding without sacrificing efficiency.
| Model | Variant | Context Window | Num. Parameters |
|---|---|---|---|
| BERT | base | 512 tokens | 110M |
| large | 512 tokens | 340M | |
| ModernBERT | base | 8,192 tokens | 149M |
| large | 8,192 tokens | 395M |
ModernBERT processes input in the form of two segments, Sentence A and Sentence B, which are tokenized and separated by a special token, \( \mathrm{[SEP]} \). Another special token, \( \mathrm{[CLS]} \), is added at the beginning of Sentence A. During training, ModernBERT typically learns to answer the question: “Does Sentence B relate to Sentence A?” Here, “relate to” can have varied interpretations, such as “Does Sentence B follow from Sentence A?” or “Does Sentence B answer Sentence A?” The \( \mathrm{[CLS]} \) token serves as a sentence-level embedding that summarizes the input pair and is commonly used as the input to classification heads.
In our case, simply classifying feedback as positive or negative isn’t enough. We define feedback understanding as a combination of three classification tasks. The first is identifying the feedback type, which can be one of three values: no feedback, positive feedback, or negative feedback. The second is detecting whether the user message contains a follow-up question or complementary information. The third is determining whether the user has ended the conversation with their message. Table 2 illustrates examples for each of these classification tasks.
| AI Turn | User Turn | Feedback Type | Has Follow-up Question | Has Ended Conversation |
|---|---|---|---|---|
| Here’s how you update your password: [instructions] Did that answer your question? | I can’t login. What should I do? | Null | Yes | No |
| To cancel your subscription, you need to do [X], [Y], and [Z]. Was that helpful? | yeah thx | Positive | No | No |
| Your order was cancelled, but unfortunately we can’t offer a refund. Is this what you are looking for? | Nope, try again | Negative | No | No |
| To cancel your subscription, you need to do [X], [Y], and [Z]. Was that helpful? | Yes, but apparently my email is also wrong. What should I do next? | Positive | Yes | No |
| Here’s how you update your password: [instructions] Was that helpful? | No. It’s not my password that I need to update. It’s my 2FA authentication method. | Negative | Yes | No |
| I’m glad that I could help. Is there anything else you need help with? | No, thanks. That’s all. | Null | No | Yes |
To address our problem, we designed the classification system using a multitask learning approach. In multitask learning, a single model backbone is trained to perform multiple related tasks simultaneously, such as solving several classification problems at once, combining image classification with segmentation, automatic speech recognition with speaker diarization, etc. The key insight is that by training on related tasks together, the model can learn more generalizable features, ultimately improving performance across individual tasks. Figure 1 shows a schematic of our ModernBERT-based multitask neural network. We use ModernBERT-large as the backbone of our system, hereafter referred simply as ModernBERT.
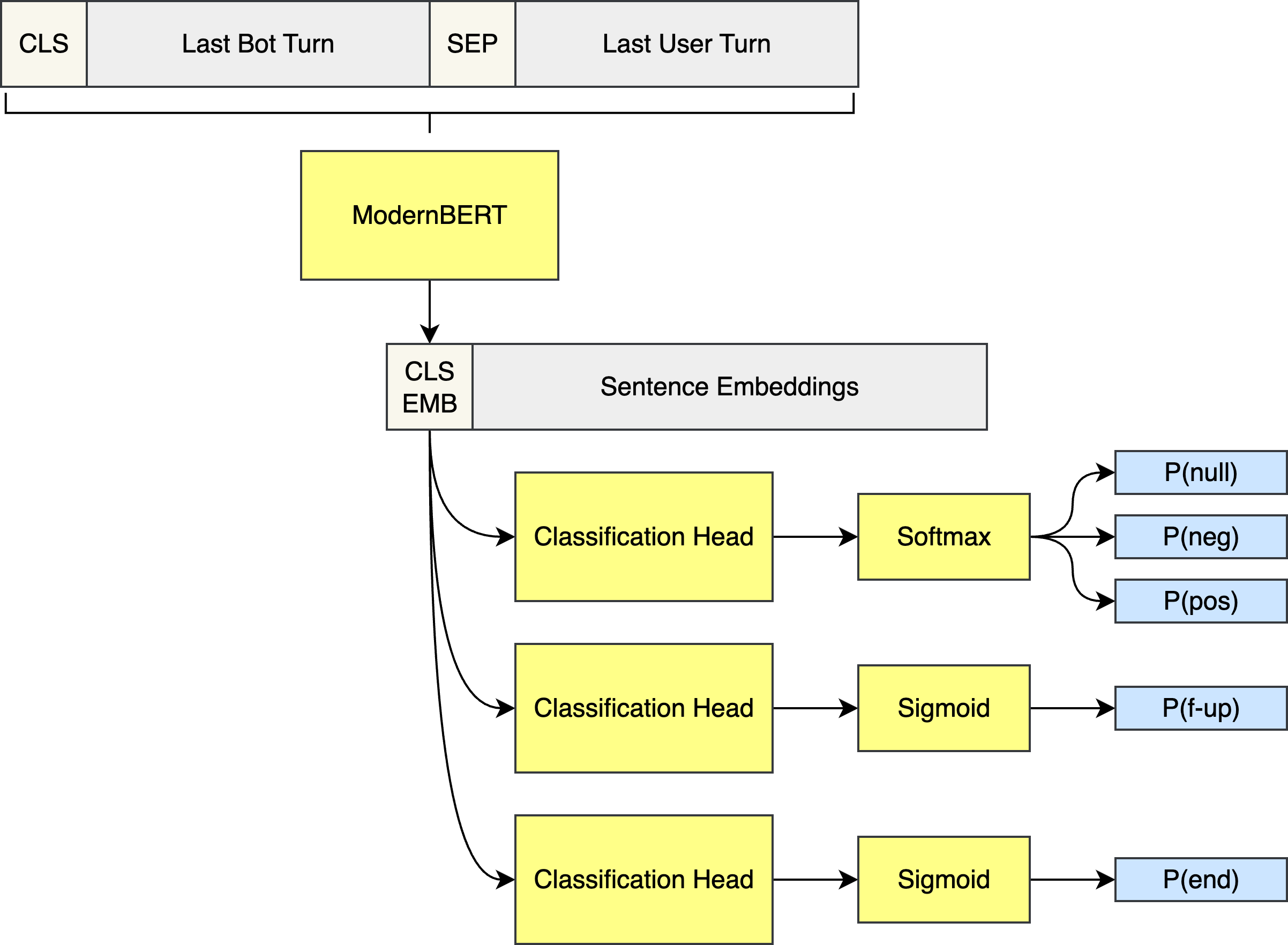
The overall multitask loss is a combination of the individual losses from each classification head. For feedback type, we use standard cross-entropy loss, while the follow-up question and conversation end tasks are trained with binary cross-entropy loss. The combined loss function is defined as
$$
L_\mathtt{multitask} = L_\mathtt{feedback\ type} + L_\mathtt{follow-up\ question} + L_\mathtt{ended\ conv.} \\
L_\mathtt{feedback\ type} : \text{Cross Entropy Loss} \\
L_\mathtt{follow-up\ question},\ L_\mathtt{ended\ conv.} : \text{Binary Cross Entropy Loss}
$$
Data
As described earlier, ModernBERT takes two input segments, Sentence A and Sentence B. In our setup, Sentence A corresponds to the last turn from the AI: a concatenation of all messages sent by the AI Agent in that turn. Sentence B is the last user turn: a concatenation of all user messages sent before the AI responded. We choose to not include the full chat history for two reasons. First, even with its extended capacity, ModernBERT’s context window is still limited. Second, our goal is to train the model to answer a focused question: “Does Sentence B provide feedback, ask a follow-up question, and end the conversation with respect to Sentence A?” Adding additional context could distract the model from what matters.
Even with this trimmed-down context, the combined turns can occasionally exceed the 8k token limit. In these edge cases, we apply a targeted clipping strategy: we truncate the AI turn from the left and the user turn from the right. This decision is based on the expectation that the most relevant AI tokens appear near the end of its message, where it typically asks if the answer was helpful, offers to talk to a human, or probes for more questions. Conversely, users usually begin their replies with direct feedback or requests, making the start of their message more informative.
After tokenization and clipping, we format the input by concatenating the AI and user tokens with a \( \mathrm{[SEP]} \) token between them, and a \( \mathrm{[CLS]} \) token prepended to the sequence.
Our dataset was built from hundreds of thousands of Fin interactions in English-language, spanning thousands of apps across various industries and business segments. We split the data into train, validation and test on the conversation level to ensure all interactions from the same conversation reside within a single split. To prevent bias, we excluded a small number of very long conversations whose large volume of messages could skew the model’s behaviour. These exclusions account for less than 5% of all Fin conversations.
In compliance with data protection standards, all apps included in the training process provided explicit consent for AI training. Table 3 summarises the number of examples and participating apps in each spit.
| Num. Apps | Num. Interactions | |
|---|---|---|
| Train | 5k | 900k |
| Validation | 2.5k | 50k |
| Test | 3k | 99k |
Results and Discussion
We evaluated our model on the test set described in the previous section. Table 4 and Table 5 present classification metrics for all three feedback-understanding tasks, using the current LLM-based classifier as the ground truth.
The results show that ModernBERT performs remarkably well compared to a state-of-the-art LLM. It is especially strong in identifying when a conversation has ended, achieving an ROC AUC of 0.9987. This task is particularly sensitive: a false positive, mistakenly predicting that a conversation has ended, can cause Fin to exit prematurely while the user still needs help, leading to a poor customer experience.
For feedback type classification, ModernBERT also performs strongly, achieving F1-score above 0.92 across all classes.
| Task | Overall Accuracy | ROC AUC |
|---|---|---|
| Feedback Type | 0.9652 | |
| Has Follow-up Question | 0.9579 | 0.9918 |
| Has Ended Conversation | 0.9978 | 0.9987 |
| Feedback Type | Precision | Recall | F1-Score |
|---|---|---|---|
| Null | 0.9737 | 0.9793 | 0.9765 |
| Negative | 0.9300 | 0.9108 | 0.9203 |
| Positive | 0.9653 | 0.9596 | 0.9624 |
| Has Follow-up Question | Precision | Recall | F1-Score |
|---|---|---|---|
| False | 0.9662 | 0.9561 | 0.9611 |
| True | 0.9483 | 0.9601 | 0.9541 |
| Has Ended Conversation | Precision | Recall | F1-Score |
|---|---|---|---|
| False | 0.9990 | 0.9987 | 0.9989 |
| True | 0.9187 | 0.9390 | 0.9288 |
So far, our experiments have used our current LLM-based classifier as the source of truth. ModernBERT was trained and evaluated on labels generated by this LLM. But, like any model, LLMs are not infallible, they can and do make mistakes. In Fin’s case, we also operate under tight latency constraints, which limit the usage of long reasoning chains and increase the likelihood of noisy or imperfect labels.
A well-established strategy for estimating label noise is to introduce a second, independent LLM as a judge. This judge independently reasons through the task and generates what it considers to be the correct label. By comparing both the original labels and our model’s predictions against the judge’s decisions, we can gain a clearer picture of which model aligns best with a more robust interpretation of ground truth.
For this evaluation, we selected Anthropic’s Claude 4 Sonnet with Extended Thinking. It’s one of the top-performing models for complex reasoning and provides clear chains of thought that can be reviewed for consistency and transparency. Due to processing cost and runtime considerations, we randomly sampled 5,000 examples from our test set for this evaluation.
Table 6 presents the performance of both the original LLM-based model and ModernBERT on the feedback type classification task, using Claude 4 Sonnet’s outputs as the new gold standard. When judged by Sonnet, both models perform similarly, with the LLM holding a slight edge in overall accuracy. For the positive feedback class in particular, both models achieve high precision and recall, although the LLM shows marginally better consistency and slightly higher precision.
| Model | Class | Precision | Recall | F1-Score |
|---|---|---|---|---|
| LLM | Null | 0.9328 | 0.9303 | 0.9315 |
| Negative | 0.7724 | 0.7680 | 0.7702 | |
| Positive | 0.8610 | 0.8915 | 0.8760 | |
| ModernBERT | Null | 0.9343 | 0.9662 | 0.9303 |
| Negative | 0.7627 | 0.7714 | 0.7670 | |
| Positive | 0.8543 | 0.8986 | 0.8759 |
These experiments demonstrate that ModernBERT performs on par with a state-of-the-art large language model for fundamental classification tasks in English, even in scenarios that involve subtle nuances in user feedback, which can be challenging even for human evaluators.
During manual review, one particularly interesting trend stood out: ModernBERT was often better at distinguishing between true feedback and general confirmations. For example, it more accurately identified cases where users responded “Yes” to a different question, not necessarily confirming that Fin’s answer was helpful. The anecdotal examples below surprised us since we initially expected that LLMs would have the upper hand in capturing complex question-answer relationships.
Example 1. The AI asked whether or not the user would like more details, and the user confirmed. The LLM-based model interpreted the confirmation as positive feedback, while ModernBERT correctly labeled it as no feedback (null class).
AI: If you still need any help with checking your deposit, please let me know. Would you like to provide more details about what you are trying to resolve
Customer: Ok
Example 2. The AI explained that unlocking a card would require human intervention and asked if they wanted to talk to a human, and the user accepted the offer. The LLM-based model again classified this as positive feedback, but ModernBERT accurately inferred that the response referred to the escalation, not to the AI’s answer, and labeled it as no feedback (null class).
AI: To get your card unlocked, you’ll need to request assistance from our human support team. Please let me know if you’d like to speak with a human agent who can help process this request for you.
AI: Is that what you were looking for?
Customer: Hello I need to unlock this card Yes please
Conclusion
LLMs play a crucial role in engineering intelligent AI agents, but they come with trade-offs. They’re often slow to respond and expensive to operate, both in terms of token costs when using third-party APIs, and infrastructure costs when hosting them in-house.
Fortunately, many common tasks in the customer support pipeline are simple classification problems. These can be solved effectively with traditional classification neural networks, like ModernBERT, which are significantly faster, more lightweight, and cheaper to serve. As we’ve demonstrated, with enough high-quality training data, ModernBERT can match the performance of much larger LLMs on specific tasks without the overhead.
However, there are some limitations. Training multilingual classification models is far more challenging. Fin supports 45 languages, many with different alphabets and regional variations that make each unique. With this level of linguistic variation, it’s hard to obtain enough training data to achieve high performance across the board. For this reason, we focused our efforts on English-only interactions. In contrast, state-of-the-art LLMs are trained with vast amounts of data from the internet, giving them a broad and reliable language coverage and making them a viable option to handle Fin’s global reach.
Understanding customer feedback is essential for measuring the success of customer support AI agents. Fin’s resolution logic depends on correctly interpreting the user’s sentiments towards its answers. Our proprietary classification model reinforces Intercom’s focus on building practical, high-performing AI solutions that serve both our customers and their users.

