Why an AI-driven Customer Experience Score will replace human-surveyed CSAT
We’re more than 2 years into the LLM-driven product world, and we’re still only just starting to understand how AI challenges fundamental assumptions about the products we build and the services we offer.
It’s now also changing the metrics we use to measure success.
Last year, we surveyed 300 customer service leaders and asked them: “If your support tool could do one thing really well – improve support efficiency or improve customer experience – which would you choose?” 78% of them said their top priority is to improve customer experience.
And what’s the primary way just about everyone measures that? CSAT – the customer satisfaction survey.
The problem is that CSAT just doesn’t measure up. It has poor coverage and gets biased results. This is no secret or surprise. But until now, there’s been no better alternative.
We all suffer from survey fatigue
We are all bombarded by satisfaction surveys. We get them for nearly everything these days: taxi rides, restaurants, haircuts, package deliveries. Every business is eager to know how well they did.
This saturation has created survey fatigue. When was the last time you actually completed one? Maybe when you were particularly delighted or thoroughly frustrated. But most of the time? You ignore them. I ignore them. Everyone ignores them.
Let’s look at the hard numbers: across all our customers who use CSAT, the average response rate for our little satisfaction survey, which we explicitly optimised for simplicity to maximise response rates, was just 21%.

But the actual coverage is even bleaker: surveys are sent out to only 39% of conversations, so in total only 8% of all conversations actually received a CSAT score.
That means teams are blind to the experience of over 90% of their conversations. Let that sink in. The metric most customer service teams live by—the one that determines bonuses, drives strategy, and gets presented to the board—ignores 92% of what’s actually happening.
Coverage is the achilles heel for surveys.
Customer service, uniquely, doesn’t need surveys
The reason there are so many surveys in the world is because there’s no other way to find out what the customer thought. Your experience at a restaurant or hotel is basically invisible—there’s no way to say to someone on your restaurant service team: “Hey, can you review all the dining experiences our team delivered this week?”
But the customer support world is different: it’s all recorded! There are transcripts of the whole conversation, whether it’s in chat, email, or phone.
You absolutely could ask a team member to review all your support conversations, but you don’t, because that would simply take too long. It’s all accessible, but reviewing them is not scalable.
Surveys are a short-cut to solve the scalability problem. Now with AI, we don’t need that shortcut anymore.
Because of those transcripts, service conversations are uniquely well-suited to AI evaluation. The transcripts offer the raw material for AI to evaluate. And scaling the evaluation of that raw material is a snap for AI. Just point it where you want it; it will review everything.
The new AI-driven Customer Experience Score
What we’ve built is straightforward: our new Customer Experience Score (CX Score) evaluates each conversation and gives it a single score on a scale of 1-5, based on three inputs:
- Was the customer’s issue actually resolved? And if they had multiple issues, were each of them resolved?
- What was the customer sentiment (if any is detectable)?
- What was the quality of service received (in terms of tone, knowledge, timeliness)?
We also output a short explanation of why that score was given.
Here are a couple examples of a high CX score:
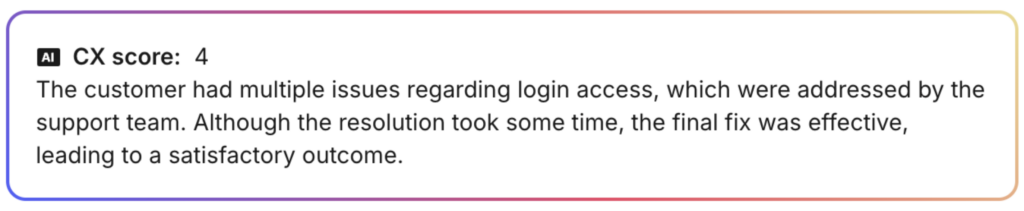
And some examples of a low score:

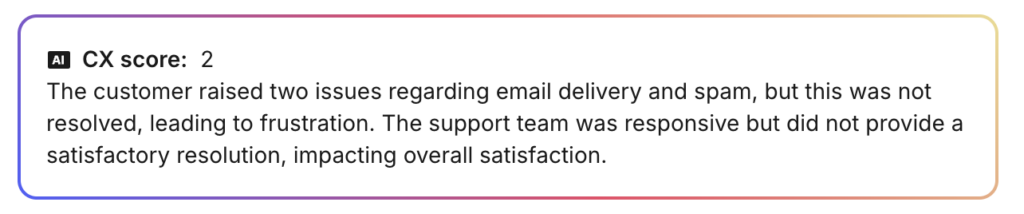
As you can see, the AI doesn’t just give a score – it provides context about what happened and why.
Just imagine asking a human to analyze thousands of these conversations and write thoughtful evaluations for each. They’d quit after an hour.
But the huge value is in the massive increase of coverage. Now you can actually spot all your concerning support interactions, review them, and figure out how to fix them – while receiving a more accurate KPI too.
This new way of measuring exposes uncomfortable findings
When we compared AI-driven CX scores with traditional CSAT across 53 customers covering multiple industries in B2B and B2C, we found some fascinating patterns.
(Note: our score follows the same approach generally used for CSAT: the percentage of conversations rated 4 or 5.)
Finding #1: Your team is probably not performing as well as you thought
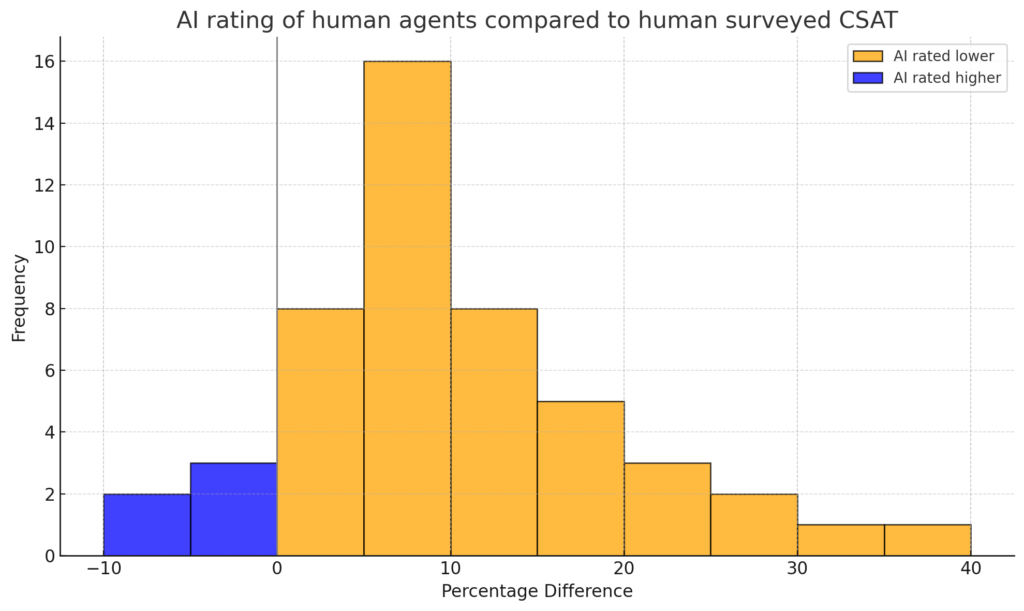
For support conversations involving only human agents, we see a 10% decrease in the CX score compared to the surveyed CSAT score:

For most teams, this is a sobering reality check – AI says they’re performing meaningfully worse than they’ve been telling themselves.
In the distribution graph below, you can see that this pattern was true for almost all customers. And sometimes that difference was quite dramatic.
Why the difference?
The data shows us that conversations with surveyed CSAT have a CX score that is 13% higher than conversations without a CSAT score. So we see evidence of a response bias – people who had a positive experience are more likely to fill out your survey.
In other words, that CSAT coverage problem is resulting in an accuracy problem.
Finding #2: Your AI Agent is performing better than you thought
For support conversations handled entirely by AI agents, we see the inverse pattern – AI consistently rates our AI agent (Fin) higher than humans do.
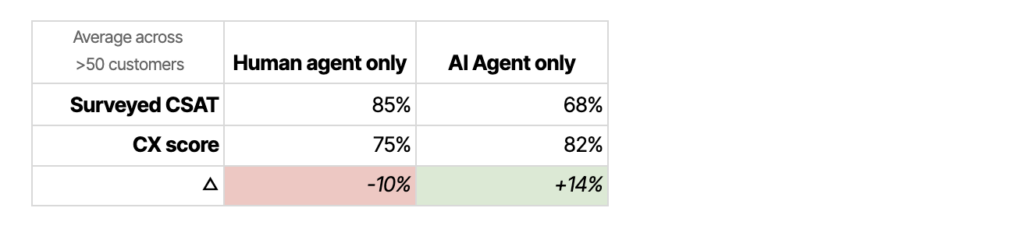
And again if we look at the distribution, we see this pattern is consistent across almost all customers.
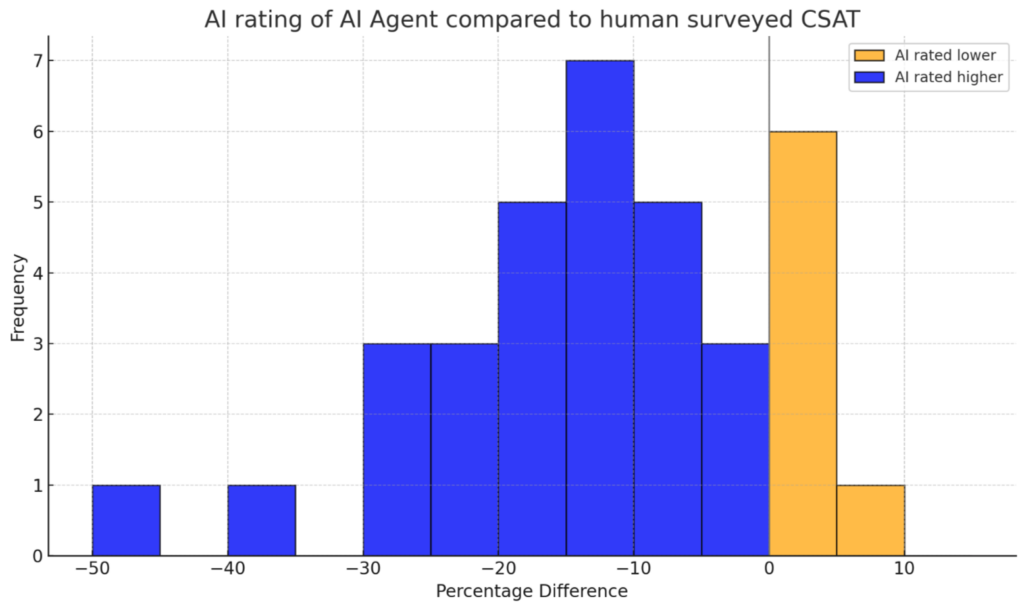
Why is this?
Unlike with human CSAT, we don’t see evidence of a response bias in the data.
Outside of our datasets, there is broader evidence that humans tend to rate bots more harshly. Here’s one study from last year that found evidence for this bias in a customer support context:
“Study participants reported significantly lower satisfaction.. following interactions with a chatbot compared with a human agent in both positive and negative service outcome conditions. The effect was fully mediated by the service-giver’s perceived empathy“
The irony here is notable: the AI tool we’ve built to objectively measure customer experience reveals our own subjective biases against AI assistance.
Not yet a finding: humans compared to AI Agent
You probably noticed in the table above that the CX score shows our AI Agent performing better than humans.
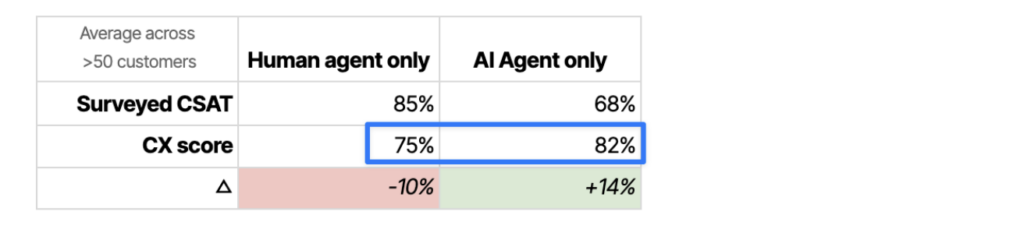
We don’t rate this difference as reliable. It’s an unfair comparison because, at least for now, humans have to handle the messier, harder, more complex queries and are more likely to deal with frustrated customers.
Can we really trust AI?
It’s hard not to be skeptical of all this – can we really trust an AI score for something as subjective as customer experience? Particularly when you see that AI rates AI higher?
It’s critical to be able to trust a metric. So we had our most experienced support agents manually review and score 2000 support conversations. That gave us a dataset we could trust. Then we applied our CX Score to rate the same conversations. Finally we ran an F-score analysis, which balances measuring false positives and false negatives. The result was 0.8. That’s high. In most real-world machine learning systems, especially in language and support, anything above 0.7 is considered strong. So 0.8 tells us it’s performing at a high level and closely matches human judgment.
So we believe this metric is valid.
The real value is not in the number, but the spotlight it provides
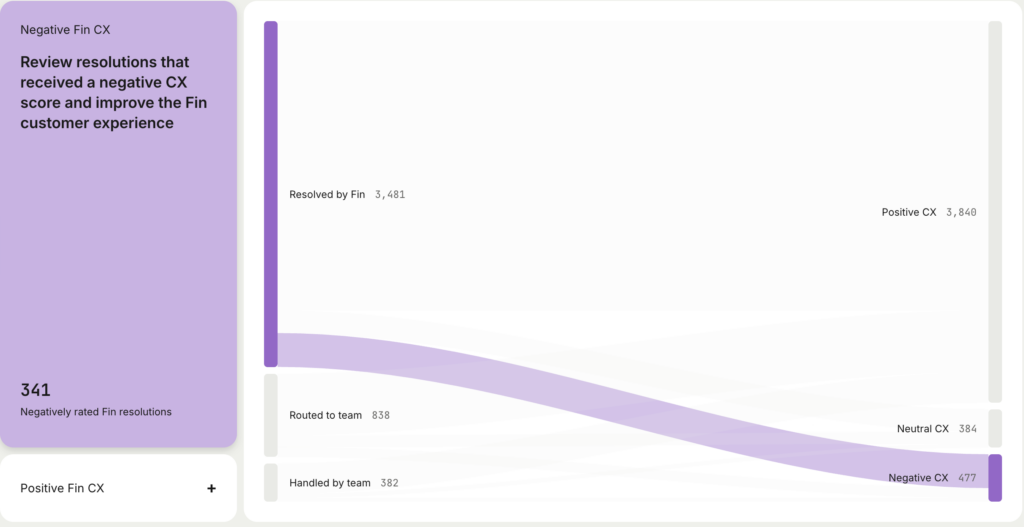
It’s easy to anchor around the changes in scores, but the real value is not in a more accurate baseline. Instead the real value is the ability to identify far more conversations that you should be looking at.
One of the ways we expose this is in this optimisation report, which shows conversations that were fully resolved by our AI Agent, and therefore your human team is unlikely to see, and which had a negative CX score. So these are worth reviewing, and some of them you will want to follow up on. (And if you do follow up, they won’t be counted as AI Agent resolutions.)
If you relied on surveys, you would be blind to most of these conversations. That spotlight capability is the real super-power here.
Not just theory; here’s the real experience of switching to the CX score
We of course dog-food our own product; but in this case, the product team actually followed our support team’s lead in defining these metrics. Our support team has been working with the CX metric for quite a while now.
Here’s how Intercom’s numbers look:
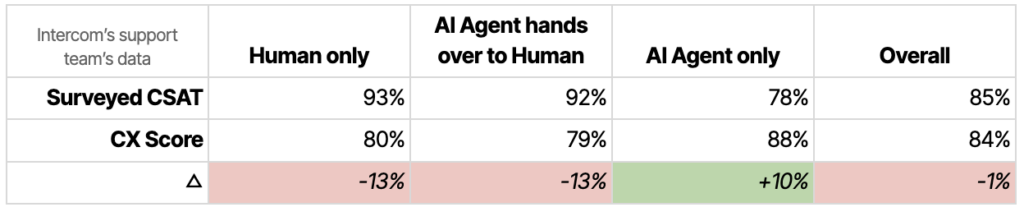
And here’s how Franka, a Director of Customer Support at Intercom, has adapted to it:
“If you are a support leader out there I ask you – what do you think your “real” CSAT would be if you got 100% of responses back? You and I both know it’s not in the 90s as you are presenting every month in the Monthly Business Review. But it can still be shocking to see it for real.
When we developed this metric internally I nearly didn’t want to believe it. I didn’t want to think my team’s performance was actually closer to 70% or 80% CSAT (depending on the week). But I did want to look into it some more. I wanted to see what it finds. And found it did.
Conversations where customers were saying things like ‘Oh looks like we are not premium enough for you, guess I’ll go speak to your competitors’ or ‘Hey why are you ignoring me’. It flagged conversations with no surveyed CSAT, conversations we didn’t review and we never would have found manually looking through thousands of weekly questions we handle.“
We’re seeing things we just couldn’t before. CX highlighted areas of the product where satisfaction had been slowly declining for months—things we’d never catch in quarterly reviews. Now we can act on them in real time.
It helped us realize where we’d been accepting mediocrity. CX turned a blind spot into an opportunity.
You can’t fix what you can’t see. CX shows us everything. And that’s exactly what we need to get better.”
Culture Amp, a company who knows a thing or two about surveys, has been an early user of our CX score. Here’s what Jared Ellis, their Senior Director of Global Product Support, told us about their experience with it:
“CSAT was becoming such a problematic metric… we have entered a realm with customer satisfaction where the feedback was no longer kind of hitting that quality… In fact, one of my managers came to me and said, ‘I haven’t had a single CSAT response that I’ve been able to coach one of my team members on for about two or three months…’ And we definitely didn’t have the quantity in order to really find the actionable results… We were worrying more about the metric than we were about the feedback.
When this customer experience score popped up and I heard about it, it just triggered something in me that went, I’d never thought about it that way… being able to get some form of insight from just about every conversation that your team is having is suddenly a treasure trove.
The surprise for me was that it did [feel familiar]. And the feedback that it was producing was something that was quite actionable, was understandable, and that, yeah, I felt like teammates could actually do something with.“
I think the biggest difference that customer experience score has made for our team is that we can now understand what the neutral feelings from our customers are and actually take action to improve our overall service by really getting into the meat of it.“
The end of “good enough” metrics
The AI-driven Customer Experience score isn’t just a better version of CSAT – it represents a fundamental shift in how we measure customer experience.
Surveys were a necessary compromise in an scalability-constrained world. That world no longer exists. Continuing to use surveys as your primary metric in 2025 is like navigating by stars when you’ve got GPS.
This shift compels us to confront a broader question: What other “good enough” compromises are we clinging to? What other metrics are we accepting at face value because “that’s how it’s always been done”?
As more work becomes AI-driven instead of just AI-augmented, many metrics we use will change. It’s incumbent on us to challenge our assumptions not just on how we deliver a service, but in how we measure it.