At Intercom, we’re experimenting with new products and features every day, especially with AI. We’re exploring what the latest AI models can/can’t do.
We are now sharing some of the work in progress to give people a sense of what we’re up to, and maybe start a discussion with us. We’d love that!
Creative Coding with Claude
In our latest demo, Justin Truong shows how Intercom’s brand design team used Claude to execute the visual ideas behind Pioneer, the summit for AI customer service leaders, no engineer needed.
Take a look at the Pioneer site here.
AI-powered Suggestions
For the first time ever, you can now improve AI agent performance – with a single click.
AI-powered Suggestions is a groundbreaking new feature that helps you fix gaps in content, data, or actions to improve Fin’s performance.
No detective work. No guessing. No weeks of analysis. Just clear improvements you can implement instantly.
Check out this demo from Ahmad on our Product Team to see AI-powered Suggestions in action!
We think this is a really big deal, and huge step forward.
We worked hard to build this breakthrough, AI-powered metric, because the way we measure customer service is broken.
CSAT has really poor coverage and inaccurate answers, only giving us a view of less than 10% of our customers’ experience. It’s the metric we love to hate. So why do we still use it?
CX Score will become the new standard because it is much better: it gives you a complete view of your support quality across every customer conversation – no surveys required.
How it works:
CX Score uses AI to score every customer conversation from 1 to 5, based on resolution, sentiment, and service quality – all in real time.
It lets you see exactly how Fin will respond to any of your actual customers, so you can test with confidence before going live. It’s in closed beta for the moment, but Ben has recorded this demo you can watch.
Fin AI Agent as MCP Client
Earlier today we shared how Intercom is using MCP to give AI systems like Claude access to real-time customer data from Intercom. Great for teams without access to our helpdesk to benefit from a wealth of customer data.
Product Engineer Luis Alvarez Aguilar has been working on the next step in that journey: making Fin act as an MCP client so it can connect with third-party and internal business tools, access data, and take action for customers.
In this demo, Luis shows how Fin connects to a Stripe MCP server to:
✅ Answer customer pricing questions
✅ Pull product plan details
✅ Generate a live payment link—all inside a conversation
We’re still in early stages, but it’s exciting to see Fin connecting with external tools through open standards. More to come soon.
Intercom MCP Server
This week, Senior Product Engineer Davy Malone built an Intercom MCP (Model Context Protocol) server using Cloudflare Workers—and it’s been a game changer.
It allows AI systems like Claude to access real-time data from Intercom: user profiles, conversation history, ticket metadata, and more.
For our engineers, this means less time manually pulling context across systems—and faster, smarter troubleshooting when issues arise.
And we’re just getting started. Soon, our AI agent Fin will also be able to connect to MCP servers to access data and perform actions in external systems.
If you’re curious about where this is going, we’ve shared more on our product vision for MCP here.
April 2025
Setting Fin Voice Live
Last week, we shared an early look at Fin Voice, our AI agent for the phone channel.
In this demo, Artem Ankudovich show’s how to take the next step by moving from a testing environment to going live once you’re confident in Fin’s tone, accuracy, and logic.
It’s exciting to see Fin step in as a frontline agent, handling real queries and handing off to another team when needed.
Fin Voice
Phone support is powerful – but also one of the hardest channels to get right. It’s often slow, tough to scale, and frustrating for customers stuck on hold. That’s why we built Fin Voice – our new Voice AI agent that helps businesses deliver instant, 24/7 phone support, without the wait.
In the demo, you’ll see how Fin responds to common support questions in the Fin Voice testing environment. No matter how large your help center is, Fin can instantly give the right answer and guide your customers – just like a human agent. It’s a glimpse of what support could look like without phone trees, hold music, or long wait times.
We’re still in the early stages, but the potential is big.
AI-Generated Content from Video
We want to share with you an experiment we built at a recent Intercom hackathon around converting videos into great content.
Inside Intercom, we share a lot of product videos internally as we develop and test new features. An idea Senior Group Product Manager Chris Dalley and Staff Product Manager Peter Bar tested was whether we could use AI to convert these product videos into great Help Center articles complete with auto-generated product screenshots – turns out yes we can!
This was a small experiment, but it points to a future where support content could is much easier to create, update, and scale – all from recording a quick video.
It’s still early thinking, and we’re not yet sure where it fits – maybe we should add it into the product? Also curious what approaches you have tested for creating great AI content?
Multilingual Workflows
Scaling support used to mean more tools, more workflows, and more manual effort.
AI is shifting that. And our Multilingual Workflows beta is part of that shift. It lets teams build once and serve every customer, in any language, without duplicating effort!
Check out this working demo, and share what’s helping your team scale.
AI Category Detection for Fin AI Agent
AI is transforming how customers get support. In particular, it’s reshaping the invisible parts, like how conversations are assigned to the appropriate teams.
When a customer reaches out, they expect to be understood and quickly directed to the right place. Intercom’s AI Category Detection feature helps Fin do exactly that. It analyzes each conversation to identify things like the request category or sentiment, and then saves this information as conversation data that can be used for routing, reporting, and more.
In this demo, we show how it can be used to automatically assign conversations to the right support team. No long menus for customers, no manual triage for teammates.
The feature is in closed beta, and we’re still learning more. Stay tuned!
OTP for Fin Tasks
As AI Agents take on more complex and sensitive workflows, security can’t be an afterthought. It has to be built in from day one.
At Intercom, we’ve designed Fin with security as a first principle, enabling customers to configure multiple layers of protection, real-time verification flows, and safeguards that help maintain trust between agents and their customers.
In this demo, Fin supports a customer through a policy amendment, verifying their identity and then guiding them through the process step by step.
Take a look and let us know what you think.
AI Generated Fin Task Instructions
Last week, we shared a demo of Fin showing how we’re blending rules based (deterministic) and natural language based (generative) logic in Fin so that our customers can configure the exact customer journeys they need.
This is a very important thing to learn about and understand if you are using or building AI Agents.
But this whole area is new, it has never existed before the AI era, and so people need to learn how to do it. To help them, we’ve built a feature that uses AI to suggest instructions. Today we’ve a nice follow up demo showing how you can write structured Task instructions using natural language in Fin.
March 2025
Fin Tasks
The future of AI Agents is generative and deterministic workflows blended together, and Agents that complete full Tasks for customers.
Most businesses have complexity, and in exploring different ways Fin can work for our customers, it’s really clear that they need both generative and deterministic steps in single workflows. Here is a demo of our work in progress.
Fin in the Help Center
Knowledge bases are a critical line of defence for support teams but they can also become a bottleneck, leaving customers to sift through hundreds of articles to find what they need.
So we ran an experiment: using Fin to deliver faster, more direct answers inside the Help Center.
We’re still early in the test but already learning a lot about how AI can reshape self-serve support.
Fin Messenger experiments
Over the past month we have been very busy running a series of experiments on the design of Fin in our Messenger. We decided to challenge numerous design decisions that were meant to address problems from a different era.
Every new experiment lead to theories, every theory lead to new ideas and ideas with the best rationales made it to their respective A/B tests. The results were as interesting as the process itself. This demo shows the results, and how we think about our AI products and using data to refine our design decisions.
Fin Testing
As more customers use Fin, we’re learning how important it is to test how Fin answers different types of questions.
So we’ve been building new powerful testing tools. Here is a working beta of one of them.
What makes it so powerful is the ability to bulk test how Fin answers a set of questions. Plus, right below the answers, you’ll find details on the inputs used to generate each response, making it easy to troubleshoot and refine.
We’re already seeing how this is helping customers feel more confident in how Fin responds – and giving them the tools to make those responses even better.
Fin Guidance Assistant
We mortal humans are still trying to learn how to use AI systems. The more we talk to them, the more weird and wonderful things we learn about how they ‘think’. LLMs are a generative technology which makes them unpredictable at times.
But using AI for business, we need to be able to control parts of what they do. We built Fin Guidance to do this, so you can guide Fin. But guidance is like advice, you can give good or bad advice, and so you can give good or bad guidance!
And we’ve seen customers doing this, trying to give good guidance but learning through trial and error that it doesn’t quite work as intended. So we’re now building tools to help our customers write good guidance. This is cutting edge stuff, we’re using Anthropic’s Claude 3.7 Sonnet with Extended Thinking.
February 2025
Real time Inbox Translations
Customer Service teams need to support their customers in many languages, and so end up hiring multilingual speakers, using different translation tools, and ultimately adding a lot of complexity to their support operations.
But AI is excellent at real time translations. So we’ve been building that into the Intercom Inbox. Now any customer and any agent can seamlessly converse, no matter their language.
Fin over API
So far, Chat has been the dominant interface for us to communicate with AI. Makes sense, it is familiar. But that is going to change, and soon. We’re seeing customers who want to build their own interface to Fin (our AI Agent) so we’re building Fin over API. Now, any interface is possible.
Giving Fin Guidance
When Support teams hire new people, they train them, they give them guidance on what to say and how to react in different scenarios.
They need to do the same for AI Agents, so we’ve been building that into Fin.
Today we’re launching an /ideas podcast.
The show brings together leaders to share how they’re reworking the way they build, operate, and think in the age of AI so we can all learn from each other.
These are honest, direct, reflective conversations. From overhauling product and engineering processes to reshaping marketing teams, we talk about the changes people are making, and what is working and not working.
In the first episode we talk about Intercom. Our product and engineering org is unrecognisable from 12 months ago, how we build software is very different, and we’re now doing the same with how we do marketing. We’ve learned so much building Fin, and we’ve plenty to share!
You can follow on YouTube, Apple Podcasts, Spotify or wherever you get your podcasts.
We hope you enjoy it!
What follows is a version of an email I sent our entire R&D team about an explicit goal and deliberate action we’ll take to become twice as productive through our embrace of AI.
Advancements in AI are precipitating the most transformative shift in software engineering of the past 25 years. It’s dramatically expanding what software can do and transforming how we build it. We are all novices in this new world, and that’s filling me with wide-eyed excitement.
If we were to literally hit pause on further advancements, I’m convinced any engineering team just leveraging the already existing tools effectively should expect at least double their current productivity – a 2x improvement. Yet most people and teams in the industry at large are not getting close to this today, they aren’t trying, and they probably don’t believe it’s possible, and even if they do, behavior change is hard and the forces or incentives aren’t clear yet.
Those who get the greatest yield will be those who believe in the power and potential of these new tools and push themselves to best understand and wield their power.
Intercom is p99+ in the industry at building AI products. We’ve been investing in AI for a decade, long before it was cool. When ChatGPT dropped, we were ready, we moved fast, made AI our #1 priority, and launched Fin the same day GPT-4 was released. Fin is the #1 AI Agent for Customer Service space, powered by one of the strongest ML, engineering and product teams in the industry.
When we initially used these new tools we were underwhelmed, but the pace of progress has been unprecedented. Models and tools built around them were getting better, FAST. As time passed the anecdotes we’d share or hear internally ramped up in volume and impressiveness. Our internal slack channels #ai-can-do-that or #ai-in-engineering-feedback are treasure troves – I’m inspired each day by the ways my colleagues are leaning in hard. We try to remove any friction that gets in the way of people using or trying new tools. I think we are doing far better than most companies on this journey – but we should aspire to be p99+ here too.
So, over the next 12 months, achieving this 2x productivity goal is not merely an aspiration – it’s an explicit goal. It’s critical, timely, and within our reach. We will make whatever changes are necessary to achieve this. Achieving this goal will be the combined focus of all disciplines within our R&D org.
I’m convinced the changes will be far bigger and more dramatic than this in the medium term. I toyed with titling this `10x`, which brings with it all sorts of connotations, but even then, on some relatively short time horizon 10x will underpitch the potential. With 2x we are simply trying to be grounded in what’s a realistic and tangible expectation for us to set for our first milestone.
Our pace of innovation has always been a competitive strength. We must fight now to maintain that, or we will lose it to companies born in an AI-First world. This goal represents that fight. It’s explicitly not a “nice to have”. It’s a hardened goal, it’s part of our expectations for designers, engineers, PMs. We will track ourselves as leaders, managers, teams, and ICs against it. Companies formed in this era will naturally be optimised around this, funding will flow towards the most visionary who are also showing they can execute faster than others, they’ll hire people who are leaning hardest into exploiting the frontier of what’s possible. Established companies will have to adapt fast or die slow-ish.
What would 2x actually mean?
Twice as much output is possible with the same team, and it’s within reach. This would mean:
- Executing our strategy faster.
- Taking on the projects that we’ve painfully had to deprioritise while we are capacity constrained. The ROI of these projects changes dramatically when the `I` is reduced 2x.
- Raising the ceiling on our ambition, on how bold and creative we can be.
- Raising the floor on quality, edge case bugs and papercuts in the product no longer need to be starved for attention.
- We’d have far more capacity to tackle technical debt in our codebase that contributes to us moving slower.
It’s worth noting this is an entirely different vector to “just hire more people” . Even if we allocated the budget to hire 2x as many people, at our scale, it’s highly improbable we’d double our team size in 12 months. Even if we did, that’d come at huge cost and tradeoffs, hiring and onboarding takes time and carries risk, so we’d be slower for a year or two hoping to then catch up. Many of these folks wouldn’t work out, that’s more hiring and onboarding. And even if you pull that all off, 2x the people almost certainly doesn’t give you 2x the output, maybe it gives you +50%, so now you’re taking the checkbook out again.
How do we make this tangible?
We’ve all seen the mindblowing 0 to 1 vibe coding demos (e.g. multi-player 3D flight game), a couple of prompts doing what could take days or weeks for a competent engineer, this can translate into 10-100x speed up. If all your work is of that nature – you’re in for a treat. But building out an initial idea is very different from iterating on real mission critical systems and collaborating with 100s of humans to do so.
We have a couple of massive code bases, our rails monolith, 2M+ lines of code, our JS front end for Intercom, 1m+ lines of code, and a few others for our AI systems, our infrastructure automation, our mobile apps, our monetization systems, our messenger, our websites, and a long tail of others.
Most meaningful changes are complex and span multiple of these, not to mention multiple people and disciplines and teams AND we need to take into consideration the impact to the tens of thousands of companies that use Fin or Intercom as a mission critical part of how they run their business.
Suffice to say, this isn’t easy mode, even getting to the first 2x will be hard fought. Here’s some of the areas of impact that I see aggregating together to get us past that 2x milestone. They are roughly ordered in complexity and potential ROI.
- Make humans faster at what they do. AI tools and AI augmentation. e.g. Better IDEs with inline support, tab completion, agent modes. A reasonable target here is that we all get about 50% faster at our work as a result.
- Enable non-engineers to contribute. This might be a PM or designer or EM making changes directly themselves (fix styling, make copy changes, perhaps fix bugs), rather than see those changes languish in a queue, and/or interrupt the focus of engineers.
- Reduce sync and collaboration overheads. Writing code is often not the bottleneck – it’s how we work together as humans. AI presents some opportunity to simplify this – and be less dependent on synching or handing off with other humans to make progress. Tooling that better enables engineers to ship code that looks exactly as designed reduces painful roundtrips and reviews with a designer. Excellent AI code review, means you are not waiting to interrupt a colleague to get actionable feedback on your work. We have an advantage here as many of our team are well able to flex into adjacent roles to some extent, engineers that could be product managers, designers who can code, PMs with great design instincts; these overlaps enable us to be more autonomous as individuals at times.
- Make ourselves redundant for parts of the jobs we do today. Some parts of our job, that others rely on us for, *could* be instead done directly by the people that need it. As an expert in that job, if you can find a way that AI (or otherwise) can enable your ‘customers’ to do it themselves as easily as ask you to do it. In doing so you’ve not just freed up your focus for higher impact work, you’ve reduced their wait time, enabling them to complete their task quicker too. (e.g. infrastructure engineers, instead of manually fielding requests to spin up additional clusters, can provide strong templates, guardrails and automation so that the teams that need it can do that themselves)
- Recognise the problems where AI can give you 20-100x lift. This is especially relevant to work that follows a repeated pattern. Or problems that can be shaped to look like this. For example, we’ve worked hard to enable Fin to work on any customer service platform. It was months of hard work to figure out how to do that well for the first, weeks for the second, and now we’ve an understanding of the shape of the problem such that with use of our AI tools, it’s closer to hours or days to extend this to the next system we encounter demand for. Sahil had a great example of ~40x lift on the How I AI podcast with Claire Vo.
- Send large quantities of relatively simple work to an army of AI agents. There are some types of work that are plentiful but only have a high impact if you can do a huge volume of it. Rather than make your engineers 50% faster at tackling this endless stream, find ways to harness AI agents to do this work entirely, breaking the human scaling bottleneck. Often this is work that is harder to prioritise, but is constant toil, which you either pay for as friction, making it harder for you to do other work, or tax, something you need to keep paying away in the background to keep the friction at bay. Early examples of this are dead code/test deletion, unused feature flag removal, issue and exception triage and fixing, framework or dependency upgrades, code base refactoring.
In short, getting to 2x is a blend of raising the floor, making humans faster at what they do, finding occasional opportunities for home run hits, and finding ways to get work done without bottlenecking on other humans.
How will we measure it?
Ideally I’d like to measure how long it takes us, on average, to bring something from idea to being in the hands of our customers. Can we cut that in half consistently? This is a full team sport involving all disciplines in our R&D org. If you were to think about t-shirt size estimates, we’d be putting them all in a hot wash and shrinking them down a couple of sizes. I can’t think of a great way to operationalize that today, so we will start with something potentially flawed but pragmatic.
Our culture is already quite optimised around continuous delivery; Shipping is our heartbeat (our teams ship hundreds of PRs per day). A change that makes it to production is a reasonable proxy for impact. We have separate mechanisms that ensure we are working on the right things, and that the work we do is good quality.
So, we will measure our progress here by measuring the average number of merged pull requests (PRs) per engineer per month (others have used this measure too). Our emphasis should be on the system that results in this output metric; on the efficiency in how we work, how we collaborate, how we leverage AI and other tools. We’ll be sure to look at other signals to make sure quality remains high and increases in this metric are actually correlated with impact.
This number goes up when non-engineers can make changes directly. It goes up when AI agents can make changes autonomously (or at least with human approval). It goes up when engineers find ways to be more productive themselves, or less reliant on handoff or synching with other humans. Obviously not all PRs are equal; small PRs can be super high value, large PRs can be low value, but as a proxy it’s good enough. We also already see some durable improvement on this metric already in the last few months (~20% YoY), giving me confidence that we can move it much further.
There are of course ways using this measure could be misused, or dumb unintended behaviors that emerge as a result – so some caution is needed. We will keep track of how this metric is working in practice, and iterate where we see opportunities to sharpen it. Despite valid concerns – such as the risk of cynical gamification – we believe it’s important to measure this and to be transparent about it. We trust ourselves and our teams to use it responsibly and with high utility.
Using this metric in isolation to try and measure an individual’s performance can be problematic, comparing two individuals on this metric alone is not a high quality signal. But using it as a lens to assess the health and productivity of a team or an organisation is incredibly powerful. Your org is a factory, the production line spits out Pull Requests, we need to understand and optimise the factory to maximise the throughput of PRs.
These two similar teams have quite a different PR throughput, why is that? What is different about the team and environment that is causing that? What can we learn or change? This engineer has the lowest throughput in the org, why is that? This team reviews and approves PRs far more quickly than the rest – what can learn from this team?
How will we achieve this 2x goal?
Honestly, that’s not all figured out. This message isn’t attempting to figure out the entire plan; it’s about setting the direction and initial goal. Some amount of the necessary change is happening organically already – there is good situational awareness amongst our team of how things are changing in our industry, and a curiosity to adapt. Our managers and leaders are already adapting their leadership focus to support this goal.
One excellent piece of writing and advice I often go back to is called ‘Demanding and Supportive’ (by Ravi Gupta). We should be very demanding of ourselves and each other, that’s reflected in our goal, AND we should do everything we can to support each other to be successful against this goal. A huge part of achieving this goal will be providing the support that makes it easier for everyone to be successful; this will include everything from frictionless access to the best tools available to regular and high quality training and enablement that accelerates the rate of learning across the team.
Over the coming weeks and months we’ll share and discuss various ideas or changes we are making that will help contribute towards this goal. We’ll share these internally and publicly on our blog. These will include everything from the changes we are asking of leaders, changes to our hiring, tweaks to our performance process, changes to cultural practices like code review, how our various roles are evolving, such as how designers are changing their tooling and workflows or how designers and PMs contribute directly to our software or how our researchers and analysts use AI to provide better insight faster. All this and more.
As an aside, the higher level of demands we will place on ourselves simply reflect how our industry will adjust over time too – I know we are already screening potential interview candidates based on them having strong examples of using AI to be more effective in their jobs.
What am I doing so far?
Especially in times of change, I feel strongly that managers and leaders need to be close to the detail, close to understanding how teams are working, the problems they face, and seeing first hand what’s working or not and where the opportunities are. This is very much in the spirit of Genchi genbutsu. I’ll be spending at least 1 week per month embedding with our engineering teams. Last week I spent a few days working with one of our staff engineers, Peter, exploring the challenges we face shifting from our now deprecated use of Ember.js to our preferred use of React for our front end applications. We see far higher productivity and frankly developer happiness working on React – and the AI tools are far more effective there. We were exploring ways we can make this shift faster, porting/rebuilding parts of our application, and how we can encourage this shift etc. I’ve also spent more time meeting with founders of companies building AI tooling for engineers, to understand how these tools will evolve and which are most promising, and I’ve spent time talking to industry peers 1-1 and on podcasts about this topic, and writing and discussing it with leadership teams internally.
My advice to you?
A common sentiment I hear is that “I’m too busy to properly try these new tools”. I get it, we are all working against challenging deadlines, or snowed under in meetings or interviews or reactive work. With the belief that the payback will be worth it, we have to punch through those excuses. Take time off the production line to just play, to experiment. In our developer surveys we know ‘Not having time’ is the primary reason people cite for not trying new tools. Managers and leaders will support you taking the time to skill up. Aside from time during your work day, if ever there was a time in your career to lean into your craft it’s now, turn off Netflix and put down the doomscroll device and just start playing with the new tools. Try a task once, aiming for AI to solve it entirely, if it works first time, you fluked it, when it doesn’t work, reflect on what you could try differently, then try that, rinse/repeat 10 times. Use different tools. Get a feel for which works more naturally for you. This is more fun in pairs, as you can spark off each other, and both try different approaches to the same task in parallel.
Start every piece of work with a mindset of “there must be a way AI can help me do this quicker/better, I’m determined to find it”. I expect every manager will be supportive and encouraging of you carving out time, pushing back the occasional deadline if necessary in the near term. I also expect managers to themselves get more hands on and close to the work on their teams, and familiar with the tools too, so they can better support and influence the journey to 2x and beyond.
Buckle up!
Like I started with, 2x is simultaneously a conservative milestone to aim for, but also one that will be a massive game changer for our customers and our business. We have by no means figured this out, I know there’s a degree of naivety and optimism behind this, but also complete belief and determination. It’s quite probable that changes in what’s possible will completely change the calculus here. Tools are improving at an insane rate (e.g. recent Claude 4 release, OpenAI Codex etc), and there are so many companies building products that chase the potential here. Fundamentally, this is about the interplay between humans and tools – the upside primarily hinges on shifts in human behaviour. If we merely sit back and wait passively for our tools to improve, we’ll fall short in absolute terms and relative to others. We must acknowledge that we’ve all become novices again, and commit to charting a fresh path toward mastery with these new and evolving tools.
We’re more than 2 years into the LLM-driven product world, and we’re still only just starting to understand how AI challenges fundamental assumptions about the products we build and the services we offer.
It’s now also changing the metrics we use to measure success.
Last year, we surveyed 300 customer service leaders and asked them: “If your support tool could do one thing really well – improve support efficiency or improve customer experience – which would you choose?” 78% of them said their top priority is to improve customer experience.
And what’s the primary way just about everyone measures that? CSAT – the customer satisfaction survey.
The problem is that CSAT just doesn’t measure up. It has poor coverage and gets biased results. This is no secret or surprise. But until now, there’s been no better alternative.
We all suffer from survey fatigue
We are all bombarded by satisfaction surveys. We get them for nearly everything these days: taxi rides, restaurants, haircuts, package deliveries. Every business is eager to know how well they did.
This saturation has created survey fatigue. When was the last time you actually completed one? Maybe when you were particularly delighted or thoroughly frustrated. But most of the time? You ignore them. I ignore them. Everyone ignores them.
Let’s look at the hard numbers: across all our customers who use CSAT, the average response rate for our little satisfaction survey, which we explicitly optimised for simplicity to maximise response rates, was just 21%.

But the actual coverage is even bleaker: surveys are sent out to only 39% of conversations, so in total only 8% of all conversations actually received a CSAT score.
That means teams are blind to the experience of over 90% of their conversations. Let that sink in. The metric most customer service teams live by—the one that determines bonuses, drives strategy, and gets presented to the board—ignores 92% of what’s actually happening.
Coverage is the achilles heel for surveys.
Customer service, uniquely, doesn’t need surveys
The reason there are so many surveys in the world is because there’s no other way to find out what the customer thought. Your experience at a restaurant or hotel is basically invisible—there’s no way to say to someone on your restaurant service team: “Hey, can you review all the dining experiences our team delivered this week?”
But the customer support world is different: it’s all recorded! There are transcripts of the whole conversation, whether it’s in chat, email, or phone.
You absolutely could ask a team member to review all your support conversations, but you don’t, because that would simply take too long. It’s all accessible, but reviewing them is not scalable.
Surveys are a short-cut to solve the scalability problem. Now with AI, we don’t need that shortcut anymore.
Because of those transcripts, service conversations are uniquely well-suited to AI evaluation. The transcripts offer the raw material for AI to evaluate. And scaling the evaluation of that raw material is a snap for AI. Just point it where you want it; it will review everything.
The new AI-driven Customer Experience Score
What we’ve built is straightforward: our new Customer Experience Score (CX Score) evaluates each conversation and gives it a single score on a scale of 1-5, based on three inputs:
- Was the customer’s issue actually resolved? And if they had multiple issues, were each of them resolved?
- What was the customer sentiment (if any is detectable)?
- What was the quality of service received (in terms of tone, knowledge, timeliness)?
We also output a short explanation of why that score was given.
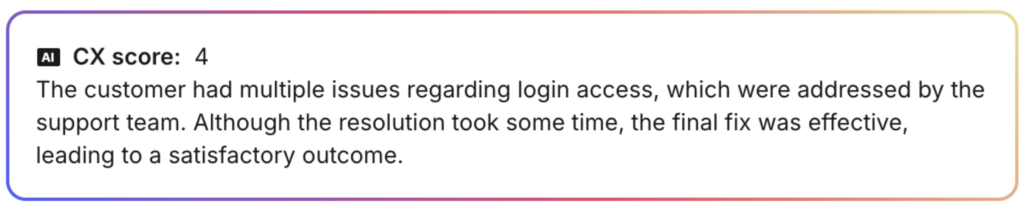
Here are a couple examples of a high CX score:
And some examples of a low score:

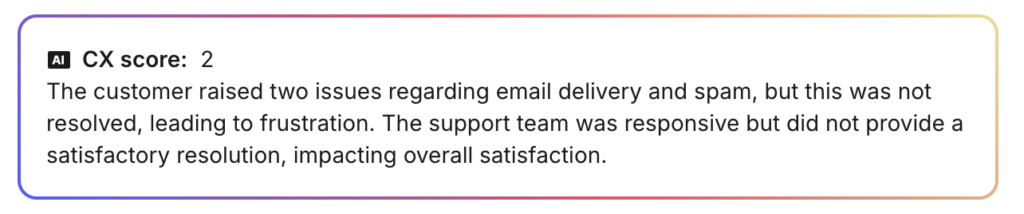
As you can see, the AI doesn’t just give a score – it provides context about what happened and why.
Just imagine asking a human to analyze thousands of these conversations and write thoughtful evaluations for each. They’d quit after an hour.
But the huge value is in the massive increase of coverage. Now you can actually spot all your concerning support interactions, review them, and figure out how to fix them – while receiving a more accurate KPI too.
This new way of measuring exposes uncomfortable findings
When we compared AI-driven CX scores with traditional CSAT across 53 customers covering multiple industries in B2B and B2C, we found some fascinating patterns.
(Note: our score follows the same approach generally used for CSAT: the percentage of conversations rated 4 or 5.)
Finding #1: Your team is probably not performing as well as you thought
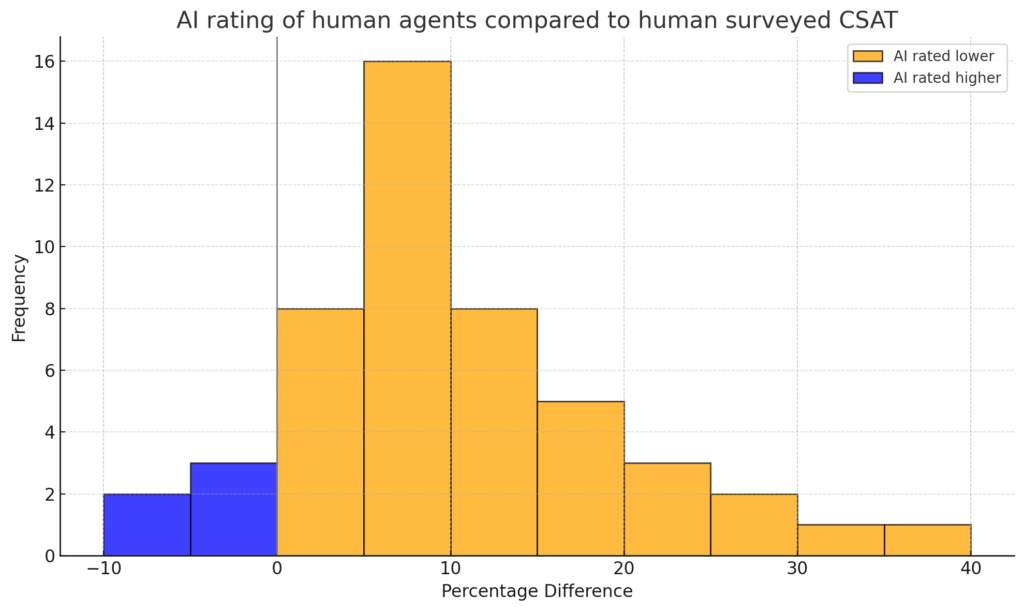
For support conversations involving only human agents, we see a 10% decrease in the CX score compared to the surveyed CSAT score:

For most teams, this is a sobering reality check – AI says they’re performing meaningfully worse than they’ve been telling themselves.
In the distribution graph below, you can see that this pattern was true for almost all customers. And sometimes that difference was quite dramatic.
Why the difference?
The data shows us that conversations with surveyed CSAT have a CX score that is 13% higher than conversations without a CSAT score. So we see evidence of a response bias – people who had a positive experience are more likely to fill out your survey.
In other words, that CSAT coverage problem is resulting in an accuracy problem.
Finding #2: Your AI Agent is performing better than you thought
For support conversations handled entirely by AI agents, we see the inverse pattern – AI consistently rates our AI agent (Fin) higher than humans do.

And again if we look at the distribution, we see this pattern is consistent across almost all customers.
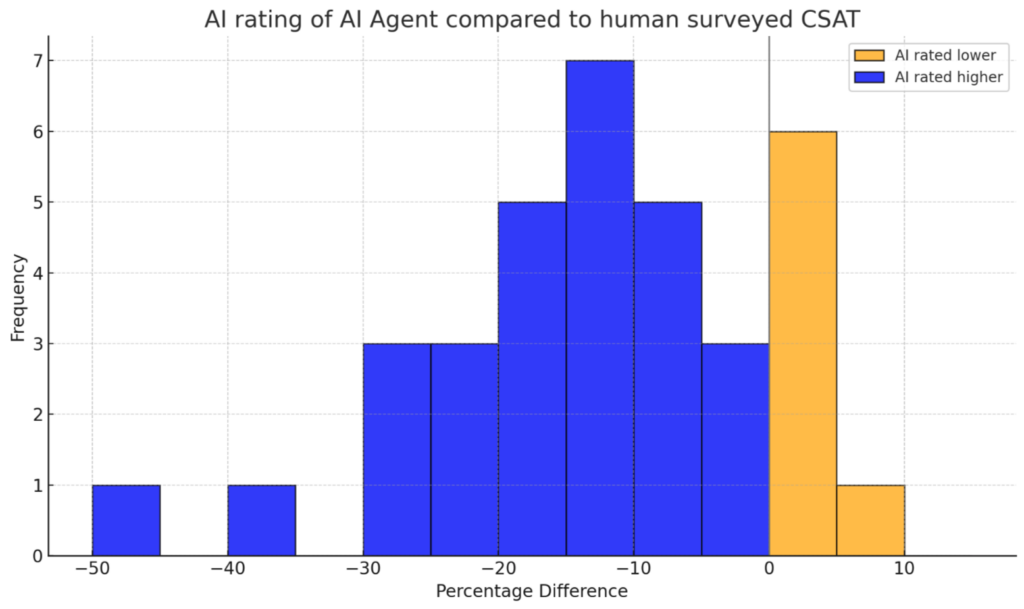
Why is this?
Unlike with human CSAT, we don’t see evidence of a response bias in the data.
Outside of our datasets, there is broader evidence that humans tend to rate bots more harshly. Here’s one study from last year that found evidence for this bias in a customer support context:
“Study participants reported significantly lower satisfaction.. following interactions with a chatbot compared with a human agent in both positive and negative service outcome conditions. The effect was fully mediated by the service-giver’s perceived empathy“
The irony here is notable: the AI tool we’ve built to objectively measure customer experience reveals our own subjective biases against AI assistance.
Not yet a finding: humans compared to AI Agent
You probably noticed in the table above that the CX score shows our AI Agent performing better than humans.
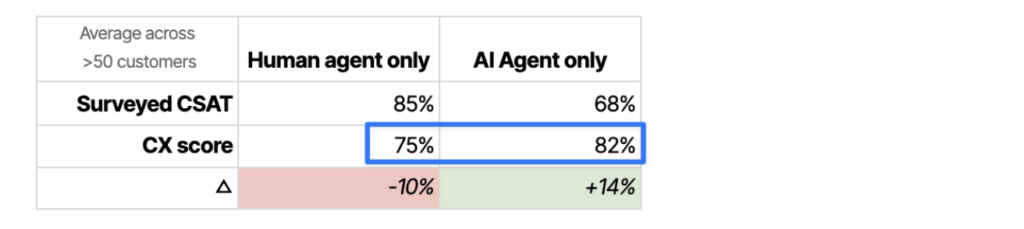
We don’t rate this difference as reliable. It’s an unfair comparison because, at least for now, humans have to handle the messier, harder, more complex queries and are more likely to deal with frustrated customers.
Can we really trust AI?
It’s hard not to be skeptical of all this – can we really trust an AI score for something as subjective as customer experience? Particularly when you see that AI rates AI higher?
It’s critical to be able to trust a metric. So we had our most experienced support agents manually review and score 2000 support conversations. That gave us a dataset we could trust. Then we applied our CX Score to rate the same conversations. Finally we ran an F-score analysis, which balances measuring false positives and false negatives. The result was 0.8. That’s high. In most real-world machine learning systems, especially in language and support, anything above 0.7 is considered strong. So 0.8 tells us it’s performing at a high level and closely matches human judgment.
So we believe this metric is valid.
The real value is not in the number, but the spotlight it provides
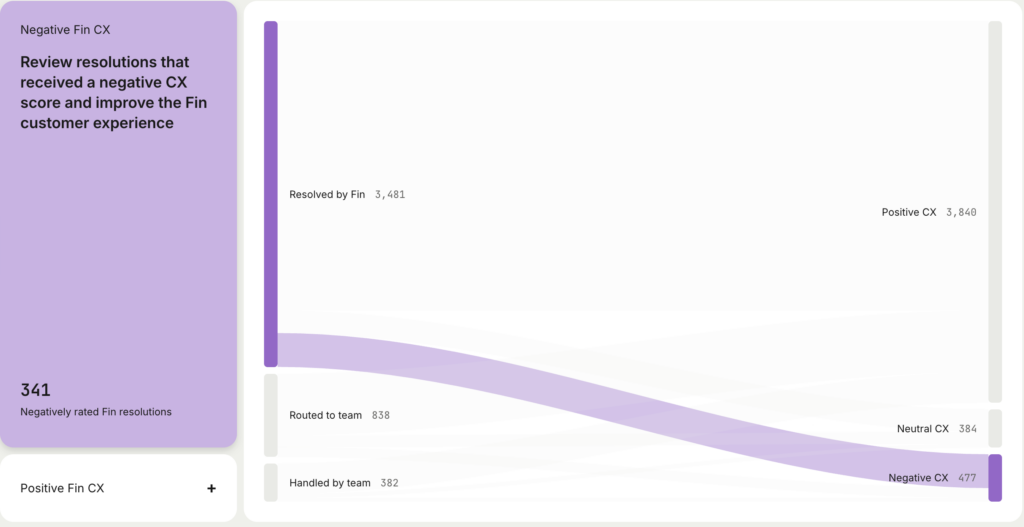
It’s easy to anchor around the changes in scores, but the real value is not in a more accurate baseline. Instead the real value is the ability to identify far more conversations that you should be looking at.
One of the ways we expose this is in this optimisation report, which shows conversations that were fully resolved by our AI Agent, and therefore your human team is unlikely to see, and which had a negative CX score. So these are worth reviewing, and some of them you will want to follow up on. (And if you do follow up, they won’t be counted as AI Agent resolutions.)
If you relied on surveys, you would be blind to most of these conversations. That spotlight capability is the real super-power here.
Not just theory; here’s the real experience of switching to the CX score
We of course dog-food our own product; but in this case, the product team actually followed our support team’s lead in defining these metrics. Our support team has been working with the CX metric for quite a while now.
Here’s how Intercom’s numbers look:
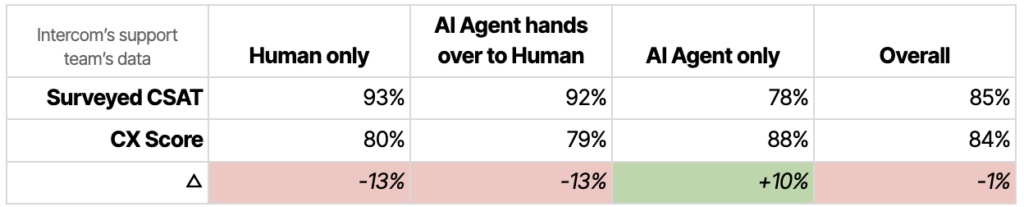
And here’s how Franka, a Director of Customer Support at Intercom, has adapted to it:
“If you are a support leader out there I ask you – what do you think your “real” CSAT would be if you got 100% of responses back? You and I both know it’s not in the 90s as you are presenting every month in the Monthly Business Review. But it can still be shocking to see it for real.
When we developed this metric internally I nearly didn’t want to believe it. I didn’t want to think my team’s performance was actually closer to 70% or 80% CSAT (depending on the week). But I did want to look into it some more. I wanted to see what it finds. And found it did.
Conversations where customers were saying things like ‘Oh looks like we are not premium enough for you, guess I’ll go speak to your competitors’ or ‘Hey why are you ignoring me’. It flagged conversations with no surveyed CSAT, conversations we didn’t review and we never would have found manually looking through thousands of weekly questions we handle.“
We’re seeing things we just couldn’t before. CX highlighted areas of the product where satisfaction had been slowly declining for months—things we’d never catch in quarterly reviews. Now we can act on them in real time.
It helped us realize where we’d been accepting mediocrity. CX turned a blind spot into an opportunity.
You can’t fix what you can’t see. CX shows us everything. And that’s exactly what we need to get better.”
Culture Amp, a company who knows a thing or two about surveys, has been an early user of our CX score. Here’s what Jared Ellis, their Senior Director of Global Product Support, told us about their experience with it:
“CSAT was becoming such a problematic metric… we have entered a realm with customer satisfaction where the feedback was no longer kind of hitting that quality… In fact, one of my managers came to me and said, ‘I haven’t had a single CSAT response that I’ve been able to coach one of my team members on for about two or three months…’ And we definitely didn’t have the quantity in order to really find the actionable results… We were worrying more about the metric than we were about the feedback.
When this customer experience score popped up and I heard about it, it just triggered something in me that went, I’d never thought about it that way… being able to get some form of insight from just about every conversation that your team is having is suddenly a treasure trove.
The surprise for me was that it did [feel familiar]. And the feedback that it was producing was something that was quite actionable, was understandable, and that, yeah, I felt like teammates could actually do something with.“
I think the biggest difference that customer experience score has made for our team is that we can now understand what the neutral feelings from our customers are and actually take action to improve our overall service by really getting into the meat of it.“
The end of “good enough” metrics
The AI-driven Customer Experience score isn’t just a better version of CSAT – it represents a fundamental shift in how we measure customer experience.
Surveys were a necessary compromise in an scalability-constrained world. That world no longer exists. Continuing to use surveys as your primary metric in 2025 is like navigating by stars when you’ve got GPS.
This shift compels us to confront a broader question: What other “good enough” compromises are we clinging to? What other metrics are we accepting at face value because “that’s how it’s always been done”?
As more work becomes AI-driven instead of just AI-augmented, many metrics we use will change. It’s incumbent on us to challenge our assumptions not just on how we deliver a service, but in how we measure it.
The single biggest transformation we’re seeing in Customer Service is the transition from Support Leader to AI Support Leader. There is a lot going on in this, it’s not as easy as updating your LinkedIn title and asking for a payraise (though be my guest), there are new roles in your org (e.g. who designs AI workflows, who builds your Fin Tasks etc.) , and new priorities (your help docs are suddenly mission critical infrastructure).
As AI Happens™️ to every industry, we see the same story. It starts with augmenting your team and Copilots while everyone tells themselves nothing will really change (aka the Cope-pilot stage).
It quickly upgrades to Agents that actually do the work, and once that starts people have lots of questions, questions like…
- How do I measure if the work is getting done (that’s what this post is about)
- How quickly will this happen? (this post on timelines)
- Shouldn’t we build our own Agent? (sure thing, you’ll be back though)
- If >50% of the work is now Agents, what are my new metrics?, (this post on metrics)
- What’s my org chart look like in a world where 1 Agent is doing half the work? (this post is to follow)
- What are the new roles & responsibilities here? (to follow)
- and a whole heap of other questions yet to emerge (let us know what you want answered)
We have so much to say about this transformation, the new org charts, the new roles, and we’ll get to it all
For now though there’s two things everyone needs to understand, specifically about evaluating different agents based on AI Resolutions, so let’s start there:
Note: Resolution Rate means "Of the questions the AI Agent is involved in, what percentage does it resolve". The points I'm making in this post are about comparing agents against each other given the same setup.1
1 – Every percentage in resolution really matters
If one agent costs 99 cent a resolution and claims to do 72% of your volume (might sound familiar) and another can do 35% but is absolutely ✨free✨, you might auto conclude “we’ll go with the free one“. And who’d blame you? No need to talk to your CFO, no need to load up your procurement tool, just pull the trigger right?
The maths you’re intuitively doing is something like this
My Conversation Volume × 72% × $0.99c = $$$
versus
My Conversation Volume × 35% × 0.00c = $0
It’s easy to pick the winner, but you’re playing the wrong game.
The right game is to talk about Total Cost Of Running Support. You need to ask yourself “What’s happening to the queries that the AI doesn’t handle“
The answer is humans, humans are happening to them. This means you’re asking your support team to shoulder the burden of these queries when in reality there’s loads more valuable work for them to do, and you’re still growing your team’s size as your business (and thus support queries) scales.
The fully loaded cost of a human handling a support ticket is something approximating the % of their fully loaded salary + all associated costs for the person. So for easy maths let’s say your support person is $4k a month, and handles 25 tickets a day, with 20 working days in a month that’s $8 per ticket. Obviously this ignores a load more complexity, e.g. have you heard of Payroll taxes, health insurance, benefits, equity, laptops, software licences per seat (Slack, Zoom, Zendesk, G-Suite), management overhead, and that’s before we get into office spaces etc. Let’s be optimistic and say the $8/ticket turns out to be more like $10/ticket.
Okay, so at $10 per human support resolution, and a choice between 99c and 0c for AI resolutions, how does the maths play out if you have, say, 100,000 conversations per year? The answer is like this…
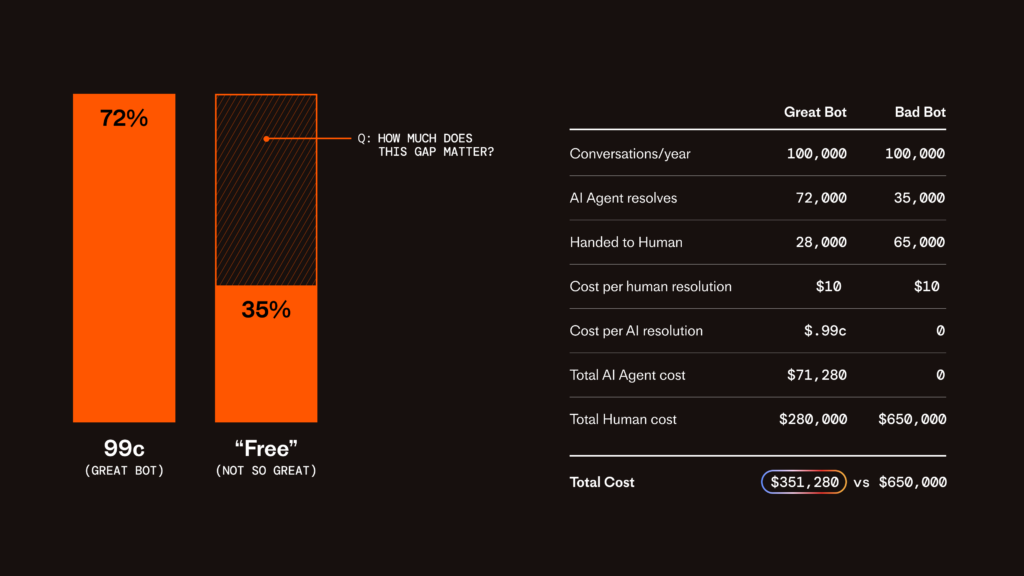
? The job of an AI Support Leader is to minimise human handover, not to minimise dollars spent on AI resolutions.
2 – The hardest percentages matter the most
Most queries to your team are not the basic “how do i reset my password” ones. They’re messy ones that require information from multiple sources to answer. As we discussed in Good Bot / Bad Bot, it’s important your agent can do the hard stuff.
But your AI Agent also needs to move past informational queries (e.g. ones answered through text alone) into personalized queries (unique to the user) and into action-based queries (e.g perform an action in another system).
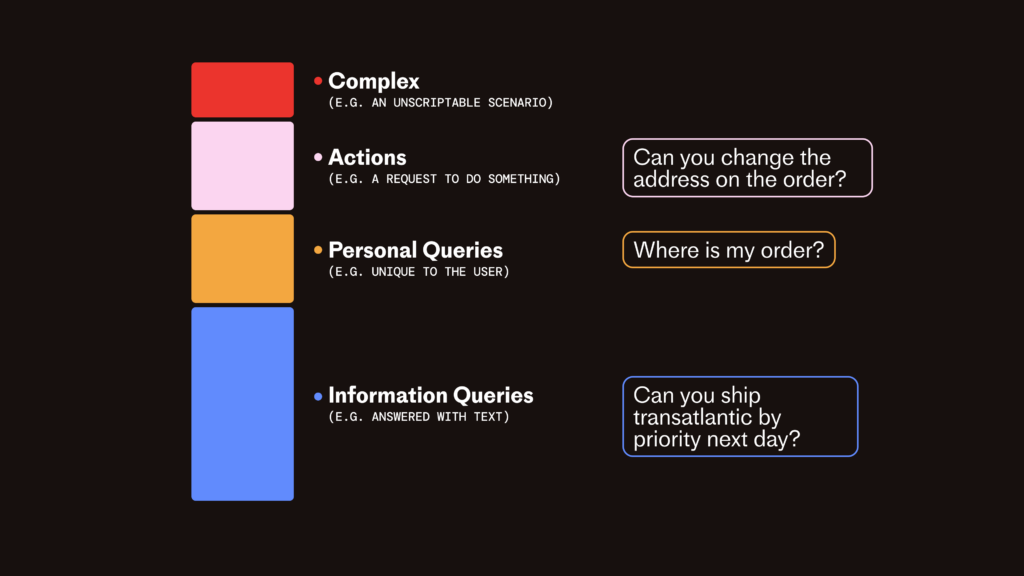
These are often a smaller percentage of the total volume, but they’re a larger percentage of the total time spent by your team. This is why we built Fin Tasks – we know that to really deliver on the promise of AI Support, we have to complete the messy harder queries end to end, to leave no crumbs as the kids say. (I know, I can’t believe I wrote that either)
The right way to think about these less frequent but more painful queries is frequency × handling time. Which looks more like this…
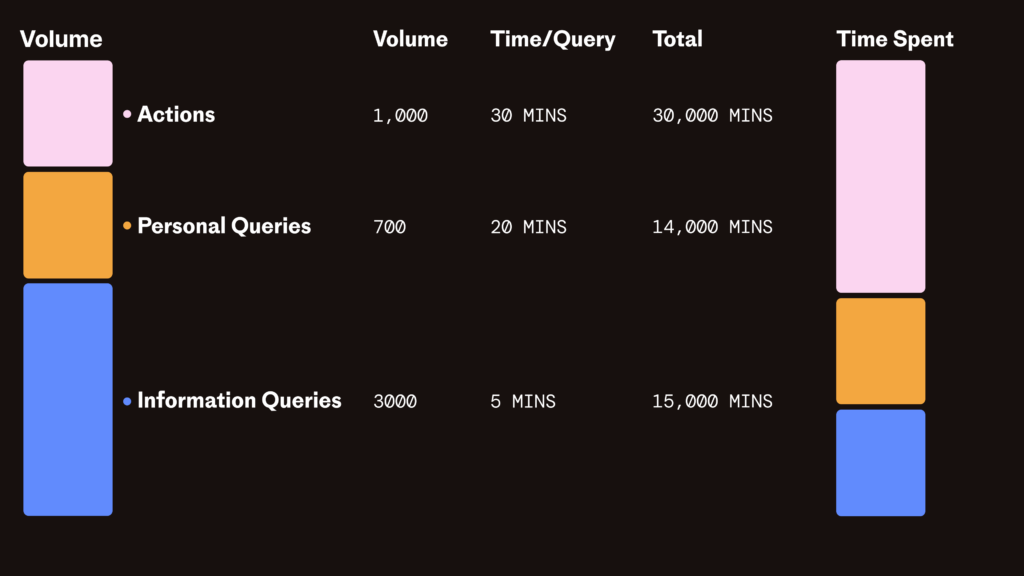
? The job of an AI Support Leader is to minimise the time wasted on repetitive actions, not just automate extremely frequent questions.
Ultimately the first step when moving to AI CS is picking the best agent for your business and it putting it live. The second step is ensuring that you’re minimising handovers and minimising repetitive schlep work. If you get those two done, you’re ahead of the majority of your competitors, but you’re not done, not by a long shot…. we have so much more to show you. Stay tuned.
- When you’re optimising your agent, once you’ve picked one, your actual goal is just “total resolutions” (in the same way that when you’re evaluating a website design you care about conversion rate, but once it’s live, you care more about total conversions) ↩︎
I was going to title this ‘Why can’t we let self-driving cars kill anyone?’ but I thought that might be a bit too much.
Nonetheless, the facts don’t lie. Human drivers kill 1.3 million people every year. Think about that number for a moment.
Meanwhile, whilst it is early, numerous studies show that self-driving cars are often safer, but there is uproar if a self-driving car is anywhere near a fatal accident. One death, and we’ve pushed the acceptance of the technology back years.
In fact, this pattern of humans holding new technology to a much higher standard than they hold humans to, even when there is overwhelming evidence that the new automation technology is better, is very common throughout history. Automation is judged harshly for minor imperfections, whilst major human errors go unnoticed. There are important implications here for anyone designing AI products. When we study this, we learn that there are multiple human biases at play, and they show up consistently across many examples:
- Automated elevators: People wouldn’t use them without a human operator, despite significant reductions in accidents. People complained about doors occasionally opening slightly off-level with the floor (yet human operators were worse), or had momentary hesitation or slight jolting before moving.
- Airline autopilot: Massively improved flight safety, far exceeding human pilot reliability. Yet mistrusted by pilots for minor imperfections such as slight deviations in assigned altitude, slightly jerky movements during course corrections, and (can you imagine!) overly cautious approaches and landings.
- ATMs: Criticised for slight delays dispensing cash (despite the huge queue inside the building), and slow user interfaces. Customers preferred human tellers, despite them making many more mistakes.
The list of new, better technology, being held to previously unseen high standards, and judged for minor imperfections goes on:
- 1900s Automatic telephone switchboards
- 1930s Automated traffic signals
- 1970s Industrial robotics in car manufacturing
- 1980s Automated stock trading systems
- 1980s Automated subway trains
- 1990s Digital medical diagnostic tools
- 2000s Automated voting machines
I’ve been thinking about this a lot because we see a similar, fascinating pattern when new customers try Fin. In evaluating what Fin can do, and Fin’s performance, many customers hold Fin to a much higher standard than they hold their human team to. Even when Fin is faster than humans, and more accurate more often, the feedback is ‘Fin is too slow’, ‘Fin made too many mistakes’.
For example, Fin can issue refunds to customers. To do so, Fin needs to:
- Check the product purchase history
- Check the refund policies
- Check the customer record
- Approve
- Talk to the payment system to issue the refund
- Get back to the customer to tell them the refund has been approved and issued
- Update all customer records.
For any AI Agent to do that accurately, consistently, is impressive. But it might take 90 seconds.

Few humans can do this in 90 seconds. They take way longer. Sometimes up to a day.
Fin will do this in 90 seconds, and often less, every time. When we should be thinking ‘This technology is like magic’, we judge it harshly instead. It’s like everyone’s experience with airplane wifi. Instead of thinking ‘it’s amazing I have the internet up here in this flying box of metal’, we think ‘this internet speed is shit’.
Sometimes Fin can make a mistake, or a minor misunderstanding. And people think ‘Fin made a mistake with that answer, this technology isn’t good enough yet’. Yet their human team makes way more mistakes all the time.
Why is this? And how do we design for it?
We can’t try and persuade people to abandon psychological biases that have existed for hundreds of years. But we can study them, and design around them. In this case, there are three main ones:
Automation bias leads us to over-scrutinize automated systems. Our brains naturally offload cognitive tasks, creating discomfort when we lose perceived control, and this discomfort magnifies minor technological imperfections.
Possible solutions:
- Products need to clearly show users how and why automated decisions were made. If you’ve wondered why AI tools expose so many events, even when they move past at incomprehensible speeds, now you know. We’re exploring different ways of making Fin’s reasoning visible and understandable:

- Remind people of the facts, showing real comparisons between AI and Human performance. We do a lot of this in Fin Reporting.
Status quo bias makes us instinctively resistant to change because we fear losses more intensely than we desire gains, leading to irrational preferences for familiar human processes, even when automation is demonstrably better.
Possible solutions:
- Introduce automation incrementally, mixing familiar interactions with new automated experiences to ease users into acceptance.
- Leveraging familiarity by designing automated interfaces and interactions that closely mirror familiar human-based workflows, reducing cognitive friction.
We designed Fin to blend deterministic and generative workflows. This makes it easy for many to incorporate Fin into their existing workflows as a first step. We encourage customers to rethink their whole setup, but sometimes this is the best way to get started.

The availability heuristic causes us to judge the likelihood of events based primarily on how readily specific examples come to mind, rather than relying on accurate statistical assessments. This cognitive shortcut arises because the human brain prioritises information that’s vivid, emotional, or easily recalled. As a result, rare but dramatic incidents, such as a single highly publicised automated mistake, are disproportionately memorable and thus perceived as more frequent or dangerous. Conversely, everyday human errors, though statistically far more common, lack the emotional intensity and vividness necessary for easy recall, making them significantly underestimated in our risk perception.
Possible solutions:
- Prioritise extra effort in designing initial user interactions to be smooth and error free
- Amplify positive experiences to create memorable narratives
- When errors occur, transparently communicate how rare they are compared to overall success.
Remember that AI products are new. Many will suffer from these biases and more, and if we want fast adoption timelines, we will need to design around them if the products are to be successful.

Reality: The vast majority of the Chat bots on the web are total dogshit. That’s probably an insult to dogs, and maybe even to their shits tbh.
Brands somehow mindlessly throw a half-trained ugly monstrosity on their site, dust their hands off, and claim to have Joined The AI Revolution™️.
What’s going on? What is causing so many otherwise great companies to totally drop their guard and ship stuff that’s just awful for their customers? Especially now, given that AI Agents can be actually good. We see Claude and its rivals handle messy complex queries all the time, so why are these CS Agents still so derpy?
The answer is simple but sad.
Companies often just don’t know the difference. They don’t know a good bot from a bad bot. When they’re buying on they rely on extremely simple evaluations: “I asked it how to reset my password, and it got it mostly right…”. That’s true, but it’s not a sufficiently hard test. If Einstein and I both sit my daughters first grade arithmetic exam, you will be shocked at how close I am to Albert Einstein. Shocked!
This is one of our failings in the customer service industry, we need to help people evaluate an agent so they can really see the difference. At Intercom, once a customer deploys Fin, vs anything else, they get it pretty quickly (even when we let them down), but it’s hard to see these differences a priori.
So here, my dear reader (and also my LTV:CAC positive prospects nurtured by Marketo, you are dear to me too), let me start the ball rolling by explaining a few
A good bot easily answers hard questions, a bad bot barfs on them
To the Einstein point above, you won’t know a good one from a bad one until you ask it a hard question. But “what is a hard question” is, actually, a hard question itself (how meta). Here’s how I see it…
A simple question usually has a 1:1 mapping with some help sentence easily found in an article and is often common. e.g. asking a project management app “how do I start a project”.
A “hard question” needs lots of information from lots of sources, the user’s current state, the screen they’re on, information from multiple internal-and-external docs, the previous answers given by support reps and more. Reality is messy:
e.g.“Why can’t I see the SSO button on the mobile app?” could be because SSO isn’t enabled, or because the user isn’t on the enterprise plan, or because you can’t access SSO while on trial, or maybe it’s a recent bug, or maybe the user is wrong, they just need to scroll-the-fuck-down and the support team are sick of explaining that thankyouverymuch, and it can even be two or more of these things together. Reality is messy. Simple bots can’t handle this.
A good bot lets your users express themselves quickly, a bad bot is just buttons all the way down…

In tech we’ve gone from the command line (efficient & arcane) to GUI (easy but slow), to Superhuman-style Command K (efficient & more discoverable) and now with AI Agents we’re on the brink of actual “text UI” (aka AI UI). Just type (or say) the thing you want! Each of these has their merits, yet somehow bad bots can still default to the worst of all cases. Good bots capture all the context and have no amnesia.
A good bot ‘does the thing’, a bad bot ‘tells where to go to to find out how to do thing’

This is self explanatory but if you’re looking to delight your customers then you do the thing they want. Good bots take actions and follow processes, bad bots hand over all that complexity back to the user. When a bot actually solves your problems, you’re way more inclined to use it again & again.
A lot of our competitors like to say wild proclamations e.g. “we do 97% of your volume” , “we do 99%”, “yeah, well we do 107%, we actually ask your customers questions” (that sounds like a silly idea, it’s not, more on that another day…). Anyone who has worked in support knows these numbers are often bullshit. In the previous era of bad bots, what it meant was “yes we can tell your users how to reset their passwords, but everyone else we just kinda frustrate & deflect“.
A good bot knows how and when to escalate to humans, a bad bot is ‘always or never’, or worse a “bot jail”
As the now popular blog post says Reality has a surprising amount of detail. This is what makes 100% extremely unlikely. Here’s one little example: Last week I jumped on a call with a Fin customer looking to use our tasks feature to handle all their “change name on utility bill” type queries. My confidence lasted all of 3 minutes, when I listened to phone call #2 which began with… “Hey, so, I’ve recently gone through a divorce, the bill is in both our names, but it’s his credit and he moved out so I now need to separate the bill, and change the credit card” (details changed, but you get the idea). While Fin can definitely handle a simple or messy name change and even a multi-party request, Fin isn’t touching that one. Nor should it. Fin hands that one over. There are times when humans need humanity. The support rep did an amazing empathetic job of it, credit to them.

Humanity aside, It’s also the case that sometimes no matter how clever the agent, some human approval step is always needed, which is why you’re best off designing for that scenario too.

To paraphrase Captain Barbossa (yes, an obscure one I know), “Ya best start believing in human handover, because you’re living in it”
A good bot follows your unique policies and guidance, a bad bot thinks you’re identical to every other company

How, when, where you handover, how you speak about customers (are they guests, patrons, passengers, investors), what words you should never say, or always say, etc, are all unique to your company, your brand, your business. You need the ability to control it all. A bad bot is designed for some extremely abstract “business<->customer” relationship and/or is editable only by forward deployed engineers, meaning every time you update a policy or product name you’re waiting for someone else to tinker with your black box bot product.
Remember your bot is supposed to work for you, not the other way around. If you can’t contol it, it’s not your product.
A good bot speaks in your tone of voice, a bad bot is always ‘California chirpy!’
At Intercom we have banks (the old school kind), fin tech companies, surf shops, weed shops, law firms, security companies, and even a funeral arrangement service. As you might guess, they speak to their customers in… different tones.
Even the little phatic responses are important here, e.g. it’s very tempting in LLM Latency Land to hack in immediate replies like “Sounds good”, or “Awesome, I’ll start looking into that, hope you’re day is going well”, but you’ll seriously upset someone reporting bad news, or you’ll ruin the chill vibes of a weed shop. Reality is messy. You want control here.
A good bot is multi-modal, a bad bot can’t see your customer’s screenshots or photos

Sometimes a picture will literally paint a thousand words, especially in technical situations where one screenshot explains everything. Most bots can’t handle these scenarios and file a ticket somewhere on the back end, good bots reply with the description of the problem and the steps to resolve. This might seem like a nice to have, but we’ve seen our multi-modality used to do things like appraise a damaged delivery, walk through how to reset a router, and debug an error message in the product. Each case is a delightful experience, customers often don’t believe it’ll work. It works.
A good bot workflow is easy to build, a bad one is an IKEA manual directed by Christopher Nolan

Every bot needs workflows to handle specific scenarios, but managing them can get unwieldy. Generative AI simplifies all the if-this-then-that logic and lets you program your agent using English, e.g. you can give Fin a tasks saying “we need to gather the user’s order_id, email, and phone number” and Fin will do all the smart things (e.g. if the user has already offered them it won’t re-ask, it’ll only ping for what it needs, and it’ll progress as soon as it has it). You can see an example here in the tasks section
In old-school bot land that’s good ol’ boxes & arrows territory, just for one single step, add enough of them and the inception music starts playing….BWARRRRMMMMM
A good bot sees opportunities for upsell or other ways to be helpful, a bad bot craps without any follow up
The traditional bot experience ends abruptly using internal lingo, like “I am marking this conversation as closed”, and often just disappears or greys out all its buttons. A good bot will still be available and identifies opportunities for the business, for example “if the customer is happy, and is still on a free plan, see if they’d be interested in trialling a paid plan”. This is perfectly logical business behaviour, but not possible unless you’re using good software.
A good bot is something you can update as your business scales and matures, a bad bot has you going back to the vendor for every single tweak
Sadly most AI CS products are a black box of “magic” that you can’t control, interrogate, look into, or learn about. The answer to so many questions will be “talk to your forward deployed engineer” and that can be frustrating, when you’re trying to improve your support, shipping is your heartbeat – if every tweak is a roundtrip through an engineer, you’re just gonna stop iterating and start accepting weakness. Soon enough your bot is out of date and pissing people off.
In summary
If you’re hiring a AI Agent to join your support team, think about it like this:
A good bot should shoulder 50+% of the work, should do it at roughly equal CSAT to your team, and should help your customers, which will help your agents, and in turn help your business. In short, it should do a lot of work to a high standard in a way that delights your customers. This means it…
- Answers hard questions, and actually completes tasks for you end to end without your intervention
- Takes care to understands your customers, their context, their messages, their images, and doesn’t make them repeat themselves for no reason
- Is easy for you to build, control, guide, and maintain without ever talking to the developers, it’s your agent, it’s not on loan to you.
- Ultimately makes your support better, and faster for you and your customers.
You’ve probably heard a lot of the threadBois talk about the word “agentic”, ultimately this is a lot of what they’re talking about: can it do the job reliably without babysitting?
A bad bot is nearly the total opposite – it might do a lot of work, potentially more than you’d want it to, annoying a lot of customers in a way that’s a massive cost to your CS team and leaves a lot to clean up for your team and for your brand. Caveat emptor.
I hope I’ve helped you spot some of the main differences, it’s a wild place out there, lots of bad bots and a few good ones, take care!
In building and selling software, there are two main ways to do it: Sales-led, or Self-serve. There is no ‘one right way’, but over the last 15 years of Saas, the pros and cons of each became very clear. The question we face now is: which one is better for building AI products? Or is there a new way that is better than both?
We’ve been deep in this now for 2 years, let’s step through it.
Self-serve means that customers do everything themselves: learn about the product, sign up, explore the product, and succeed or fail based on whether they could get set up well, and see enough value to continue. Successful self-serve requires an excellent product experience, excellent new user experience, and excellent in-product onboarding. Self-serve is product first. Everything you experience is real running code. The big risk here is that great potential customers never get set up properly, and conclude that the product is poor (even when it isn’t!). Worst case, the customer puts something live that doesn’t work properly and they damage something: their customer engagement, their data systems, their brand.
Sales-led means that customers get help from a Sales team who are trained to help them understand the product, sign-up, get activated, see success, and continue to expand their usage. Products with a sales-led motion tend to be complex, and even confusing, but the sales team will help explain everything. Sales-led is partnership first. But because you’re not directly interacting with running code, sometimes the product is a promise more than it is real. Worst case it is jazz hands and vapourware.
Startups and naive product people (yes this was once me) have a tendency to shit on sales-led motions because they aren’t product first. But that’s myopic. Some of the best customer experiences are sales-led and partnership first. In its best form, this partnership is a deep collaboration on understanding a customer’s problems, and configuring the product to best meet their needs. Hmm, understand problem > configure solution, that sounds like product development…?
Many businesses start with a simple product, but as they add customers, those customers have feature requests, and as they add the features, the product becomes more powerful and more complex. It becomes harder to maintain a great user experience, harder for people to learn it all by themselves. This battle to scale a great user experience has tortured me for years. So many businesses start self-serve, but by necessity add Sales later.
So, how do you approach AI products?
The difference between Saas products and AI products is that Saas is predictable and AI is not. Saas products are direct manipulation, CRUD apps, where users click UI and by doing so, they create/read/update/delete data in a database. Designed well, they are easy and predictable to use because we’re all using the same components: text fields, dropdowns, buttons, etc. You don’t write an email or Slack message, hit the send button and wonder what will happen next. Even when complex, we can teach people what to do.
In contrast, AI products are unpredictable. We do wonder what will happen next when we ask Claude a hard question, or give Cursor a task. When the feedback comes, we do wonder how it worked.
In Saas, the unpredictability is with the humans involved. Are people following our policies? Are they applying their training? Can I trust my team to do a good job?
In AI products, the unpredictability has been moved to the AI layer. Is the AI following our policies? Is the AI applying its training? Can I trust AI to do a good job?
Because the unpredictability is in the AI layer, all companies building AI Agents for Customer Service have a heavy Sales-led motion. And not just Sales, but a team of people working in deep partnership with the customer and building bespoke new software together.
This is what we’re doing with Fin (our AI Agent). As well as Sales and Success, we have PMs, Designers, Data Scientists, Engineers, all building directly with customers to understand their customer data, their customer conversations, their knowledge and systems, and building a solution that works for that customer. Often we’re really changing their perceptions, they start by having a go themselves, concluding it doesn’t work very well, but then we get involved to help and advise and every metric improves.
We’re doing this with many individual customers and then using what we learn to design a product that is valuable much more generally to lots of other businesses. We’ll expand on this another time, but this deep builder partnership model is a new way to build software. Because of the unpredictable nature of AI products, and the complexity in any one business’ customer data and systems, deep partnership is required to get customers to resolution rates that match the technology’s potential: 80%+ customer queries excellently resolved by AI.
And yet. Intercom’s history was self-serve. We deeply believe in only ever marketing and selling real product. Real running code. No bullshit, no vapourware. Like many others, we added Sales-led later. In fact, during the boom years we went too hard on Sales-led, and had to rediscover our roots as a passionate product company building a product that anyone can try, anytime, without having to talk to anyone.
So Intercom has self-serve flows for everything. And we have 1000s of customers who have been using Intercom for human support successfully adding Fin without any human help from us. Despite the unpredictability, many are working it out themselves. They are getting 50%+ resolution rates through their own perseverance.
So this week we went a step further. We shipped the ability to sign-up for Fin on our competitor platforms all by yourself.
This is risky. What if many new customers try it, don’t get activated, don’t see the value, and think the product doesn’t work? What if they tell their peers? What if it damages Fin’s reputation? None of our competitors let people do this.
But we believe in the power of open software that anyone can try. We believe that people want to play with new things. And there is great energy, excitement, and value in that.
So please go have fun 🙂
“It’s only prompt-engineering if it comes from the O1 region of Cerebral Valley, everything else is just sparkling specificity”
For as long as we’ve had prompts, we’ve been told that prompt engineering will go away in the future. It’s one of those statements that I believe to be true, but also, one that gives everyone lots of false predictions. “Soon we’ll all be able to make apps with just a few sentences” we’re told. I mean, sure. Back when I was a consultant I used to remind clients “Listen, if we remove quality as a prerequisite you’ll be shocked at what we can do quickly and cheaply“.
The thing is that reality has a surprising amount of detail. Pick any app category and you’ll find there’s a shocking amount of slightly different apps. Take something as banal as fasting, i.e. the act of “not eating”, there’s hundreds of “fasting apps” and these are literally just apps that you run while you’re not eating. (granted you screenshot them for the ‘gram, but you get the point)

Similarly and more to the point there’s hundreds of to-do apps in the App Store today.

Todo is perhaps one of the domains that’s both easiest to describe, and most over-fished, but still every month another entrepreneur throws their hat in the ring. (I’m often told that Productivity apps is where good founders go to fail second time around)
Every one of these apps has an angle, the founder believes their workflow or habit should be encoded, specifically, as it’s what makes them distinctly productive. Some apps have due dates, some don’t. Some have binary states, some custom. Some are visual lists, some are Trello boards. Some nag you every day, some never bother you. Some have daily limits, and categories and tags, and some scream “No! simplicity is what’s most important”. There is a lot of depth to a surprisingly simple thing. This is all not to mention more aesthetic/superficial things like brand and UI, which can’t be discounted (we could do with some original app icons though).
So why am I saying all this? Well it comes down to this…

A lot of people confuse what they’ve heard of as “prompt engineering” with actually making important decisions regarding what you’re trying to do. Information Theory 101 says that if you want specifics in the outputs, you need them in the inputs.
So while prompting tricks (e.g., ‘Reflect on the 5–7 things you got wrong and think about how you’d make it right’—which, let’s be honest, sounds exactly like my Saturday morning after a big night out, maybe we really are all token-completers) will no doubt fade away, we will still need to know how to speak and clearly detail all our opinions and our tastes. And not to be all Rick Rubin but the premium on taste will definitely go up. In a world where everyone can get the first 70% of their app built in 20 seconds, the last 30% really really matters, so we’ll need to get really good at detailing specificities.
“Why can’t I just compile my pseudo code?”
Sidenote: This whole debacle has been an interesting flashback to my life as a university lecturer where (aside from recursion + pointers) the most common question you’d get from students was “Why can’t I just compile my pseudo code, why do I need all this public static void main String args nonsense”
Messy language choices aside, the answer is at an abstract level the exact same. The amount of information extracted from a system is limited by the amount of information fed into it, and abstracting away choices just limits the output range which ultimately limits your ability to program. The syntax forces the specificity: Print? Print where? Ah to System.out. Did you want this on a line by itself? Okay so it’s System.out.println, well why didn’t you say? End of sidenote, and thanks for staying with me 🙂
Motivating Specificity with UI
With Fin when we were building our Guidance feature, one thing we realised was that we needed to (ahem) “guide” our users into saying useful things, here’s the interface we ended up building. You’ll be shocked to hear that a lot of what we’re doing here is just forcing our users to be clear about how they want their bot to behave, by asking questions.
I suspect we’ll see that a lot in the near term, it’s not prompt-engineering, it’s about getting specificity from users who don’t read Hacker News and didn’t find the “walk me through it step by step” paper all that exciting

We had guidance in beta for a hot second when I read o1 Skill Issue a great article over all (on a similar theme) and found this visual

I suspect it won’t be long until the “text-to-app” products realise, as we did, that the best way to get specificity is to actually ask for it. What will that look like? Will it be a new type of PRD? An output from from a next gen product like ChatPRD?

It’s hard to say what this new type of product specification UI will look like.
What I can say for sure is the following: Adding friction to these products (in the form of asking for more than 1 sentence) will definitely reduce conversions, and ultimately mean less apps get created, but it will result in better apps far more likely to actually be unique, distinct, and what the user actually wanted to create. Which matters more, right? RIGHT? We’ll find out soon enough.
Every Customer Experience and Service leader knows that AI is the future, and their future. Act now, or be left behind.
We already have AI Agents that can instantly, accurately, and reliably resolve 50%+ of customer queries for many businesses. For some, we are at 70-80%+. That alone will change an industry, but this is just the beginning. AI right now is the worst it will ever be. Technology only goes in one direction.
Every Customer Service leader is busy building the next generation of their customer experience. But it’s hard. In particular, it’s hard to keep up with the pace of technology advancement, and the implications. Get your head around a latest LLMs capabilities, and there is a new one. Understand one technical concept in AI (“I know what reinforcement learning is”), and there is another one to learn (“what is distillation?”).
What we can say with confidence, is that on some timeline, AI is going to be able to answer close to all customer queries. Today, humans still do the majority, but the volume will shift to AI.
The challenge is that no one knows the exact timeline to that world. And depending on the timeline, how we redesign our customer experience will change a lot. Time it wrong, and we will have wasted huge resources designing for a world that doesn’t exist. We need to make an educated guess around two key variables:
- Technology progress. What types of queries can AI accurately answer today? Soon?
- Adoption progress. How fast/slow are people adopting, what barriers exist?
To get this right, we need to look at where we are, and what might happen next.
Where we are
History is full of examples of the technology being good enough, but the adoption being slower with some groups due to legitimate and perceived barriers. We’ve done a lot of research at Intercom to understand this, analysing millions of real customer questions, to categorise them and understand how they might be answered by AI. Broadly, there are four types of query, and the timelines are different for each one. How much of each query exists depends on the business type, but aggregated, you can think of them as 4 equal buckets of 25% of volume:
- Informational.
The answer is the same for all customers. “Do you ship to Ireland?”, “Do you have a free plan?”.
This just requires the AI to access up to date knowledge to answer. - Personalised.
The answer is different for each customer. “Where is my order?” “Why is this feature not working as expected for me?”
This requires the AI to read individual customer records to answer. - Actions.
The answer requires an Action to be taken. “We have refunded you”, “We have upgraded your subscription”.
This requires the AI to be able to read and write to customer databases, and communicate with other internal/external people/teams/businesses. - Troubleshooting.
This requires the AI to be able to understand complex customer situations, complex business logic, and complex business systems, and to be able to read, write and sometimes redesign those systems.
It requires the AI to be able to deeply communicate with other people (and at some point other AIs), to learn, and sometimes negotiate.
So where are we on our technology and adoption timelines?
Today, the best AI Agents (check out Fin), set up and configured well, can answer 100% of Informational queries. There is no technology barrier left here. The only barrier is human configuration, which requires CS teams to put in the effort to have accurate content, and a system to keep it up to date. AI is helping here too, with suggested content to close knowledge gaps, etc. Any CS team not trying to implement this is behind on the adoption timeline.
The best AI Agents can also answer close to 100% of Personalised queries. There is no technology barrier here, the barrier is putting in the effort to ensure high quality data, and high quality data integrations. Configuring this (and Actions below) is where many of the leading companies are right now. Fin is doing this for different types of businesses, from showing a customers invoice due date for Tibber, and using customers plan and device details for Firsty. It is possible to get very high numbers resolved here if you put in the effort.
The best Agents are starting to do different types of Actions. This is the current frontier on the technology timeline and we’ve Actions live with over 250 customers. The technology is there, and works for well understood and documented Actions. But it requires more human setup and configuration work, and often it requires business logic to be properly documented for the first time. This has been a key insight from our research and development with customers. Many businesses don’t actually have their processes properly documented. Often it is local knowledge passed on from person to person. And what is documented is often wrong or out of date.
Today, these business processes need to be manually documented so we can teach the AI what to do. But it won’t stay like that forever.
What might happen next
All Customer Service leaders should be planning and executing now for a world where all Informational, Personalised, and Actions queries are 100% resolved by AI. On the technology timeline, this world is already here, we are now working out how to configure things. If you are not here, you are behind on the adoption timeline.
Next, we get into an educated guessing game, and it is part of all CS leaders’ jobs to have an opinion here.
AI is likely coming that will be able to do two very powerful things:
- Work out the undocumented business logic. It will be able to analyse deep, complex systems, synthesise what it learns, and create, asking for clarifcations from people along the way.
- Work out how to connect and code integrations itself. As well as figuring out and documenting the business logic, it will take action based on it. It will write and commit code by itself, improving the underlying systems without human intervention.
This AI is going to feel like magic. This AI is going to really change your job (and many others).
- When do you think it is coming?
- And what timeline are you planning for it to arrive?
There are two timelines, you need to bet on one of them:
The Acceleration timeline: Magic AI Agents within 12-18 months
The biggest tech companies, along with the biggest AI Labs, are making huge capital investments to produce bigger and more powerful models. They wouldn’t be making these investments if they didn’t believe that the scaling laws will continue, and greater scale will give us greater power. If we take the advancements made in 2024, and extrapolate out, we might have Agents that can understand complex business logic by the end of 2025, or early 2026. The founders and leaders of the biggest AI Labs have given us these timelines.
- What does human support look like when we have AI this powerful?
- Do we still have humans talking directly to customers?
- Or do humans only talk to other internal humans (like finance, or engineering, or legal) and then instruct the AI Agent on how to proceed?
- Or does the AI Agent do all of it: talk to the customer, then ask questions in internal Slack channels, then get back to the customer.
If you think the capital investments will pay off, then you bet on this timeline, and design your customer experience appropriately, starting now.
The Slowdown timeline: No magic AI Agents for 2-3 years
AI advancement slows down. The scaling laws stop. The big capital investments don’t pay off early. We get better versions of what we have today (better reasoning models), but no breakthroughs. We still have a lot of heavy manual configuration to get high % AI resolutions. Humans with deep domain expertise and experience are the only ones who can answer complex customer queries.
Customer Service still changes a lot compared to pre-AI, but we still have very large volumes of human support.
So what should you do?
AI is advancing fast, and it’s hard to keep up. But the best Customer Service leaders are all-in, and are rebranding themselves as AI CS Leaders.
By thinking in terms of query types to automate, they are making things practical and seeing huge success. You can too:
- First do Informational (and do it now or really be left behind).
- Then do Personalised and Actions (and start now because they require deep integrations, and documenting business logic).
Find an AI Agent company you can deeply partner with. Like Intercom. We have a large, sophisticated AI team, and have been first to market with many new models and innovations. We can teach you, and we can learn together.
Whatever you do, do it now. If you don’t have an AI Agent in beta, or live, it’s getting late. There are so many success stories, so it is almost certainly the case that your competitors are getting an edge on you.
If you are on the Slowdown timeline, and we hit the Acceleration timeline, your entire role and org might be at risk of completely disappearing before you have time to react. However, by assuming the Acceleration timeline, you can not only future proof your career, you can set a new career path, by being part of the group of people who figure this out earliest, enabling incredible experiences and levels of service for your customers.
That at least, is what I am doing.